1. 介绍
本文主要翻译介绍论文 Duyu Tang, Furu Wei, Bing Qin, Nan Yang, Ting Liu, Ming Zhou. 2016. Sentiment Embeddings with Applications to Sentiment Analysis. IEEE Transactions on Knowledge and Data Engineering (TKDE)的思路
1.1 词嵌入 (2.2) 存在的问题
基于上下文的嵌入学习算法最严重的问题是它们只模拟单词的上下文而忽略了文本的情感信息。 结果,具有相反极性的单词,例如 good和 bad ,被映射到嵌入空间中临近的词向量。 这对于诸如pos-tagging之类的一些任务是有意义的,因为这两个词具有相似的用法和语法角色。 然而,这对情绪分析是不利的,因为 good和 bad具有相反的情绪极性标签。
1.2 论文主要贡献
-
论文提出了学习情感特定的词嵌入。我们保留单词上下文的有效性并利用文本的情感来学习更强大的连续单词表示。通过捕获上下文和情感水平信息,嵌入空间中的最近向量不仅在语义上相似,而且具有相同的情感极性,使得它能够将good和bad分离到频谱的相对端。
-
我们开发了许多具有测量损失函数的神经网络来学习情感嵌入。 我们从正面和负面表情符号的推文中学习情感嵌入作为远程监控的语料库而无需任何手动注释。
-
我们通过将情感嵌入应用于三个情感分析任务来验证情感嵌入的有效性。 经验实验结果表明,情感嵌入在这些任务的几个基准数据集上优于基于上下文的嵌入。
2. 介绍词嵌入的背景
词的表示方法:
- one-hot vector
- word embedding
2.1 one-hot vector
one-hot vector 定义:
事先构建一个词汇表(所有句子中出现的词构成词汇表,词汇表中的词不重复),one-hot vector为长度为词汇表长度,词汇表中出现该词的位置为1,其他均为0的向量
例如:
有包含5个词的词汇表如下:
词汇表 = [‘生活’, ‘很’, ‘美好’, ‘糟糕’, ‘我’]
有文本如下:
生活很美好
优于中文句子不像英文句子那样词之间有空格,所以中文句子需要进行分词处理,文本分词处理结果如下:
生活/很/美好
对照词汇表转成one-hot vector 格式:
生活 =
[10000]T
很 =
[01000]T
美好 =
[00100]T
2.2 词嵌入(word embedding)
one-hot vector缺点:
词嵌入(word embedding):
现有的嵌入学习算法主要基于分布式假设,该假设表明类似情境中的单词具有相似的含义。(即一个词的含义可以由它周边的单词决定)
词嵌入具体学习方法[3.2.1, 3.2.2]
直观理解:
词嵌入可以理解为由一系列的属性来表示某个词
例如,“手机”的表示为[电子产品的事实, 包括电池和屏幕, 用于与他人聊天, …], 这种表示方式纬度(自定义的属性个数)比one-hot vector的纬度(词汇表长度) 低,同时可以发现相似词之间的关联(如“苹果”和“梨子”,它们的属性就是否相似,如都是水果,都…)。
3. 介绍学习情绪嵌入的方法
3.1 符号定义
-
wi 代表句子中的第i个词
-
hi 是
wi 所在的句子的上下文单词
-
ei 是
wi的词嵌入
- 对神经网络每一层,
Olayer 代表的它们的输出向量
3.2 基于上下文的模型
主流的词嵌入学习算法是基于分布假设,其表明词的表示可以通过它们的上下文来反映。
3.2.1 Prediction Model
思路:
给定目标词
wi及其上下文单词
hi,基于
hi来预测
wi
论文
hi定义:
hi = {
wi−c,wi−c+1,...,wi−1,wi+1,...,wi+c−1,wi+c},即
wi前后c个词
网络结构:
lookup→linear→hTanh→linear→softmax
即设计一个神经网络,该网络输入为
hi输出为
wi的概率,
p(wi∣hi)
以下为网络结构的详细定义、解释:
hTanh,linear, softmax定义:略
lookup层:
- Lookup层包含一个lookup 表
LT∈Rd∗∣V∣, d是词向量(词嵌入学习得倒的向量,也称为词向量)的维数,|V|是one-hot vector[2.1]中的词汇表的长度,LT随机初始化赋值,其内部具体值可由训练得到。
- one-hot vector
∈R∣V∣∗1
-
wi 初始用one-hot vector表示
wi经过Lookup层转化为词向量:
ei =
(LT∗wi)T
∈R1∗d
目标词
wi的上下文单词
hi转化为词向量:
{
wi−c,wi−c+1,...,wi−1,wi+1,...,wi+c−1,wi+c}
→lookup{
ei−c,ei−c+1,...,ei−1,ei+1,...,ei+c−1,ei+c}
lookup层输出:
Olookup =
LT∗hi = {
ei−c,ei−c+1,...,ei−1,ei+1,...,ei+c−1,ei+c}
∈Rd∗2c
优化训练:
给定 (
wi ,
hi ) 优化目标是最大化
p(wi∣hi)
然而,直接预测
p(wi∣hi)的概率是耗时的,因为
softmaxi=∑i=0mexp(zi)exp(zi))
m为词汇表大小,通常为几十万,而且
Osoftmax是长度为m的向量,向量中的每个元素都要计算
softmaxi
改进:
为了加速训练过程,我们使用噪声对比估计,并通过逻辑回归将“上下文预测”问题转移到将词语对作为真实案例或人工噪声进行区分。即给定
hi和
wi以及噪声(词汇表中任一词),判断该样本来自真实数据的概率
p(D∣w,θ)
p(D∣w,θ)=exp(fθ(wi,hi))+k∗exp(fθ(wn,hi))exp(fθ(wi,hi))
-
wn为人工噪声,从词汇表中随机选的一个词
-
fθ(w,h) :
lookup→linear→hTanh→linear
损失函数:
losscPred=−w∈T∑log(p(D∣w,θ))
T 为训练语料库
3.2.2 ranking model
losscRank=(wi,hi)∈T∑max(0,1−fθ(wi,hi)+fθ(wn,hi))
T 为训练语料库
3.3 基于情感的模型
我们提出了将句子情感极性编码进情感嵌入的方法。 我们描述了两个神经网络,包括预测模型和排序模型,以考虑句子的情感。
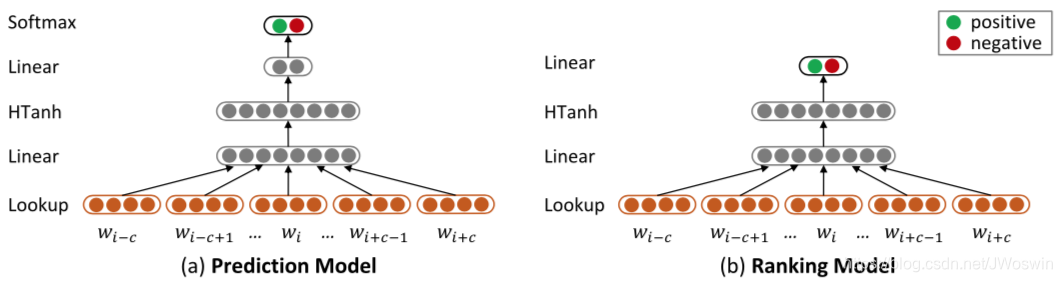
图2. 两个神经网络,用于模拟学习情绪嵌入的句子的情感极性。
3.3.1 Prediction Model
预测模型的基本思想是将情绪预测作为多类分类任务。 它通过将字嵌入视为参数来预测单词序列的正/负分类概率。 特别地,给定可变大小的句子,我们在句子上滑动单词的固定窗口,并基于窗口包含的词嵌入来预测每个窗口的情感极性。 如果窗口大小很大,这个假设适用于推文,因为推文通常很短,并且情绪很普遍。 但是,对于经常使用情绪转换指标(例如,否定和对比)的文件级审查文本,这可能是不合适的。
网络结构(图2.a):
lookup→linear→hTanh→linear→softmax
输入:
{
wi−c,wi−c+1,...,wi−1,wi,wi+1,...,wi+c−1,wi+c},即
wi 和 其上下文
hi的组合
输出:
[ 情感倾向是积极的概率,情感倾向是消极的概率 ]
真实的label:
窗口大小取大些,可把整个句子的情感当其片段真实的情感
损失函数:
我们使用真实情绪分布和预测分布之间的交叉熵误差作为softmax层的损失函数。
losssPred=−t∑Tk=0,1∑fkg(t)∗log(fkpred(t))
- T:训练语料库
-
fg(t):模型输出
3.3.2 Ranking Model
排名模型的基本思想是,如果输入的极性是正的,预测的正分数
frankpos应高于负分数
frankneg如果输入的极性是正的,预测的负分数应高于正分数。
网络结构(图2.b):
lookup→linear→hTanh→linear
输出:
[frankpos,frankneg]
- 如果
frankpos>frankneg,情感极性为正
- 如果
frankpos<frankneg,情感极性为负
损失函数:
losssRank=t∑Tmax(0,1−δs(t)fposrank+δs(t)fnegrank)
- t :输入
- T 为训练语料库
-
frankpos :正分数
-
frankneg :负分数
-
δs(t)指示函数,反映句子真实的情绪极性(正面或负面)
δs(t)={1,fg(t)=[1,0]−1,fg(t)=[0,1],
fg(t),代表模型输出
3.4 Modeling Sentiment of Sentences and Contexts of Words
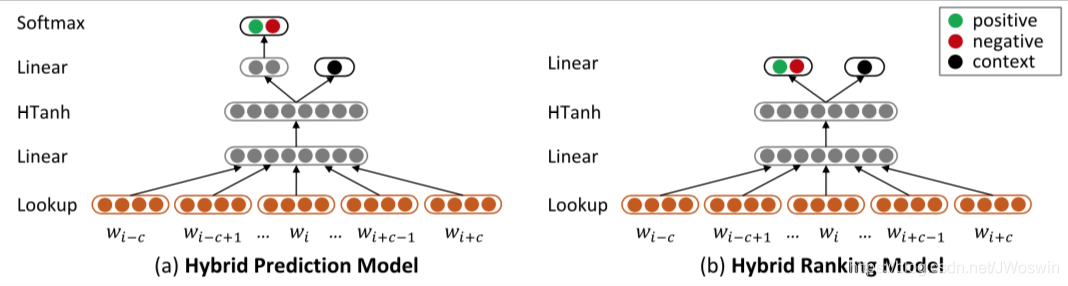
图3. 混合模型
3.4.1 Hybrid Prediction Model
我们结合基于上下文的预测模型(第3.2.1节)和基于情感的预测模型(第3.3.1节)得到混合预测模型(图3. a)。
损失函数:
losshyPred=αpred∗losssPred+(1−αpred)∗losscPred
0≤αpred≤1
3.4.2 Hybrid Ranking Model
损失函数:
losshyRank=αrank∗losssRank+(1−αrank)∗losscRank
0≤αrank≤1
3.5 Modeling Lexical Level Information
我们考查词汇级信息以增强这部分中的感知嵌入。 我们使用两种词汇级别的信息,即词 - 词联想和词 - 情感联想。 我们开发了两个正则化器,将它们自然地融入上述基于情感,基于上下文和混合神经模型中。
3.5.1 Integrating Word-Word Association
我们在这部分模拟了单词 - 单词关联,并考虑到来自同一簇的单词在嵌入空间中应该彼此接近。
给定同一群集中的两个单词,我们的目标是最小化它们在嵌入空间中的距离。 我们将其公式化为:
lossww=λww(w,v)∈E∑∣∣ew−ev∣∣22
- E:字簇集合
-
ew和
ev 分别是词w,v的嵌入格式
上述损失函数可以自然地与第3.2,3.3和3.4节中介绍的嵌入学习模型集成为正则化器。
3.5.2 Integrating Word-Sentiment Association
我们通过直接预测关于每个单词的嵌入值的每个单词的情感极性作为特征来整合单词情感关联。 因此,优化目标是最小化负和条件概率:
lossws=−λws(w∈Ps∑Pposw+w∈Ns∑Pnegw)
-
Pposw,
Pnegw分别表示表示将单词分类为正面和负面的条件概率
-
Ps和
Ns分别是具有正极性和负极性的单词集合。
文献
[1] Duyu Tang, Furu Wei, Bing Qin, Nan Yang, Ting Liu, Ming Zhou. 2016. Sentiment Embeddings with Applications to Sentiment Analysis. IEEE Transactions on Knowledge and Data Engineering (TKDE).