深度学习论文阅读目标检测篇(七)中英对照版:YOLOv4《Optimal Speed and Accuracy of Object Detection》
- Abstract 摘要
- 1. Introduction 引言
- 2. Related work 相关工作
- 3. Methodology 方法
- 4. Experiments 实验
-
- 4.1. Experimental setup 实验设置
- 4.2. Influence of different features on Classifier training 不同技巧对分类器训练的影响
- 4.3 Influence of different features on Detector training 不同技巧对检测训练的影响
- 4.4 Influence of different backbones and pre-trained weightings on Detector training 不同 backbone 和预训练权重对检测器训练的影响
- 4.5 Influence of different mini-batch size on Detector training 不同的 mini-batch size 对检测器训练的影响
- 5. Results 结果
- 6. Conclusions 结论

Abstract 摘要
有大量的技巧可以提高卷积神经网络(CNN)的精度。需要在大 数据集下对这种技巧的组合进行实际测试,并需要对结果进行理论论 证。某些技巧仅在某些模型上使用和专门针对某些问题,或只针对小 规模的数据集;而一些技巧,如批处理归一化、残差连接等,适用于 大多数的模型、任务和数据集。我们假设这种通用的技巧包括加权残 差连接(Weighted-Residual-Connection,WRC)、跨小型批量连接 (Cross-Stage-Partial-connection,CSP)、Cross mini-Batch Normalization (CmBN)、自对抗训练(Self-adversarial-training,SAT)和 Mish 激 活函数。我们在本文中使用这些新的技巧:WRC、CSP、CmBN、SAT, Mish-activation,Mosaic data augmentation、CmBN、DropBlock 正则 化和 CIoU 损失,以及这些技巧的组合,在 MS COCO 数据集达到目 前最好的结果:43.5%的 AP(65.7% AP50),在 Tesla V100 上速度达 到约 65FPS。源码见:GitHub
1. Introduction 引言
大多数基于 CNN 的目标检测器基本上都仅适用于推荐系统。例 如:通过城市摄像头寻找免费停车位,它由精确的慢速模型完成,而 汽车碰撞警报需要由快速、低精度模型完成。改善实时目标检测器的 精度,使其能够不仅可以用于提示生成推荐系统,也可以用于独立的 流程管理和减少人力投入。传统 GPU 使得目标检测可以以实惠的价 格运行。最准确的现代神经网络不是实时运行的,需要大量的训练的 GPU 与大的 mini bacth size。我们通过创建一个 CNN 来解决这样的 问题,在传统的 GPU 上进行实时操作,而对于这些训练只需要一个 传统的 GPU。
这研究的主要目的是设计一个可以在生产环境快速运行的目标 检测器,并且进行并行计算优化,而不是较低的计算量理论指标 (BFLOP)。我们希望所设计的目标易于训练和使用。例如,任何使 用传统 GPU 进行训练和测试的人都可以实现实时、高质量、有说服 力的目标检测结果,YOLOv4 的结果如图 1 所示。现将我们的成果总 结如下:
- 我们构建了一个快速、强大的模型,这使得大家都可以使用 1080 Ti 或 2080 Ti GPU 来训练一个超快、准确的目标检测器。
- 我们验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法 在目标检测训练期间的影响。
- 我们修改了最先进的方法,使其变得更高效并且适合单 GPU 训练,包括 CBN[89]、PAN[49]、SAM[85]等。

2. Related work 相关工作
2.1. Object detection models 目标检测模型
现代目标检测器通常由两部分组成:ImageNet 上预训练的 backbone 和用于预测类别和 BBOX 的检测器 head。对于那些在 GPU 平台上运行的探测器,其 backbone 可以是 VGG[68],ResNet[26]、 ResNeXt[86]、或 DenseNet [30]。对于那些运行在 CPU 平台上的检测 器形式,它们的 backbone 可以是 SqueezeNet[31]、MobileNet[28,66, 27,74],或 ShuffleNet[97,53]。至于 head 部分,它通常被分两类: 即一阶段(one-stage)和两阶段(two-stage)的目标检测器。最有代 表性的两阶段检测器是 R-CNN[19]系列模型,包括 Fast R-CNN[18]、 Faster R-CNN[64]、R-FCN[9]和 Libra R-CNN[58]。也可以在两阶段目 标检测器中不用 anchor 的目标检测器,如 RepPoints[87]。对于一阶 段检测器来说,最代表性的有 YOLO[61、62、63]、SSD[50]和 RetinaNet[45]。近几年来,也开发了许多不使用 anchor 的一阶段目标 检测器。这类检测器有 CenterNet[13]、CornerNet[37,38]、FCOS[78] 等。近年来开发检测器往往会在 backbone 和 head 之间插入一些层, 这些层用于收集不同阶段的特征图。我们可以称它为检测器的 neck。 通常情况下 neck 是由几个自下而上或自上而下的通路(paths)组成。 具有这种结构的网络包括 Feature Pyramid Network (FPN)[44]、Path Aggregation(PAN)[49]、BiFPN[77]和 NAS-FPN[17]。除上述模型外, 有的研究者注重于直接重新构建 backbone(DetNet[43]、DetNAS[7]) 或重新构建整个模型(SpineNet[12]、HitDetector[20]),并用于目标检 测任务。
总结起来,通常目标检测模型由以下一些部分组成:




2.2. Bag of freebies
通常情况下,传统的目标检测器的训练都是在线下进行的。因此, 研究者们总是喜欢利用纯下训练的好处而研究更好的训练方法,使得 目标检测器在不增加测试成本的情况下达到更好的精度。我们将这些 只需改变训练策略或只增加训练成本的方法称为 bag of freebies。目 标检测经常采用并符合这个定义的就是数据增强。数据增强的目的是 增加输入图像的多样性,从而使设计的目标检测模型对来自不同环境 的图片具有较高的鲁棒性。比如 photometric distortions 和 geometric distortions 是两种常用的数据增强方法,它们对检测任务肯定是有好 处的。使用 photometric distortions 时,我们调整图像的亮度、对比度、 色调、饱和度和噪声。使用 geometric distortions 时,我们对图像添加 随机缩放、裁剪、翻转和旋转。
上面提到的数据增强方法都是逐像素的调整,以及调整区域的所 有原始像素信息会被保留下来。此外,一些从事数据增强工作的研究 者把重点放在了模拟目标遮挡问题上。他们在图像分类和目标检测取 得了好的结果。例如,随机擦除[100]和 CutOut[11]可以随机的选取图 像中的矩形区域,并填充随机值或零的互补值。至于 hide-and-seek [69] 和 grid mask [6],他们随机或均匀地选择图像中的多个矩形区域,并 将其全部像素值替换为零值。如果将类似的概念应用到特征图中,就 是 DropOut[71]、DropConnect[80]和 DropBlock[16]方法。此外,有研 究者提出了将多张图像放在一起从而实现数据增强的方法。例如, MixUp[92]将两张图像以不同系数的进行相乘和叠加,并根据叠加比 例调整标签。对于 CutMix[91],它通过覆盖裁剪后的图像到其他图像 的矩形区域,并根据混合区的大小调整标签。除了以上提到的方法, 网络迁移 GAN[15]也常常用于数据增强,这种方法可以有效地减少 CNN 学习到的纹理偏差。
与上面提出的各种方法不同,其他的一些 Bag of freebies 方法是 专门解决可能有偏差的数据集中语义分布问题。在处理语义分布偏差 的问题上,有一个很重要的问题是不同类别之间的数据不平衡,而两 阶段检测器处理这个问题通常是通过 hard negative example mining [72] 或 online hard example mining [67]。但 example mining method 不适用 于一阶段的目标检测器,因为这种检测器属于密集预测架构。因此, Linet al.[45]提出了 focal loss 解决数据不平衡问题。另一个很重要的 问题是,one-hot 编码很难表达出类与类之间关联程度。这种表示方 法(one-hot)通常在打标签的时候使用。在[73]中提出的 label smoothing 方案是将硬标签转化为软标签进行训练,可以使模型更具 有鲁棒性。为了获得更好的软标签,Islam 等[33]引入知识蒸馏的概念 并用于设计标签细化网络。
最后一个 bag of freebies 是边界框(BBox)回归的目标函数。检测 器通常使用 MSE 损失函数对 BBOX 的中心点和宽高进行回归,例如 {xcenter, ycenter, w, h},或者是回归预测左上角的点和右下角的点,例如 {xtop_left, ytop_left, xbottom_right, ybottom_right}。对于基于 anchor 的方法,它会 估算出对应的偏移量,例如{ x center offset , y center offset , w offset , h offset } and { x top left offset , y top left offset , x bottom right offset , y bottom right offset }。但是,如果要直接估计 BBOX 每个点的坐标值, 就要将这些点作为独立变量,但实际上未考虑对象本身的完整性。为 了使这一问题得到更好的解决,一些研究人员最近提出了 IoU 损失 [90],其考虑了预测 BBox 面积和 ground truth BBox 面积的覆盖度。 IoU 损失计算过程将通过计算预测值与真实值的 IoU,然后将生成的 结果连接成一个整体代码,最终通过计算获得 BBox 的四个坐标值。 因为 IOU 是一个与尺度无关的表示,它可以解决当传统方法计算{x, y,w,h}的 l1 或 l2 损失时,损失会随着尺度增加而增大的问题。最 近,一些研究人员不断改善 IOU 损失。例如 GIoU 损失[65]除覆盖面 积也考虑物体的形状和方向。他们建议找到能同时覆盖预测 BBOX 和 真实值 BBox 的最小面积 BBOX,并使用这个 BBox 作为分母并取代 原先 IoU 损失的分母。至于 DIoU 损失[99],它另外还包括考虑物体 中心的距离,另一方面 CIoU 损失[99]同时考虑到重叠面积和中心点 之间的距离以及长宽比。CIoU 可以在 BBox 回归问题上获得了更好 的收敛速度和精度。
2.3. Bag of specials
对于那些只会增加少量的推理成本的插入模块和后期处理方法, 但可显著提高目标检测的准确性,我们称其为“Bag of specials”。一 般来说,这些插入模块是用来增强模型的某些属性的,如扩大感受野、 引入注意力机制或增强特征整合能力等,而后处理是一种筛选模型预 测结果方法。
可用于扩大感受野的常用模块有 SPP[25]、ASPP[5]和 RFB[47]。 SPP 模块源于 Spatial Pyramid Match(SPM)[39],而 SPMs 的原始方 法是将特征图分割成几个 d×d 相等大小的块,其中 d 可以是 {1,2,3,…},从而形成空间金字塔,然后提取 bag-of-word 特征。SPP 将 SPM 集成到 CNN 并使用 max-pooling 操作而不是 bag-of-word 运 算。由于 He 等人提出的 SPP 模块[25]会输出一维特征向量,因此不 可能应用于全卷积网络(FCN)中。因此,在 YOLOv3 的设计[63]中, Redmon 和 Farhadi 改进了 YOLOv3 的设计,将 SPP 模块修改为融合 k×k 池化核的最大池化输出,其中 k = {1,5,9,13},步长等于 1。在这 种设计下,一个相对较大的 k×k 有效地增加了 backbone 的感受野。 增加了改进版的 SPP 模块后,YOLOv3-608 在 MS COCO 上 AP50 提 升了 2.7%,但要付出 0.5%的额外计算成本。ASPP[5]模块和改进后的 SPP 模块在操作上的区别是主要由原来的步长 1、核大小为 k×k 的 最大池化到几个 3×3 核的最大池化,缩放比例为 k,步长 1 的空洞 卷积。RFB 模块是使用几个 k×k 核的空洞卷积,空洞率为 k,步长 为 1 以得到比 ASPP 更全面的空间覆盖率。RFB[47]只需额外增加 7% 推理时间却在 MS COCO 上将 SSD 的 AP50提升 5.7%。
在目标检测中经常使用的注意力模块,通常分为 channel-wise 注 意力和point-wise注意力,具有代表性的两个模型分别是Squeeze-andExcitation (SE) [29]和 Spatial Attention Module (SAM) [85]。虽然 SE 模 块可以将 ResNet50 在 ImageNet 图像分类任务上的 top-1 准确率提升 1%,而计算量仅仅增加 2%,但是在 GPU 上推理时间通常会增加 10% 左右,所以更适合用于移动端设备。但对于 SAM,它只需要额外 0.1% 的计算量就可以将 ResNet50-SE 在 ImageNet 图像分类任务上的 Top1 精度提高 0.5%。最重要的是,它完全不会影响 GPU 上推理的速度。
在特征融合方面,早期的做法是使用快捷连接(skip connection) [51]或超列(hyper-column)[22]将低级物理特征融合成高级语义特征。 由于 FPN 等多尺度预测方法越来越流行,许多集成了不同的特征金 字塔特征的轻量级模块被提了出来。这类模块包括 SFAM[98]、 ASFF[48]和 BiFPN[77]。SFAM 的主要思想是利用 SE 模块对多尺度 特征图在通道方向上重新加权拼接特征图。至于 ASFF,它用 softmax 进行 point-wise 水平的重新加权,然后在不同尺度添加特征图。在 BiFPN 中,多输入加权残差连接进行多尺度水平的重新加权,然后在 不同尺度上添加特征图。
在深度学习的研究中,有人注重于寻找好的激活函数。一个好的 激活函数可以使梯度更有效地传播,同时也不会造成太多的额外计算 成本。2010 年,Nair 和 Hinton [56]提出了 ReLU 来实质性地解决梯度 消失的问题,这也是 tanh 和 sigmoid 激活函数经常遇到的问题。随后 便提出了 LReLU[54]、PReLU[24]、ReLU6[28]、Scaled Exponential Linear Unit (SELU)[35]、Swish[59]、hard-Swish[27]和 Mish[55]等,这 些激活函数也用来解决梯度消失问题的。LReLU 和 PReLU 的主要目 的是为了解决当 ReLU 输出小于零时梯度为零的问题。至于 ReLU6 和 Hard-Swish,它们是专为量化网络(quantization networks)设计。 对于自归一化的神经网络,SELU激活函数的提出满足了这一目的。 需要注意的是,Swish 和 Mish 都是连续可微的激活函数。
基于深度学习的目标检测中常用的后处理方法是 NMS(非极大 值抑制),它可以用于过滤那些对相同目标预测较差的边界框,并且 只保留响应较高的候选边界框。NMS 努力改进的方式与目标函数的 优化方法一致。NMS 原始方法没有考虑背景信息,所以 Girshick 等 人[19]在 R-CNN 中增加了分类置信度分数作为参考,并根据信任分 数的顺序,从高分到低分的顺序执行贪婪 NMS。至于 soft NMS[1], 它关注了这样一个问题,即目标遮挡可能会导致基于 IoU 分数的贪婪 NMS 的置信度得分降低。基于 DIoU 的 NMS[99]的开发者思路是在 soft NMS 基础上将中心点距离信息增加到 BBox 筛选的过程中。值得 注意的是,由于上述后处理方法都没有直接涉及指提取特征图,所以 在不使用 anchor 的方法后续开发中不再需要进行后处理。
3. Methodology 方法
基本目的是生产系统中神经网络的快速运行速度和并行计算的 优化,而不是低计算量理论指标(BFLOP)。我们提出了两种实时神 经网络:
- 对于 GPU,我们在卷积层使用少量组(1-8):CSPResNeXt50 / CSPDarknet53
- 对于VPU,我们使用分组卷积,但避免使用 Squeeze-andexcitement (SE)blocks。具体包括以下模型:EfficientNet-lite / MixNet [76] / GhostNet[21] / MobileNetV3
3.1 Selection of architecture 架构选择
我们的目的是在输入网络分辨率、卷积层数目、参数数量(卷积 核 2 * 卷积核个数 * 通道数/组数)和每层输出个数(过滤器)之间 找 到 最佳平衡。例如我们的许多研究表明 CSPResNext50 在 ILSVRC2012(ImageNet)数据集上的目标分类效果比 CSPDarknet53 好 很多。然而,CSPDarknet53 在 MS COCO 数据集上的目标检测效果比 CSPResNext50 更好。
下一个目标是选择额外的 blocks 以扩大感受野,从不同级别的 backbone 中选择最佳的参数组合方法以达到不同水平的检测效果,例 如 FPN、PAN、ASFF、BiFPN。
一个最佳的分类参考模型并不总是最佳的检测器。与分类器相比, 检测器需要满足以下几点:
- 更大的输入网络尺寸(分辨率)——用于检测多个小尺寸目 标
- 更多的层数——获得更大的感受野以便能适应网络输入尺寸 的增加
- 更多参数——获得更大的模型容量以便在单个图像中检测多 个大小不同的物体。
我们可以假设选择的 backbone 模型具有较大的感受野(具有很 多 3×3 卷积层)和大量的参数。表 1 显示了 CSPResNeXt50, CSPDarknet53 和 EfficientNet B3 的相关信息。CSPResNext50 仅包含 16 个 3×3 卷积层、425×425 感受野大小和 20.6M 个参数,而 CSPDarknet53 包含 29 个 3×3 卷积、725×725 感受野大小和 27.6M 个参数。这种理论上的证明,加上我们大量的实验表明:CSPDarknet53 是这两个神经网络中最佳的检测器 backbone 模型。

不同大小的感受野的影响总结如下: 最大目标尺寸——允许观察到整个目标 最大网络尺寸——允许观察到目标周围的上下文 超出网络尺寸——增加图像像素点与最终激活值之间的连接 数
我们将 SPP 模块添加到 CSPDarknet53 上,因为它大大增加了感 受野,分离出最重要的 context 特征,然而几乎不会导致网络运行速 度降低。我们使用 PANet 作为来自不同检测器水平不同 backbone 的 参数组合方法而不是 YOLOv3 中使用的 FPN。 Finally, we choose CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, and YOLOv3 (anchor based) head as the architecture of YOLOv4. 最后,对于 YOLOv4 架构,我们选择 CSPDarknet53 为 backbone、 SPP 额外添加模块、PANet path-aggregation 为 neck、YOLOv3(基于 anchor 的)为 head。
之后,我们将计划大幅扩展 Bag of Freebies(BoF)的内容到检测 器架构中,这些扩展的模块理论上应该可以解决一些问题并增加检测 器准确性,并通过实验的方式按顺序检查每个功能的影响。
我们没有使用跨 GPU 的批标准化(CGBN 或 SyncBN)或昂贵的 专用设备。这使得任何人都可用常规图形处理器,例如 GTX 1080Ti 或 RTX2080Ti,复现我们最新的成果。
3.2. Selection of BoF and BoS BoF 和 BoS 的选择
为了改善目标检测的训练,CNN 通常会使用如下方法或结构: 激活函数: ReLU、leaky-ReLU、parametric-ReLU、ReLU6、 SELU、Swish、Mish 边界框损失回归:MSE、IoU、GIoU、CIoU、DIoU 数据增强:CutOut、MixUp、CutMix 正则化方法:DropOut、DropPath[36]、Spatial DropOut [79]、 DropBlock 通 过 均值和 方 差 标准化网络激活函数输出值: Batch Normalization (BN) [32] 、 Cross-GPU Batch Normalization (CGBN or SyncBN)[93]、Filter Response Normalization (FRN) [70]、Cross-Iteration Batch Normalization (CBN) [89] 快捷连接(Skip-connections):残差连接、加权残差连接、多 输入加权残差连接、Cross stage partial connections (CSP)
至于训练激活函数,由于 PRELU 和 SELU 的训练难度较大,而 ReLU6 是专门为量化网络而设计的,因此我们从候选列表中删除这 几个激活函数。至于正则化方法,发表了 DropBlock 的人将他们的方 法与其他方法进行了细致的比较,他们的正则化方法完胜。因此,我 们毫不犹豫地选择了 DropBlock 作为我们正则化方法。至于归一化 (或标准化)方法的选择,由于我们只关注在仅使用一个 GPU 上的 训练策略,因此不会考虑使用 syncBN。
3.3. Additional improvements 额外的改进
为了使所设计的检测器更适合于在单 GPU 上进行训练,我们做 了如下额外的设计和改进: 我们引入了一种新的数据增强方法 Mosaic 和自对抗训练方 法(Self-Adversarial Training,SAT) 我们使用遗传算法选择最优超参数 我们对现在方法做了一些修改,使得我们的设计更适合于高 效的训练和检测——修改的 SAM、修改的 PAN 和 Cross miniBatch Normalization (CmBN).
Mosaic 是一个混合了 4 个训练图像的新的数据增强方法。由于 混合了 4 个不同的 contexts,而 CutMix 只混合了 2 个输入图像。这 使得可以检测到目标正常 contexts 之外的目标。此外,批标准化从每 层上4个不同的图像计算激活值统计数据。这显著地减少了对大batch size 的需要。

自对抗训练(Self-Adversarial Training,SAT)也是一种新的数据 增强技术,以 2 个前向反向阶段的方式进行操作。在第一个阶段,神 经网络改变的是原始图像而不是的网络权重。这样神经网络对其自身 进行对抗性攻击,改变原始图像并创造出图像上没有目标的假象。在 第 2 个阶段中,通过正常方式在修改的图像上进行目标检测对神经网 络进行训练。
如图 4 所示,CmBN 是 CBN 的修改版,定义为 Cross mini-Batch Normalization(CmBN)。其只收集单个批次内 mini-batches 之间的统计 数据。

如图 5 所示,我们将 SAM 从 spatial-wise attention 修改为 pointwise attention,如图 6 所示,我们将 PAN 的快捷连接改为拼接。


3.4. YOLOv4 YOLOv4
本节,我们将详细介绍 YOLOv4。 YOLOv4 包括:
- Backbone:CSPDarknet53 [81]
- Neck:SPP [25]、PAN [49]
- Head:YOLOv3[63] YOLO v4 使用:
- Bag of Freebies (BoF) for backbone:CutMix and Mosaic 数据 增强、DropBlock 正则化、Class label smoothing
- Bag of Specials(BoS) for backbone:Mish 激活函数、Crossstage partial connections (CSP) 、 多输 入 加 权 残 差 连 接 (MiWRC)
- Bag of Freebies (BoF) for detector: CIoU损失、CmBN、 DropBlock 正则化、Mosaic 数据增强、自对抗训练、Eliminate grid sensitivity、Using multiple anchors for a single ground truth、 Cosine annealing scheduler [52]、优化超参数、Random training shapes
- Bag ofSpecials (BoS) for detector:Mish 激活函数、SPP-block、 SAM-block、PAN path-aggregation block、DIoU-NMS
4. Experiments 实验
我们测试了不同的训练改进在 ImageNet 数据集分类任务 (ILSVRC 2012 年 val)和 MS COCO(test-dev 2017)数据集检测上 的准确性。
4.1. Experimental setup 实验设置
在 ImageNet 的图像分类实验中,默认超参数如下:训练步数为 8 百万次;批大小和 mini 批大小分别为 128 和 32;polynomial decay learning rate scheduling strategy 初始学习率为 0.1 的多项式衰减调度 策略;warm-up 步数为 1000;动量和衰减权重分别设定为 0.9 和 0.005。 我们所有的 BoS 实验都使用的默认超参数设置,而在 BoF 实验中, 我们增加了额外 50%的训练步数。在 BoF 实验中,我们验证了 MixUp、 CutMix、Mosaic、Bluring 数据增强和标签 smoothing 正则化方法。在 BoS 实验中我们比较了 LReLU、Swish 和 Mish 激活函数的效果。所 有实验都使用用 1080Ti 或 2080 Ti GPU 进行了训练。
在 MS COCO 目标检测实验中,默认参数如下:训练步数为 500500;采用初始学习率为 0.01 的学习率衰减策略,并分别在 40 万 步和45万步时乘以系数0.1。动量和权重衰减分别设置为0.9和0.0005。 所有的架构使用单个 GPU 进行了多尺度训练,批大小为 64,mini 批 大小为 8 或 4,具体取决于模型架构和 GPU 显存容量限制。除了使 用使用遗传算法进行超参数搜索外,所有其他实验均使用默认设置。 YOLOv3-SPP 使用的遗传算法实验使用 GIoU 损失进行训练,对 minval 5k 数据集进行了 300 轮的搜索。遗传算法采用搜索学习率为 0.00261、动量为 0.949,真实值的 IoU 阈值设置为 0.213,损失正则 化为 0.07。我们也经验证了大量的 BoF,包括 grid sensitivity elimination、 马赛克数据增强、IoU 阈值、遗传算法、类别标签 smoothing、跨小批 量标准化、自对抗训练、cosine annealing scheduler、dynamic mini-batch size、DropBlock、Optimized Anchors、不同类型的 IoU 损失。我们也 对各种 BoS 进行了实验,包括 Mish、SPP、SAM、RFB、BiFPN、 BiFPN 和 Gaussian YOLO[8]。对于所有的实验,我们只使用一个 GPU 进行了训练,因此诸如 syncBN 可以优化多 GPU 训练的技术并没有 使用。
4.2. Influence of different features on Classifier training 不同技巧对分类器训练的影响
首先,我们研究了不同技巧对分类器训练的影响;具体而言,研 究了类别标签 smoothing 的影响,如图 7 所示双边模糊(bilateral blurring)、MixUp、CutMix 和马赛克等不同数据增强的影响,以及 Leaky-ReLU(默认值)、Swish 和 Mish 等不同激活函数的影响。

如表 2 所示,我们的实验引入了以下技巧从而提高了精度,如 CutMix 和马赛克数据增强、类别标签 smoothing 和 Mish 激活函数。 因此,我们的分类器训练的 BoF-backbone (Bag of Freebies)包括 CutMix 和 Mosaic 数据增强、类别标签 smoothing。除此之外,如表 2 和表 3 所示我们还使用了 Mish 激活函数作为互补选项。


4.3 Influence of different features on Detector training 不同技巧对检测训练的影响
如表 4 所示,深入研究了不同 Bag-of-Freebies (BoF-detector)在检 测器训练中的影响。我们通过研究不影响 FPS 的同时能提升精度的 技巧,显著扩展了 BOF 列表的内容,具体如下:
- S:消除了格子灵敏度,在 YOLOv3 通过方程 bx=σ(tx)+cx, by=σ(ty)+cy 计算对象坐标,其中 cx 和 cy始终为整数,因此, 当 bx 值接近 cx 或 cx+1 时需要极高的 tx 绝对值。我们通过 将 sigmoid 乘以超过 1.0的因子来解决此问题,从而消除了没 有检测到目标格子的影响。
- M:马赛克数据增强——训练时使用 4 张图像的马赛克结果 而不是单张图像
- IT:IoU 阈值——针对一个真值边界框使用多个 anchor,Iou (真值,anchor)>IoU 阈值
- GA:遗传算法——在网络训练最初 10%的时间内使用遗传算 法筛选最优超参数
- LS:类别标签 smoothing——对 sigmoid激活函数结果使用类 别标签 smoothing
- CBN:CmBN——使用 Cross mini-Batch Normalization在整个 小批量内收集统计数据,而不是在单个 mini 小批量收集统计 数据
- CA:Cosine annealing scheduler——在正弦训练中改变学习率 DM:Dynamic mini-batch size——采用随机训练形状时,对于小分辨率的输入自动增大 mini-batch 的大小
- OA:最优化 Anchors——使用最优化 anchor 对 512×512的网 络分辨率进行训练
- GIoU、CIoU、DIoU、MSE——边界框使用不同的损失算法

如表 5 所示,进一步的研究涉及了不同的 Bag-of-Specials(BoSdetector)对检测器训练精度的影响,包括 PAN、RFB、SAM、Gaussian YOLO(G)和 ASFF。在我们的实验中,当使用 SPP、PAN 和 SAM 时, 检测器获得最佳性能。

4.4 Influence of different backbones and pre-trained weightings on Detector training 不同 backbone 和预训练权重对检测器训练的影响
如表 6 所示,我们进一步研究不同 backbone 对检测器精度的影响。我们注意到具有最佳的分类精度的模型架构并不总是具有最好的 检测精度。

首先,虽然使用不同特征的 CSPResNeXt50 模型的分类准确率高 于 CSPDarknet53 模型,但是 CSPDarknet53 模型在目标检测方面具 有更高的精度。
其次,CSPResNeXt50 分类器的训练使用 BoF 和 Mish 后提高了 其分类精度,但将这些预先训练的权重应用到检测器训练时则降低了 检测器的精度。然而,CSPDarknet53 分类器的训练时使用 BoF 和 Mish 均提高了分类器和检测器的精度,检测器使用了分类器预训练的权重。 最终的结果是, CSPDarknet53 比 CSPResNeXt50 更适合于做检测器 的 backbone。
我们观察到,CSPDarknet53 模型由于各种改进体现出更大的能 力来提高检测器的精度。
4.5 Influence of different mini-batch size on Detector training 不同的 mini-batch size 对检测器训练的影响
最后,我们分析了模型经过不同 mini-batch 大小的训练的结果, 结果图表 7 所示。从表 7 所示的结果来看,我们发现训练时加入 BoF 和 BoS 后 mini-batch 大小几乎对检测器性能没有任何影响。这一结果 表明,引入 BoF 和 BoS 后将不再需要使用昂贵的 GPU 来进行训练。 换句话说,任何人都可以只使用一个传统的 GPU 来训练一个优秀的 检测器。

5. Results 结果
如图 8 所示为我们的模型与其他最先进的检测器的比较结果。我 们的 YOLOv4 位于帕累托最优曲线上,并且在速度和精度方面都超 过最快和最精确的检测器。
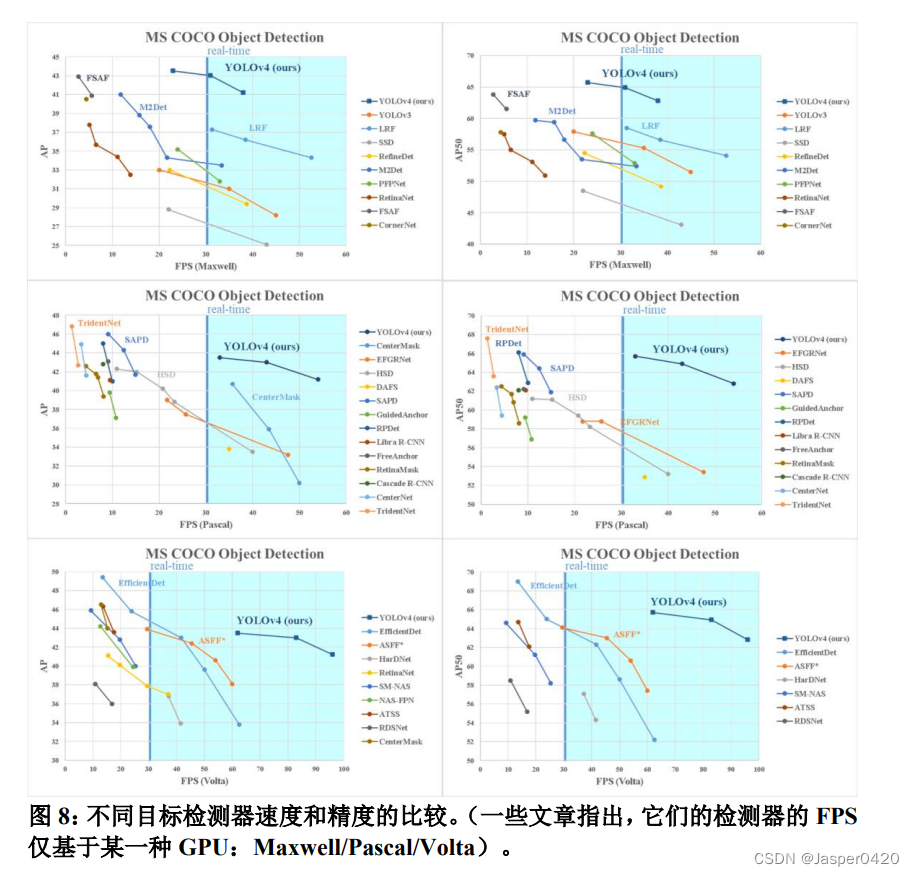
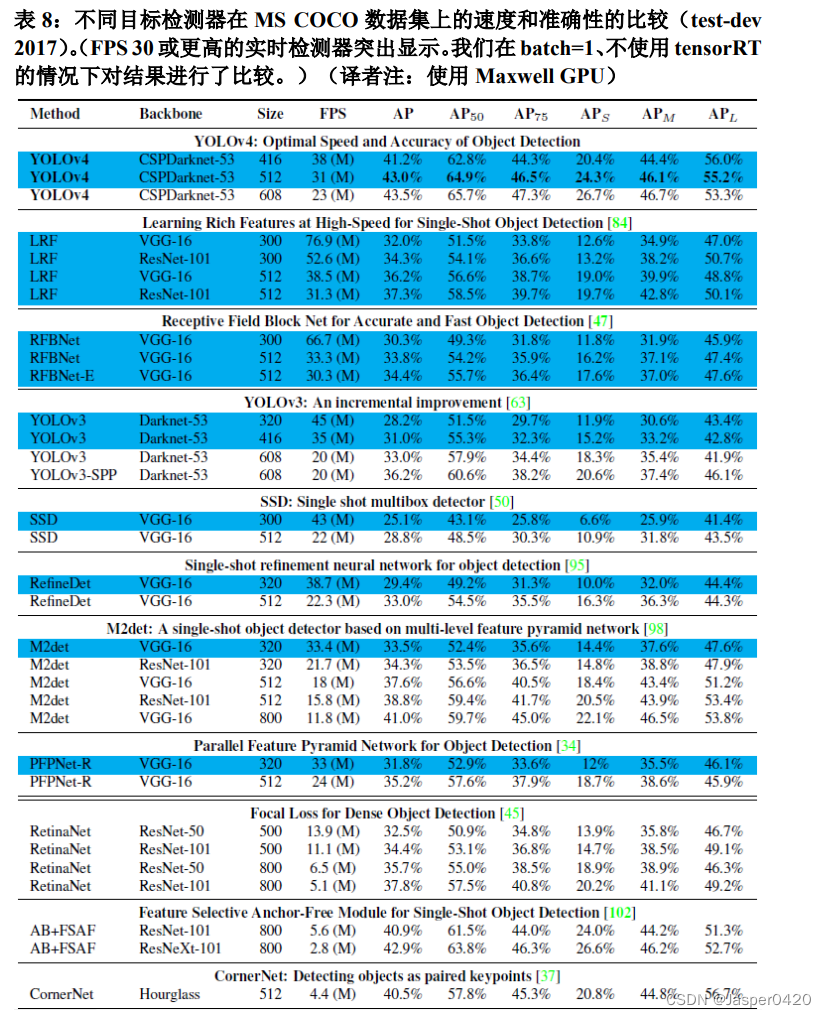
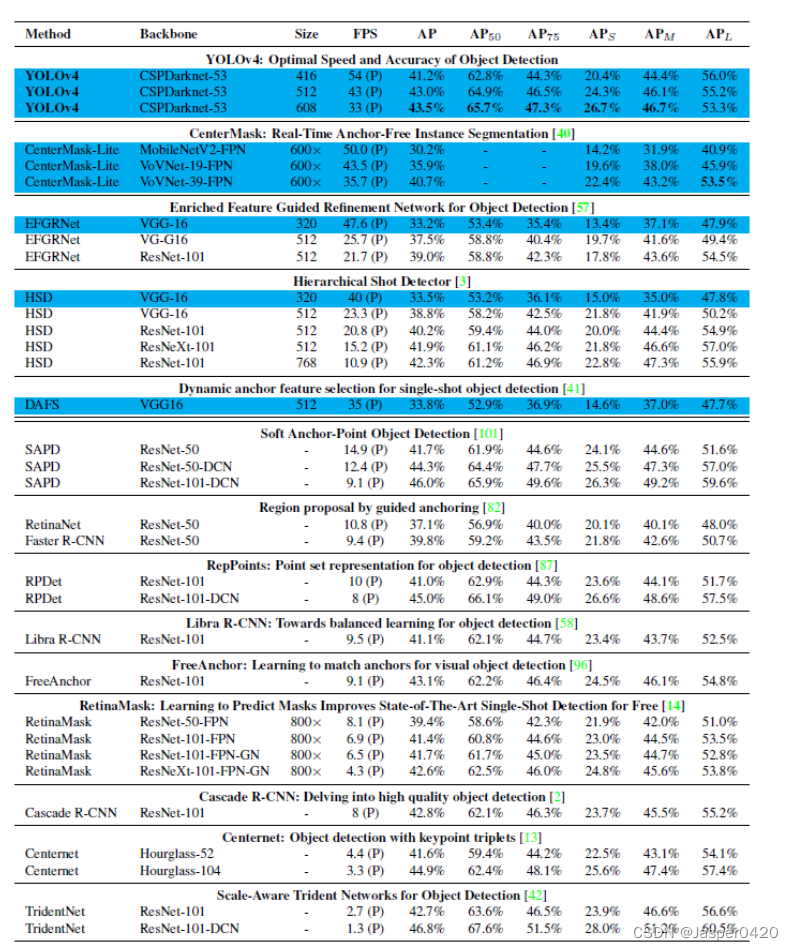
由于不同的方法在进行推理时间验证的时候使用了不同架构的 GPU,我们让 YOLOv4 运行在 Maxwell、Pascal 和 Volta 等常用的 GPU 上,并与其他最新技术进行了比较。表 8 列出了使用 Maxwell GPU 时帧率的比较结果,具体型号可以是 GTX Titan X (Maxwell)或 Tesla M40 GPU)。表 9 列出了使用 Pascal GPU 时帧率的比较结果, 具体型号可以是 Titan X(Pascal)、Titan Xp、GTX 1080 Ti 或 Tesla P100 GPU。表 10 列出使用 Volta GPU 时帧率的比较结果,具体型号 可以是 Titan Volta 或 Tesla V100 GPU。



6. Conclusions 结论
我们提供了一个最先进的检测器,相比于其它所有可用、可替代 的检测器其速度更快(FPS)、更准确(MS COCO AP50…95 和 AP50)。 该检测器可以在 8-16GB-VRAM 的传统 GPU 上训练和使用,这使得 它能够被广泛使用。基于一阶段 anchor 原始概念的检测测器已经被 证实是可行的。我们已经验证了大量方法,并选择使用其中一些方法 以提高分类器和检测器的准确性。这些方法可以用作未来研究和开发 的最佳实践。
更多Ai资讯:公主号AiCharm
