Sentiment Analysis for Software Engineering: How Far Can We Go?
1. 介绍
已有的情感分类工具不是用来分析软件项目中文本相关的情感。从本质上说,没有银弹,只有可能是在软工相关的数据集上进行了定制训练。
近年来使用定制化的情感分析工具在软工数据集上工作。
最常用的:
SentiStrength:检视每个句子中的每个词,给每个词一个得分然后加起来求得句子的情感。
作者识图通过Stack Overflow上对于软件库的众包只是来推荐合适的软件库,一个重要的组件就是一个可靠的情感分析工具。需要使用Stack Overflow上的内容定制情感分类工具,使用效果最好的递归神经网络模型,能够分析句子组成的语法结构。实际得到的结果并不好。
于是作者使用已有的情感分析工具在不同的数据集上进行情感分析,结果显示待测的分类工具没有一个能够在他们构建的Stack Overflow的数据集上提供可靠且精确的结果。
本文的主要目的是说明尽管在软工的情感分析上投入了大量的经理,但是在使用这些工具的过程中依然存在许多问题。
2. 相关工作
2.1
已有的情感分析工具:
SentiStrengthNLTKStanford CoreNLPEmoTxt
2.2
- 有更多分布团队的项目情感的积极性更高;
- 周一写得评论注释倾向于表达负面情绪;
- 周二表达的情绪最负面;
- 560k JIRA的评论显示积极正面的评论能够帮助issue的修复;
- CI中表达的情感可能影响构建的结果;
- app评价的情感极性会影响手机应用的演化;
- 使用ASUM技术从app评论中提取表现用户对于app的看法;
- 使用NB分类器给app的用户评论情感分类;
- 使用细粒度的模型分析开发团队的愤怒级别;
- 讨论安全问题时,开发者的情感最负面;
- OSS项目开发者不活跃,当他们在issue tacker中表达强烈的积极或负面情绪。
2.3
没有研究关心情感分类的准确性。Tourani使用SentiStrength在Tomcat和Ant两个项目上从开发者和用户邮件中提取情感信息。效果精确度很差,积极语句29.56%,消极语句13.10%。Jongeling使用SentiStrength、NLTK、Stanford CoreNLP和AlchemyAPI在Murgia研究的数据集上进行测试。发现没有一个工具能够提供令人满意的结果,不同工具间存在巨大分歧。
普通情感分析工具在SE文本上效果不佳,Islam和Zibran基于SentiStrength开发了SentiStrength-SE解决SE领域的情感分级问题。
3 方法
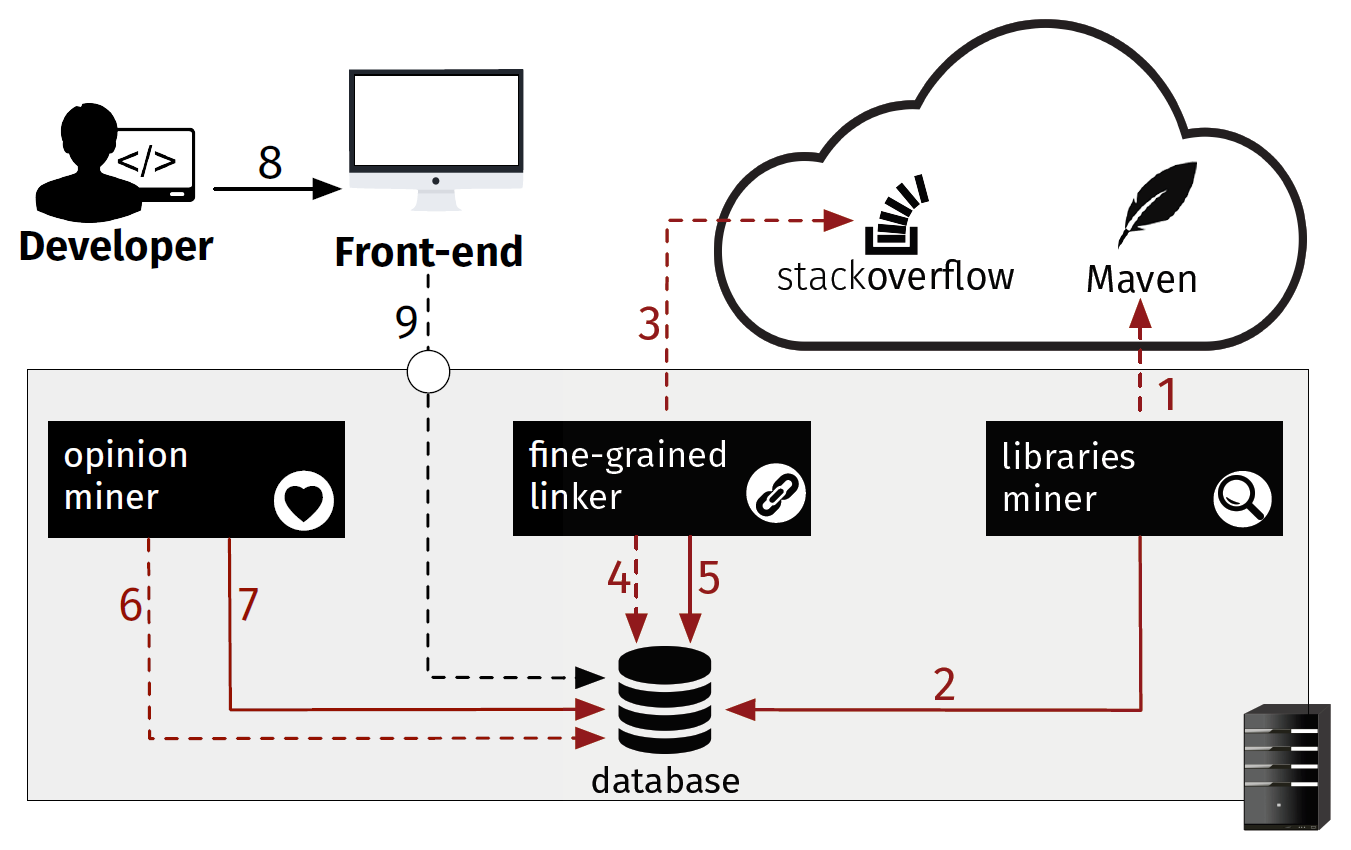
流程:
1&2. 从Maven中收集Java项目的 i) 项目名; ii) 描述; iii) 相关的jar包; iv) 协议; v) 使用客户的数量和列表,保存到数据库中;
3&4&5. 从Stack Overflow上爬取相关描述和评论存储到数据库中;
6&7. 进行情感分类,储存到数据库中;
8&9. 用户通过前端输入对于库的描述和非功能性要求(性能,安全,社区支持等),后端返回最适合的库的列表。
3.1 从软工数据集中挖掘情感
分析每个单词的情感是不够的,需要从构建语句的语法结构层面分析其情感。需要在组成句子的语法结构的每个节点上都知道其情感极性。
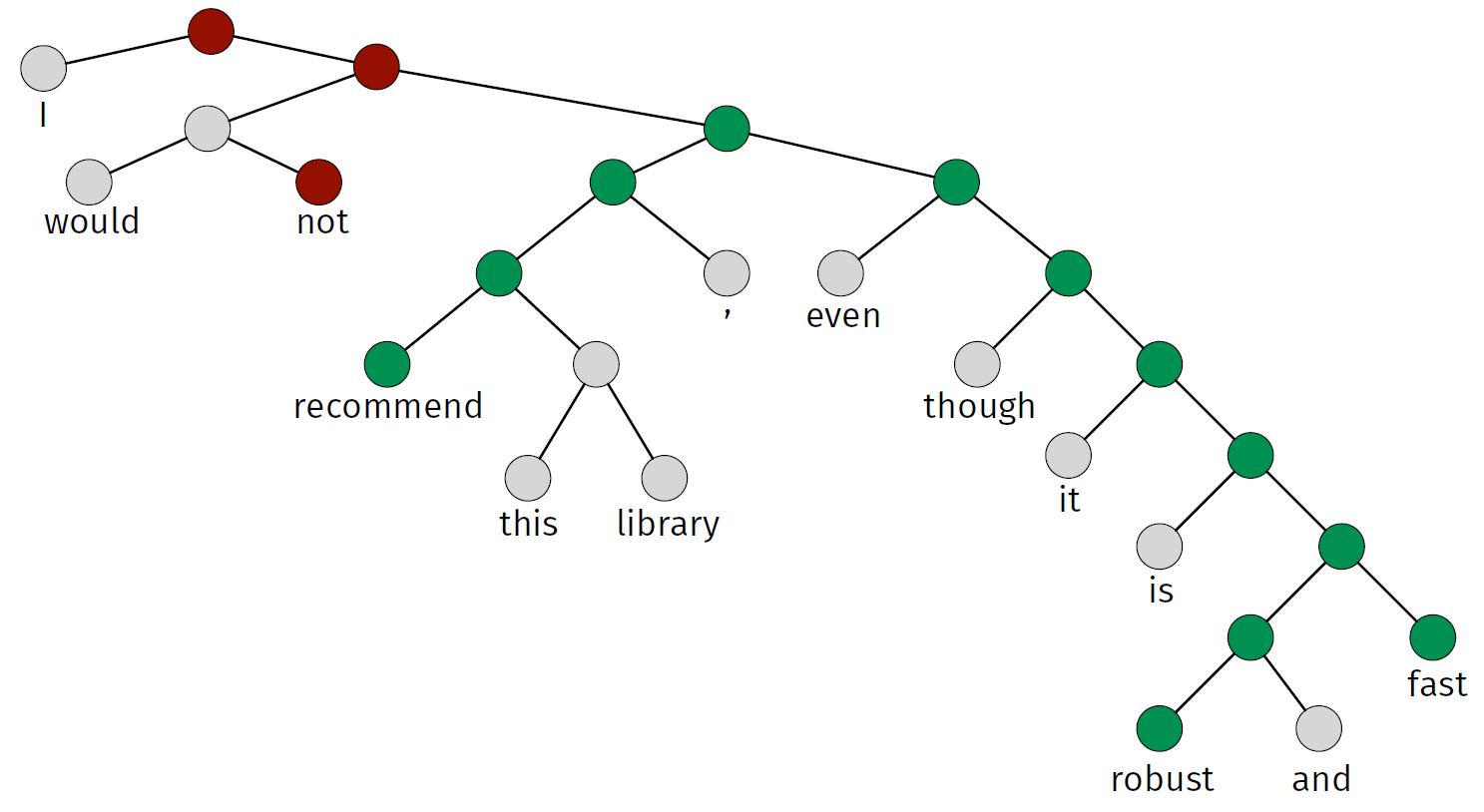
基于这个原因,实验使用Stanford CoreNLP工具进行情感分类,但是和之前研究表明在电影评论数据集上训练的情感分类模型用在软工问题上是没有意义的。
使用Stanford CoreNLP在276,629个讨论中抽取了5,073,452个句子。随机选择其中1500句进行人工标注。
花费90小时进行人工标注,共标注了39,924个节点。解决了279个冲突句子的分类,2,199个冲突的节点。人工解决123个强冲突节点(两个评价者打分差>2),其余2,076个取平均。
4 不好的结果
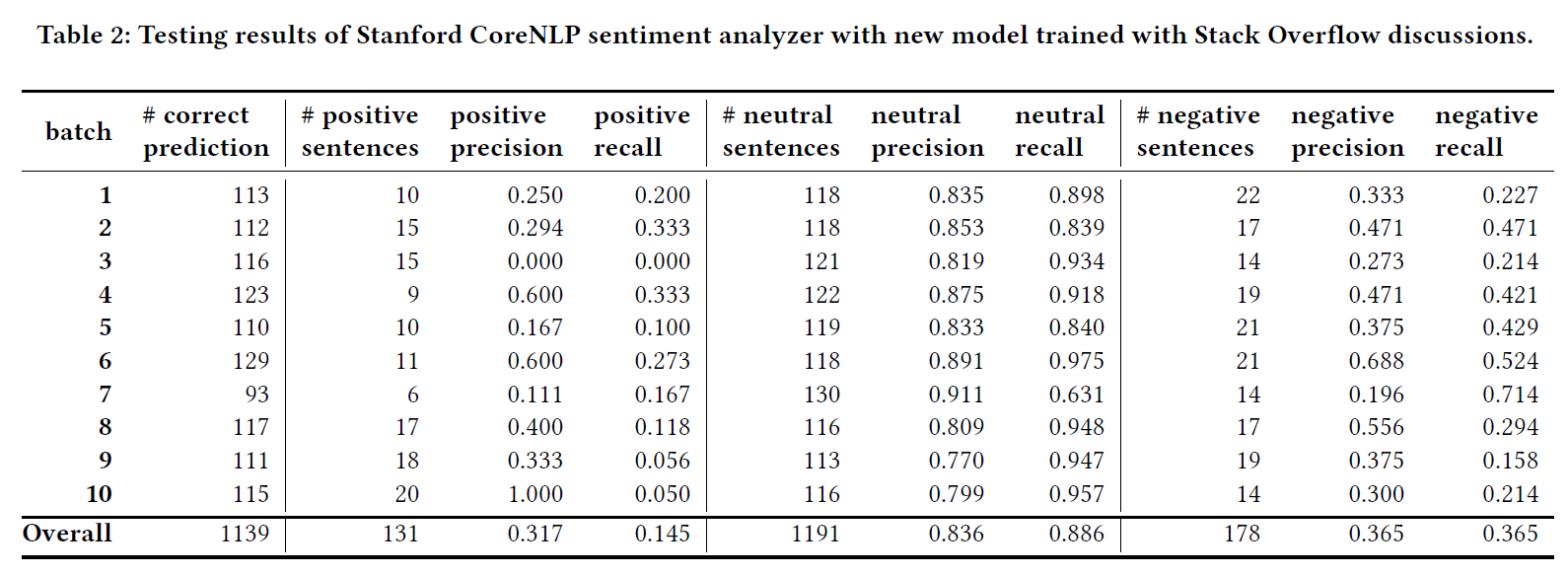
positive和negative的precision和recall都低于40%。
5 在SE上评价情感分析工具
5.1
RQ1:目前最好的情感分析工具和Stanford CoreNLP SO相比效果如何?
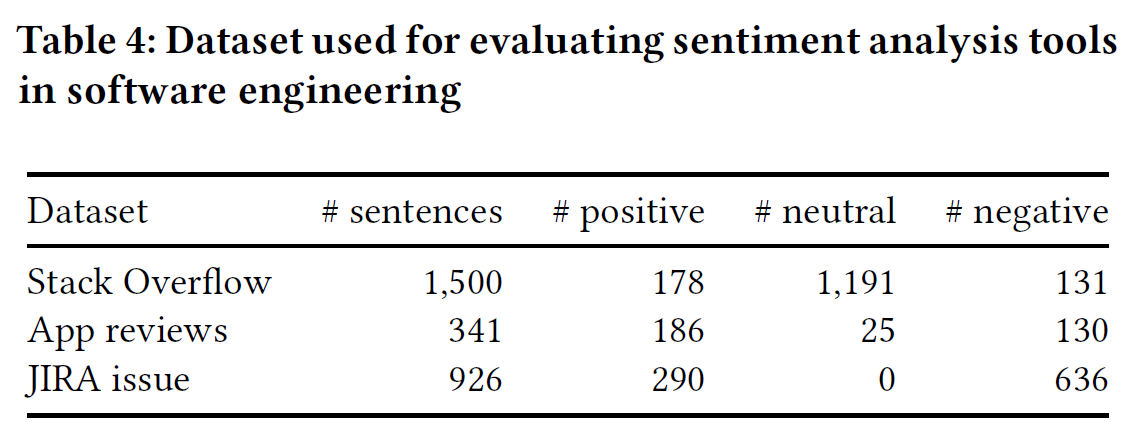
RO2:不同的软件相关数据集影响语法分析工具的效果吗? i) QA论坛,如Stack Overflow上的讨论; ii) app市场的评论; iii) issue tracker,JIRA issue评论。
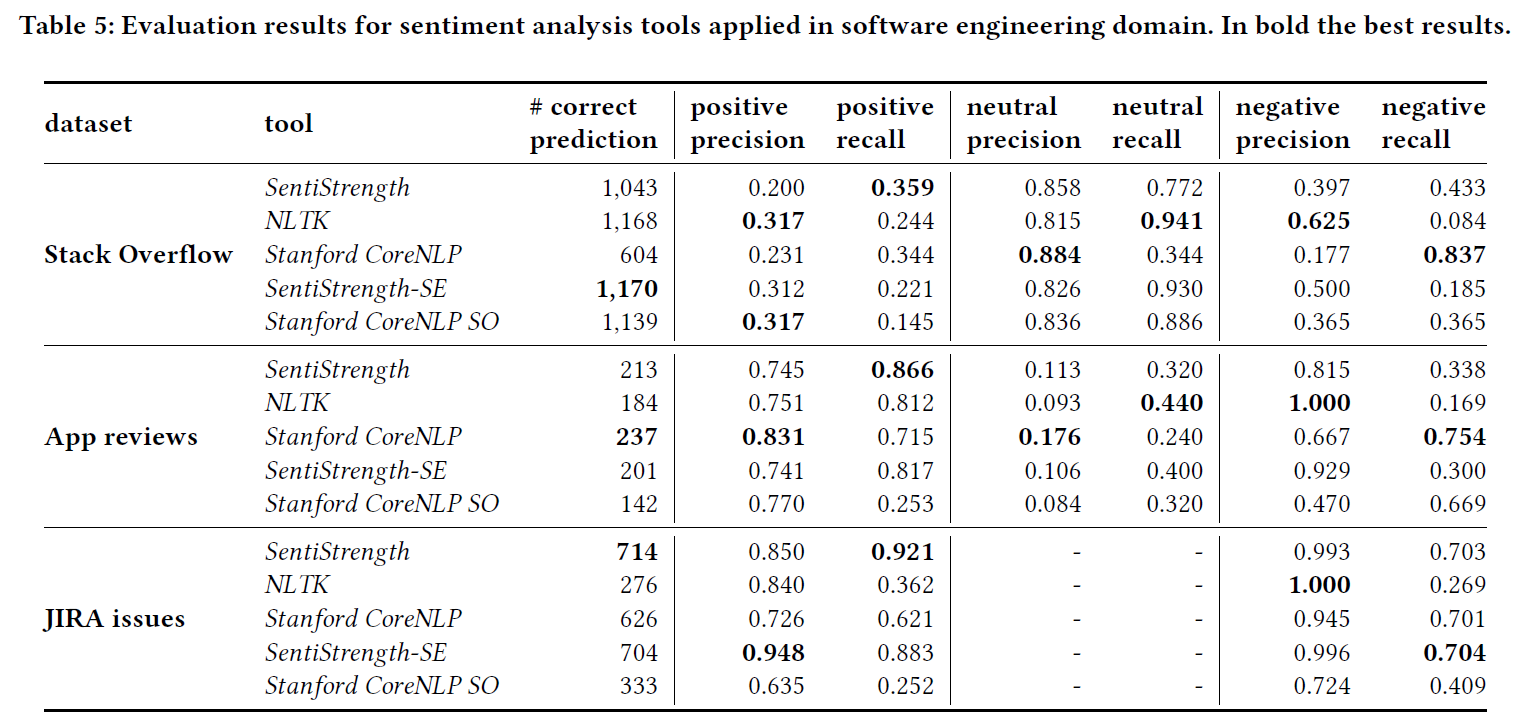
5.2
在预测positive和negative的效果很好,但是预测neutral情感的效果不理想。所以只包含少量neutral数据点的数据集会引入大量偏差。
6 效度威胁
7 习得经验
- 至今没有工具能够很好的解决软工问题上的情感分类问题;
- 需要依据应用场景重新练模型,但是没有银弹;
- 在应用上的情感分析更简单。因为应用评论大多清晰地包含了用户的态度;
- 人工打标签依然存在分歧,不能指望机器达到100%正确率;
- 情感分类工具只报告positive或negative是不够的。
8 结论
- 机器学习,甚至更先进的方法,依然是黑盒,不能预估黑盒里会发生什么;
- 尽管可以反驳在
Stack Overflow这种QA论坛是交流技术而非表达情感,但是文中评价的情感分类方法在另外两个数据及上依然表现不尽如人意,从方法的内在上存在问题; - we are not dismissing opinion mining in software engineering as impractical, but rather as not mature enough yet,不是说在软工上做情感挖掘不实际,而是这个研究方向仍不成熟。