目录
3.1. Image preprocessing and data preparation
3.7. Statistical significance of classifiers performance
4.1. Assessment of classification accuracies using different algorithms
4.2. Test for statistical significance in classification accuracy
题目:A statistical significance of differences in classification accuracy of crop types using different classification algorithms
Abstract
为了了解不同作物的生理和气候要求,需要进行作物分类。尝试采用基于核的支持向量机、最大似然和归一化差分植被指数分类方案来评估它们在作物分类中的性能。对线性成像自扫描(LISS-IV)多光谱传感器数据进行了评估,以对作物类型进行分类,如大麦、小麦、扁豆、芥末、木豆、亚麻籽、玉米、豌豆、甘蔗和其他作物,以及非作物,如水、沙、建筑、休耕地、稀疏植被和密集植被。为了确定作物类型之间的光谱可分性,使用了M统计量和Jeffries–Matusita(J–M)距离方法。采用Z检验和χ2检验对结果进行统计分析和比较。统计分析表明,使用多项式为5次和6次的SVM的准确度结果没有显著差异,并且优于其他分类算法。
1. Introduction
与传统卫星图像相比,高空间分辨率卫星图像的出现为作物精确分类提供了新的可能性(Yang等人,2011年)。作物分类图对于估计作物多样性以及进行农业灾害补偿非常有用。这些地图也有助于管理农田,以获得更好的作物产量。然而,由于农业领域的高光谱变异性或异质性,通过粗分辨率图像进行作物监测并不总是可能的。光学和红外波段的线性成像和自扫描(LISS-IV)等高空间分辨率多光谱卫星传感器已成为作物类型监测的一种可能方法。LISS-IV传感器有潜力捕捉农田内的田间变异(Sesha Sai&Narasimha Rao 2008;Kumar等人2015)
单日期多光谱卫星图像通常用于作物识别和分类。然而,许多研究人员已经认识到使用多日期图像绘制农作物地图的好处(Panigrahy&Sharma 1997;Simonneaux等人,2008)。单一日期的使用或多日期图像取决于多种因素,例如所用图像的类型和图像中包含的波段数(Singh et al.2015),以及成本和天气限制,包括一个地区种植的作物类型及其生长期。作物日历可用于确定是否可以在一个区域的单个日期图像上覆盖所有主要作物,否则需要使用多日期图像。很多时候,在给定区域的最佳作物识别和分类期间,只能拍摄一个无云的单日期卫星场景。因此,通常采用不同类型的分类算法和大量训练样本,从单日期图像中准确识别作物(Yang et al.2011)。
在遥感领域,开发了几种分类算法来解决与多光谱卫星数据分类相关的问题(Banerjee&Srivastava,2013年,2014年)。在本研究中,基于核的支持向量机(SVM)、最大似然(ML)和归一化差异植被指数(NDVI)算法用于不同的作物分类。SVM算法之所以被选中,是因为它对遥感数据的分类要求越来越深远(Islam et al.2012;Srivastava et al.2012:Srivatava et al.2014;Singh et al.2014;Kumar et al.2015)。在过去几十年中,基于核的SVM算法已广泛用于遥感数据的分类(Huang et al.2002;Foody&Mathur 2004;Pal&Mather 2004;Mountrakis et al.2011;Pal et al.2013;Islam et al.2014;Singh et al.14;Kumar et al.2015)。Huang等人(2002年)比较了SVM、ANN(人工神经网络)、ML和决策树算法对Landsat主题映射器和中分辨率成像光谱仪数据集的土地覆盖分类的精度,以及对具有多项式和径向基函数核的SVM的满意结果。
对于使用LISS-IV传感器数据的作物分类,SVM分类算法比ANN和光谱角度映射算法更有效(Kumar等人,2015)。此外,与其他几种分类算法相比,SVM已被证明具有较高的分类精度。SVM的输出取决于输入像素,指出训练可能是优化分类精度的重要阶段(Pouteau&Collin,2013年)。在几种形式的核方法中,多项式和径向基函数在利用遥感数据进行土地利用和土地覆盖分类方面显示了良好的结果(Pal&Mather,2005年)。SVM算法不仅依赖于核函数的类型。SVM的设计中存在一些主要问题。选择核特定参数、合适的核函数、调节参数和多类分类策略会影响分类精度(Vapnik 1998;Pal 2009;Mountrakis等人2011;Srivastava等人2012)。
还开发了其他一些分类算法,如ML和NDVI分类。尽管由于其分类标签的正态分布假设存在局限性(Swain&Davis 1978),ML算法可能是使用最广泛的算法之一(Wang 1990;Hansen et al.1996)。ML分类算法在对未知像素进行分类时,定量评估类别光谱响应模式的方差和协方差(Lillesand&Kiefer 2002)。NDVI的潜力引起了人们对全球生物圈动力学研究的极大兴趣(Goward等人,1990年)。由于NDVI的简单性,它已成为全球植被监测的首选方法。许多研究人员将NDVI与若干植被现象联系起来,例如全球和大陆尺度的植被季节动态与地面覆盖率测定、叶面积指数测量、生物量估算和吸收的光合作用有效辐射的比例(Lillesand&Kiefer 2002)。NDVI值不能直接提供土地覆盖类型;它通常量化了陆地表面的生物物理活动。然而,NDVI值的时间序列可以根据物候或季节信号区分不同的土地覆盖类型(Lenney等人,1996年)。Reed等人(1994年)和De Fries等人(1998年)开发并使用了多时相物候指标,从AVHRR数据中得出土地覆盖分类。在本研究中,利用地面真实信息确定了不同作物类型的NDVI值范围,并进行了分类。
在之前的研究中,有几项研究报告称,径向基函数核可以很好地与遥感数据集配合使用(Foody&Mathur 2004;Pal&Mather 2004;Kumar等人,2015年)。Paneque-Gálvez等人(2013年)表明,与SVM线性分类器和SVM多项式分类器相比,SVM径向基函数和SVM sigmoid分类器的性能更好。在少数研究中,发现在使用高光谱数据进行分类时,二阶多项式核的性能优于径向基核(Bahria等人,2011年)。Schwert等人(2013年)使用带gamma参数1的三阶多项式函数核进行变化检测分类,与线性、径向基和乙状函数核相比,其结果最准确。在印度瓦拉纳西,使用SVM算法对LISS-IV数据进行了有限的研究(Kumar等人,2015年)。
在本研究中,为了进行作物类型映射,尝试对SVM进行不同核函数和多项式次数的严格评估,以及基于ML和NDVI的分类。采用Z检验和χ2检验等复杂的统计方法来估计不同分类器分类精度差异的显著性。这项研究提供了有关以农业做法为主的地区作物类型存在的重要信息。这些信息对于成功管理和监测多样性、灾害补偿和作物生产力至关重要。更广泛地说,这项研究还对LISS-IV在检测和绘制作物类型方面的评估做出了重大贡献。
2. Study area and materials
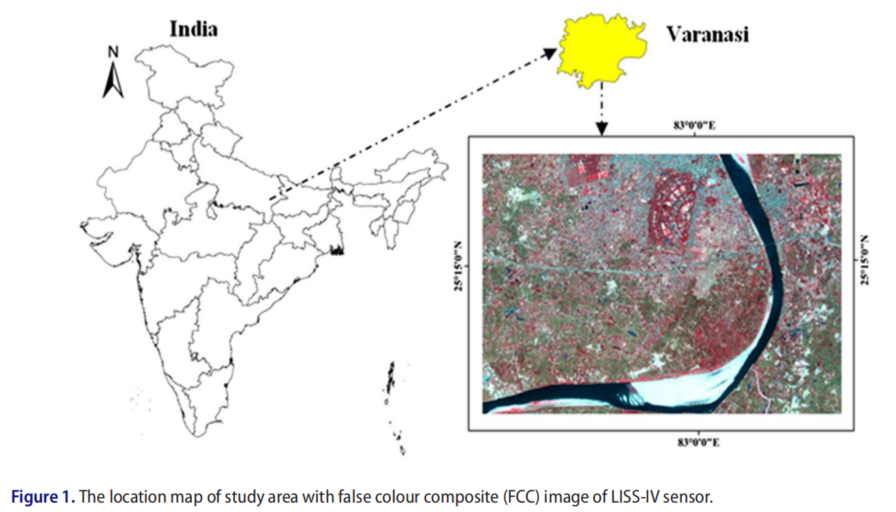
16种不同作物和非作物类别的地面实况信息来自于印度北方邦瓦拉纳西地区的一项研究。它位于圣河恒河岸边。该地面实况信息是在2013年4月6日的实地考察期间借助全球定位系统收集的。研究区域位于北纬25°12′09〃至25°17′09″之间,东经82°55′07〃至83°03′14〃之间,面积约为12576公顷。表1给出了2013年4月6日获得的、用于本研究的LISS-IV传感器数据的特征。
作物分类研究是使用在5.1版可视化图像(ENVI)软件环境中实现的不同算法进行的。图1显示了用于分类的研究区域。

3. Methodology
3.1. Image preprocessing and data preparation
单个日期图像的大气校正通常相当于从光谱带中的所有像素中减去一个常数。因此,对于遥感应用,例如同一日历日期图像的图像分类,不需要进行大气校正(Song等人,2001年)。三个波段,如B2(绿色,0.52–0.59μm)、B3(红色,0.62–0.68μm)和B4(NIR,0.77–0.86μm),用于层叠加,以生成假彩色合成(FCC)图像。生成FCC图像后,对其进行几何校正。进行子集选择,以提取覆盖研究区域的数据,用于作物和非作物分类。选择子集后,选择培训区域并生成感兴趣区域(ROI)文件。培训和测试样本是从位于瓦拉纳西区的Banaras Hindu University(BHU)农业农舍内外的不同田地采集的。进行随机抽样以收集培训和测试样本。其中一个ROI文件被用作培训数据集。这些训练样本用于训练用于作物分类的SVM算法。其他ROI文件用于地面验证。使用由2683个像素组成的独立数据集来测试分类精度,并使用两倍以上的测试像素来训练分类中使用的算法。用于分类的培训和验证数据集如表2所示。

3.2. Spectral separability
为了确定作物类型之间的光谱可分性,使用了M统计量(Kaufman&Remer 1994)和Jeffries–Matusita(J–M)距离法(Richards 1999)。M统计量根据平均值和标准偏差值表示的两个样本类别分布确定LISS-IV传感器两个频带之间的类别可分性。本研究中使用的M统计量如下:
![]()
式中,μ1是作物类型1的平均反射率值,μ2是作物类型2的平均反射器值,σ1是作物类别1的标准偏差值,而σ2是作物类别2的标准偏差。![]() 的值表明类别明显重叠,并且能够分离这些地区很穷。另一方面,
的值表明类别明显重叠,并且能够分离这些地区很穷。另一方面,![]() 的值表明直方图平均值很好地分离,区域相对容易区分。对LISS-IV图像给定光谱带的每对作物类型进行了M统计比较。
的值表明直方图平均值很好地分离,区域相对容易区分。对LISS-IV图像给定光谱带的每对作物类型进行了M统计比较。
J–M测量基于Bhattacharya距离。它可以指示所选光谱类对在统计上的分离程度。两个等级“a”和“b”的J–M距离如下所示:
![]()

其中,μa和μb是类别a和b的平均值,Ca和Cb是类别a和b的协方差矩阵,T表示向量的转置。J–M距离提供了一个介于0.0和2.0之间的指数。其值![]() 表明,这些类别很好地分开(ITT Industries Inc 2006)。J–M距离值
表明,这些类别很好地分开(ITT Industries Inc 2006)。J–M距离值![]() 表示这对类之间的可分性较差。
表示这对类之间的可分性较差。
3.3. SVMs classification
SVM是一种非参数分类算法,起源于统计学习理论(Vapnik 1998;Mountrakis等人,2011)。当训练数据是线性可分的时,它首先被设计成一个最优的分离超平面。该算法最大化了最优线性分离超平面和最近训练样本之间的边界。最接近用于测量边缘的超平面的训练样本称为支持向量(Vapnik 1998;Huang等人,2002)。在两类分类问题的情况下,算法在无限数量的线性决策边界中选择在两类之间提供最大裕度的一个。边界被定义为从两个类的最近点到超平面的距离之和(Vapnik 1998)。同时,SVM确定了类别之间的最佳决策边界,以最小化错误分类(Mountrakis等人,2011年)。当无法避免某些训练样本之间的误分类时,引入惩罚参数来表示误分类惩罚与超平面简单性之间的权衡。惩罚参数值越小,表示错误分类的容忍度越高。SVM能够处理非常非线性的问题,即使训练数据集有噪声。它本质上将非线性问题转化为线性问题,使用核函数将原始输入空间映射到具有更高维度的新特征空间(Vapnik 1998)。函数![]() 称为核函数,C>0是误差项的惩罚参数。这里,训练向量xi通过函数ν映射到更高维空间。在这个研究中使用的四个SVM核(线性、多项式、径向基和sigmoid)在方程中给出。
称为核函数,C>0是误差项的惩罚参数。这里,训练向量xi通过函数ν映射到更高维空间。在这个研究中使用的四个SVM核(线性、多项式、径向基和sigmoid)在方程中给出。
![]()
![]()

![]()
其中γ、r和d分别是核函数中的gamma项、核函数的偏倚项和极化度项。伽马和惩罚参数的值分别为0.33和100。惩罚参数控制边缘和误分类错误之间的权衡,而gamma参数控制核函数的宽度(Cortes & Vapnik 1995)。
设计了许多SVM算法,每种算法都使用不同类型的核。然而,研究中评估了2–6次线性多项式、径向基函数和乙状函数核。在图像分类之前,将一个核应用于输入特征空间,以提高类之间的可分性。详细介绍了遥感分类中常用的SVM核函数(Kavzoglu&Colkesen 2009)。支持向量机广泛应用于遥感数据分类的一个主要原因是,它有可能产生比神经网络算法更高的分类精度(Foody&Mathur 2004;Waske&Benediktsson 2007;Kumar et al.2015)
3.4. ML classification
ML分类是一种著名的基于统计理论的参数分类算法。它依赖于每类高斯概率密度函数模型的二阶统计量。该算法基于像素属于特定类别的概率。基本方程假设每个频带中所有类别的概率相等,并且输入频带具有正态分布。每个像素被分配给概率最高的类(Richards 1999)。如果事先知道并非所有类别的概率都相等,那么可以为特定类别指定权重因子。除非事先了解概率,否则建议不要指定权重系数(Hord 1982)。在这种情况下,默认情况下,公式(8)中的权重系数为1.0。ML分类器的方程式如下所示:
![]()
其中,D=加权距离,c=特定类别,X=候选像素的测量向量,Mc=c类样本的平均向量,ac=任何候选像素为c类成员的概率百分比,Covc=c类样本中像素的协方差矩阵,||Covc||=Covc的行列式,![]() =Covc的逆,ln=自然对数函数,T=换位函数。
=Covc的逆,ln=自然对数函数,T=换位函数。
3.5. NDVI classification
植被覆盖区具有较高的近红外反射率和较低的可见光反射率。由于植被的这种性质,NIR和红带的不同数学量被发现是绿色植被状况的敏感指标(Lillesand&Kiefer 2002)。最常用的数学组合是NDVI分类。NDVI分类基于LISS-IV图像的红色和近红外波段生成的NDVI值,定义为

NDVI将绿色植被与其背景土壤亮度分开,并保留了最小化地形影响的能力。NDVI值的范围为−1到+1,从0缩放到255以便于显示。NDVI值为零表示该地区没有可用植被。NDVI值对植被的存在很敏感。由于通常存在绿色植被由于叶绿素吸收,降低了红色波段的信号,由于叶片的光散射,增加了近红外波段波长的信号(Tucker等人,1985年)。NDVI值越高,表明植被的绿叶面积或生物量含量越高。
3.6. Classification accuracy
通过误差矩阵统计计算(Congalton&Green 1999),评估了分类器生成的不同专题地图的准确性。因此,总体准确度(OA)、生产者准确度(PA)、用户准确度(UA)和kappa系数(Kc)计算如下:



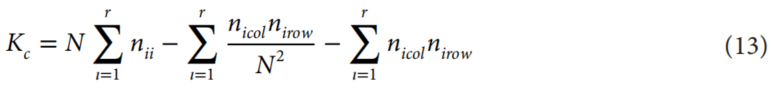
其中,nii是在一个类别中正确分类的像素数;N是混淆矩阵中的像素总数;r是行数;![]() 和
和![]() 分别是列(参考数据)和行(预测类)的总和。
分别是列(参考数据)和行(预测类)的总和。
可以通过将正确分类的像素总数除以分类中使用的测试像素总数来评估OA。UA是委员会误差的度量,指示地图上分类的类别实际代表该类别的概率。同样,PA是对遗漏错误的度量,表明实际区域被正确分类的可能性(Lillesand & Kiefer 2002)。计算Kc是为了比较实际发生在地面上的类别与偶然发生的分类器分类之间的真实一致性(Cohen 1960)。还进行了Kc分析,以测试每种分类是否明显优于随机分类,以及是否有任何两种分类存在显著差异。Kc值为0表示总体随机分类,而Kc值1表示分类和参考数据之间完全一致(Congalton & Green 1999)。验证点通常是基于随机分布的非均匀区域选择的,远离采集训练点的位置,确保训练数据和验证点之间的像素不重叠。这些信息是从实地考察和之前在该地区进行的研究(Kumar等人,2015年)中获得的。
3.7. Statistical significance of classifiers performance
可以使用McNemar检验(Agresti 1996)评估两个比例之间差异的统计显著性。
3.7.1. Z-test
Z检验通常用于检验两种分类算法是否提供了相似的准确度结果的假设。该测试基于标准化正常测试,如下所示:

其中,f 12表示第一分类算法正确分类但第二分类算法错误分类的样本数。同样,f 21表示第一种分类算法错误分类的样本数量,以及第二种分类算法正确分类的样本数(Foody 2004;Leeuw et al.2006)。混淆矩阵之间的分类精度差异具有统计学意义(p≤ 0.05)如果Z值大于1.96(Congalton等人,1983年)。
3.7.2. χ2-test
χ2-检验是一种非参数统计检验,用于确定样本的两个或多个分类是否独立。如果应用得当,测试可能会通过拒绝无效假设或未能拒绝它来给我们答案。如果我们发现χ2值小于与我们的置信水平相对应的值,我们可以得出结论,我们的零假设可能是正确的。另一方面,如果χ2值超过置信水平,我们知道χ2检验拒绝了无效假设。因此,我们得出结论,这两种分类相互依存。对于定义为![]() 的临界值,如果
的临界值,如果![]() ,则不拒绝零假设。McNemar(1947)的测试基于标准化正常测试,如下所示
,则不拒绝零假设。McNemar(1947)的测试基于标准化正常测试,如下所示
![]()
当![]() 时,该测试效果良好。对于其他情况,使用二项式检验作为建议。Z检验和χ2-检验基于2×2维混淆矩阵。这些测试是为了测试两种分类算法之间的独立性。两种算法正确和错误分类的参考数据像素的数量可以交叉制表,如表3所示。
时,该测试效果良好。对于其他情况,使用二项式检验作为建议。Z检验和χ2-检验基于2×2维混淆矩阵。这些测试是为了测试两种分类算法之间的独立性。两种算法正确和错误分类的参考数据像素的数量可以交叉制表,如表3所示。

4. Results and discussion
4.1. Assessment of classification accuracies using different algorithms
对瓦拉纳西地区种植的几种作物,如大麦、小麦、扁豆、芥末、木豆、亚麻籽、玉米、豌豆、甘蔗和其他作物进行了分类。小麦作物被发现是分类作物类别中的主导作物。其他非作物类,如水、沙、建筑用地、休耕地、稀疏植被和密集植被也进行了分类。在分类之前,使用M统计量和J–M距离方法来确定作物和非作物类别之间的可分性。使用M检验,波段3和波段4的组合在所有三种波段组合的类别之间提供了总体最佳分离。波段3之间观察到的总体最佳分离与频带4相比,可能是由于这些频带的独特和高光谱反射率值。由于绿色和红色波段的反射率较差,使用波段2和3组合时,发现各类别之间的总体分离度较低。使用带2和带4的组合可以发现类之间存在适度的分离。结果表明,95%的类对的值为M>1,这意味着类被发现很好地分离,其余的对的值均为M<1,这表明类之间的分离很差。使用J–M方法进行的可分性分析也表明,几乎所有类之间都有更好的分离。特别是在非作物类别的情况下,由于其独特和高光谱反射率,发现其可分性优于作物类别。表4给出了使用J–M方法的可分性分析。

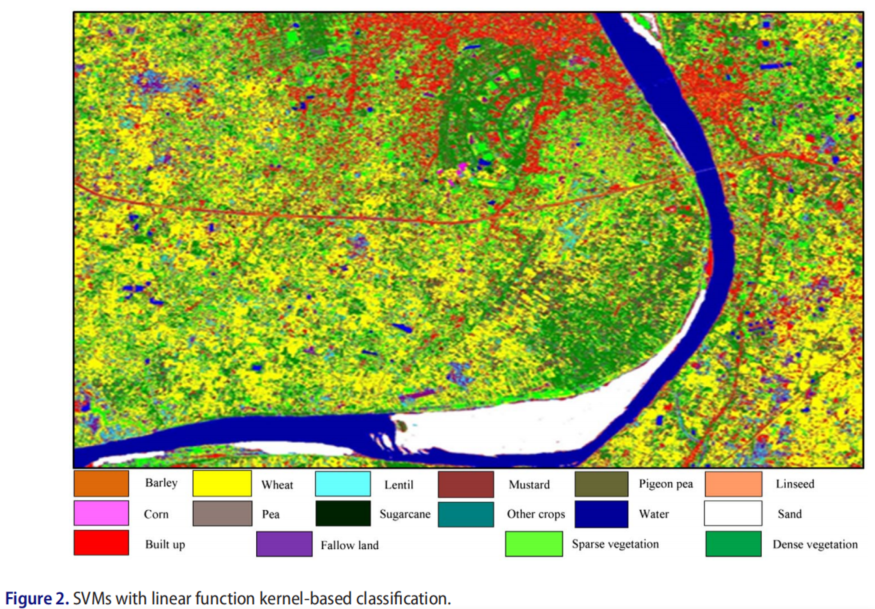
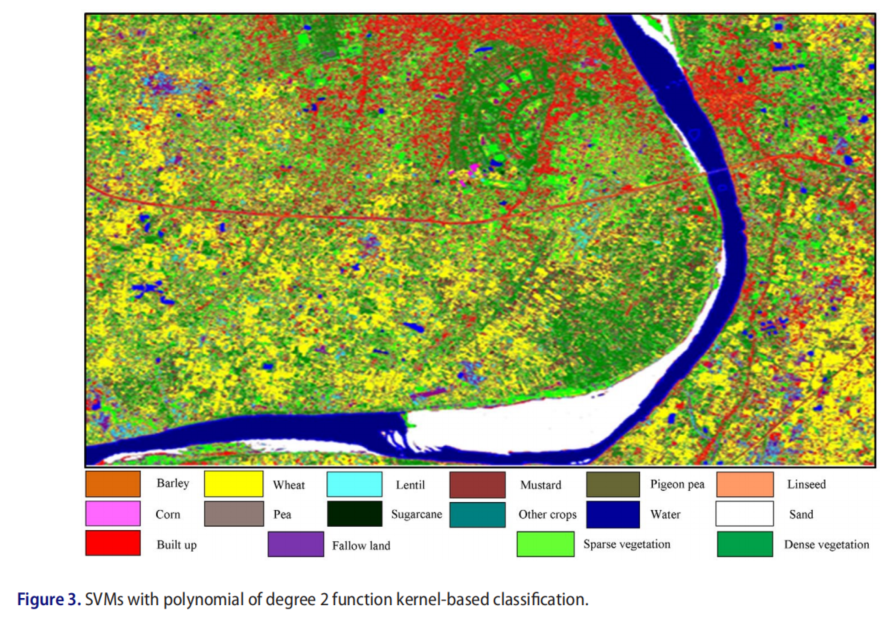
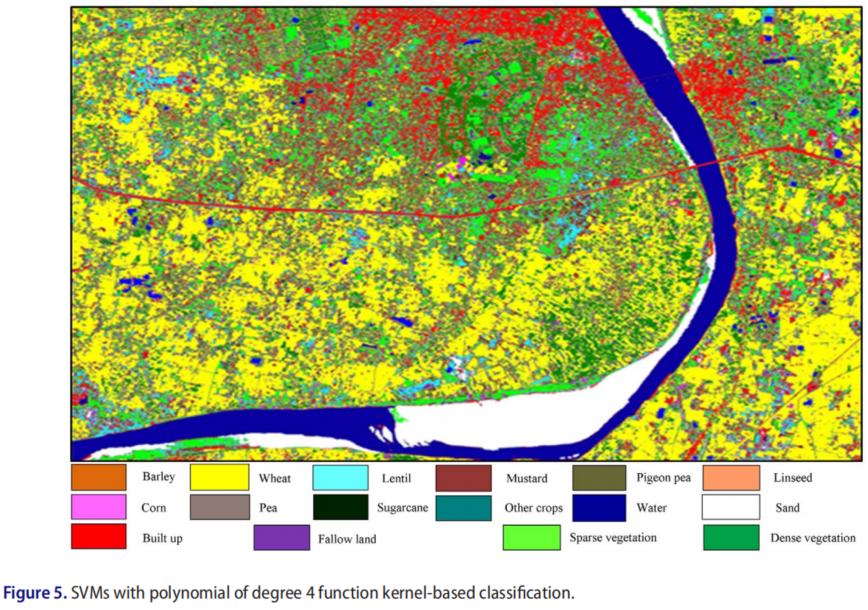
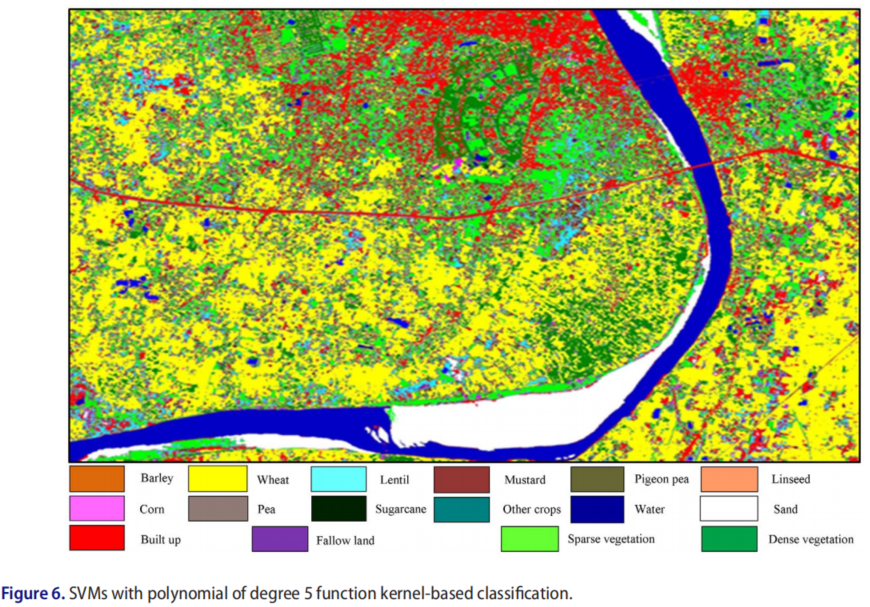
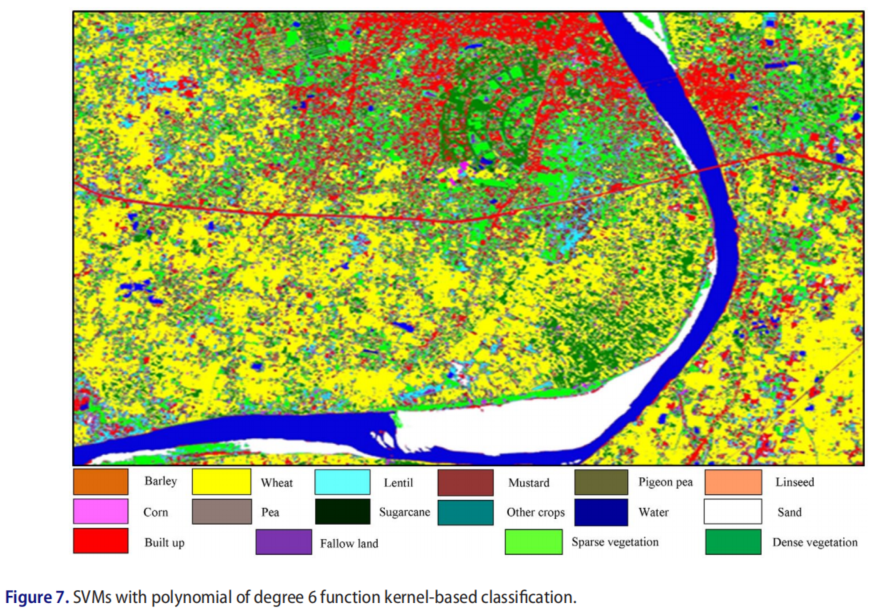
基于核的SVM分类图之间的视觉比较表明作物类和非作物类之间的良好分离,也表明了准确的结果。图2-7显示了使用具有线性核和2-6次多项式算法的SVM生成的分类图。

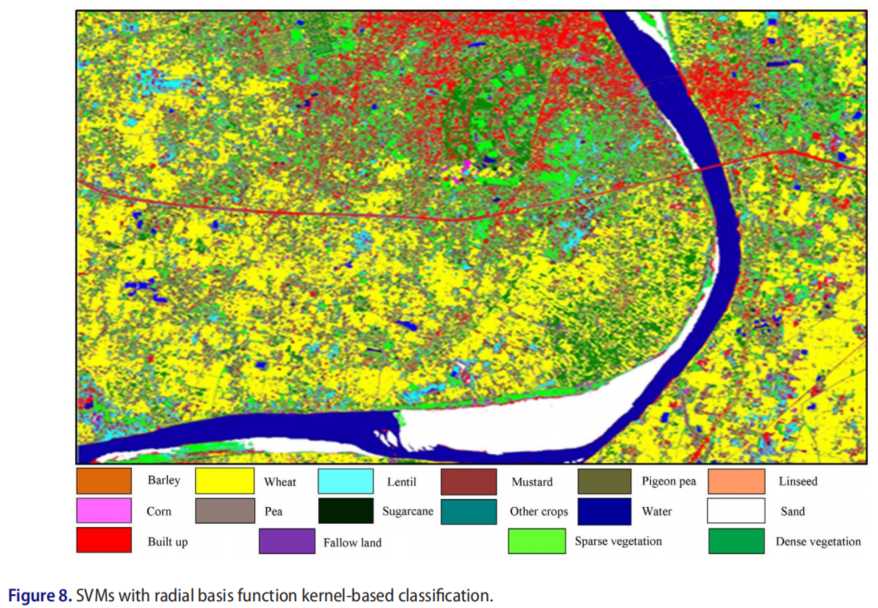
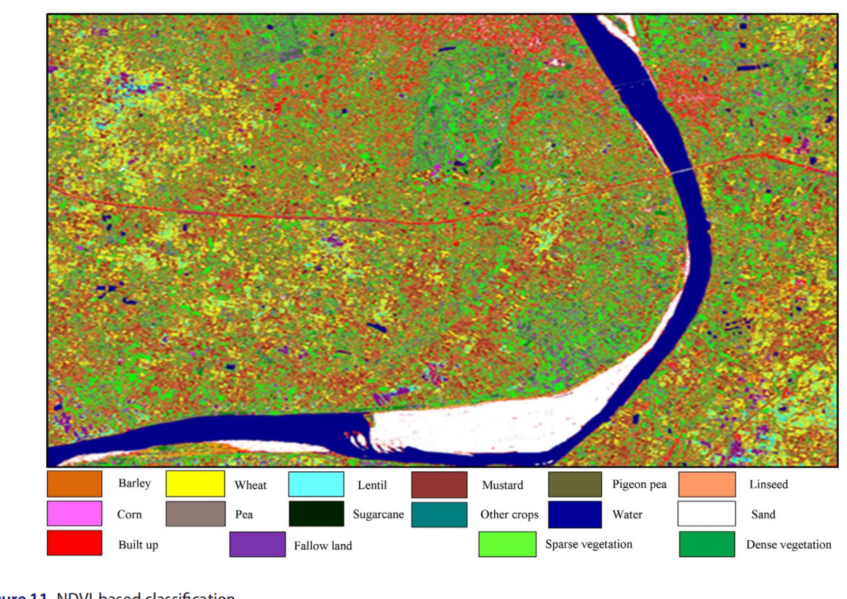
用径向基函数核SVM和ML分类算法生成的分类图也非常直观。用sigmoid核对SVM进行了良好的可视化,但发现NDVI分类图的可视化效果较好。使用径向基、sigmoid核、ML和NDVI算法从SVM生成的分类图如图8-11所示。
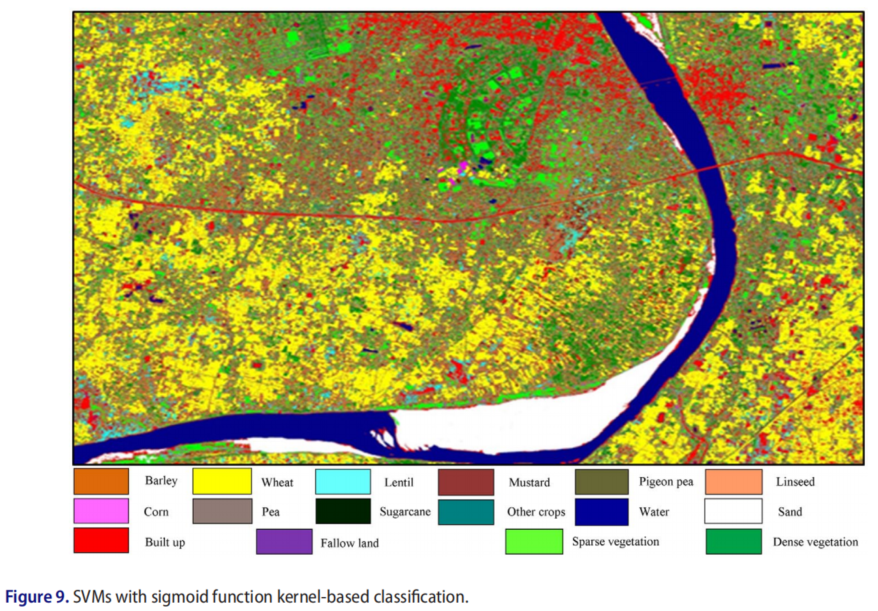

根据OA、UA、PA和Kc对这些分类图进行了评估。线性核和2–6次多项式核SVM评估的精度如表5所示。
使用径向基和乙状核SVM、ML和NDVI分类算法评估准确度结果,并进行比较。比较研究见表6。

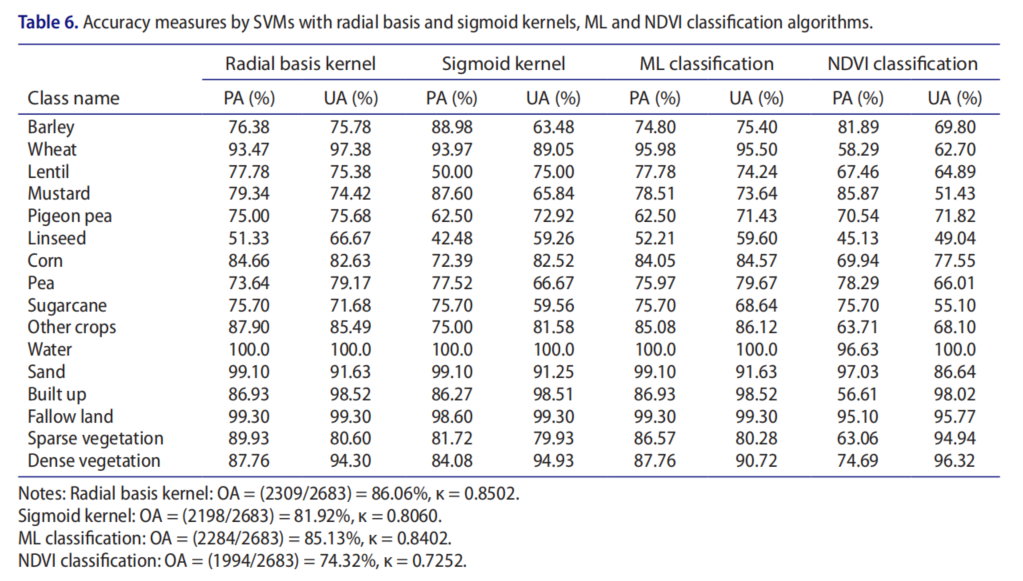
在比较SVM、ML和NDVI分类结果时,具有6次多项式函数核的SVM的OA最高可达87.33%。
使用线性函数核OA为85.05%的SVM和2、3、4和5阶多项式OA分别为85.69、86.47、86.54和87.10%的SVM,也发现了类似的精度结果。
特别是在高叶绿素阶段获得的数据可以提供进一步的区分,并提高分类精度。径向基SVM、S样条函数SVM和ML算法SVM的分类准确率分别为86.06、81.92和85.13%。NDVI分类算法实现了较低的OA(74.32%)。小麦是最主要的作物,玉米是最不主要的作物。这是因为玉米作物不是季节性作物,而是为了研究目的而种植在BHU农舍和瓦拉纳西地区的其他一些地方。
在所有算法中,SVM和ML为几乎所有16个类提供了良好的PA和UA。研究发现,PA和UA对于小麦、其他作物和玉米类别的作物类别来说非常好。除亚麻籽作物外,其他作物类别的所有分类算法也显示出很好的PA和UA,其结果也很好。与其他作物和非作物类别相比,亚麻籽作物的OA、PA和UA较小,因为亚麻籽与其他作物类别和一些非作物类别的光谱混合或光谱反射率相似。几乎所有非作物类都显示了所有算法的优秀PA和UA。由于非作物类具有独特的光谱响应,与几乎所有作物类相比,非作物类的OA更高。几乎所有分类算法的水的OA最高达到100%。100%OA表明其他类别的水没有混合或分解。由于与亚麻籽的混合较少,休闲地的精确度稍低。一些沙子的像素被误分类为堆积物,一些堆积物的像素被错误分类为沙子。这种混合仅是由于堆积物和沙子的光谱响应相似。在作物类别中,小麦作物获得的最高OA表明与其他作物和大麦类别的混合非常少。亚麻籽作物的UA和PA最低,与稀疏植被、芥菜、其他作物和扁豆作物类别的混淆程度最高。与亚麻籽作物的混淆主要是因为这些种类的光谱特征相似。小麦是作物类别中最容易识别的作物,而亚麻籽则很难识别。具有二次多项式的SVM为亚麻籽作物提供了52.21%PA和63.44%UA,表明52.21%的亚麻籽区域得到了正确识别作为亚麻籽,而63.44%的亚麻籽面积实际上是亚麻籽。另一个例子是,使用6次多项式SVM的甘蔗PA和UA分别为82.24%和75.86%。这些值表明,地面上82.24%的甘蔗区被正确识别为甘蔗,但分类图上只有75.86%的甘蔗区实际上是甘蔗。
小麦、芥末、亚麻籽、木豆、玉米和稀疏植被的一些小部分被错误地归类为其他作物类别。同样,芥末、亚麻籽、玉米、豌豆和其他作物类别的一些部分被错误地归类为稀疏植被。这种错误分类的部分原因是类别之间的光谱相似性,部分原因是领域内的可变性。甘蔗、鸽子豌豆和稠密植被之间的光谱相似性很高。在大麦和扁豆之间观察到的高光谱相似性也造成了混淆,并显示出彼此的错误分类。几乎所有算法都发现,木豆作物中PA之间存在较大差异,UA之间存在较小差异,而甘蔗作物中PA与UA之间的差异较小。这种大的变化是由于光谱相似性和场内变异性造成的。小麦、玉米和休耕地类别的PA和UA之间的差异很小,而几乎所有算法的亚麻籽和豌豆作物的PA和UCA之间的差异很大。使用线性、2-6次多项式、径向基和乙状函数核的SVM,Kc值分别为0.8394、0.8462、0.8551、0.8554、0.8614、0.8638、0.8502和0.8060。使用ML和NDVI分类的其他Kc值分别为0.8402和0.7252。例如,Kc值等于0.8502,表明所获得的分类精度比随机分配像素到类的精度高85%。
4.2. Test for statistical significance in classification accuracy
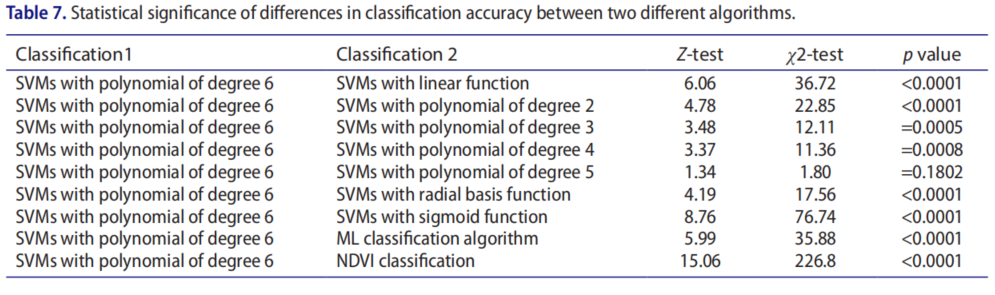
使用McNemar对独立样本的检验来评估分类准确性差异的统计显著性。采用Z检验和χ2-检验检验两种分类结果是否存在显著差异。测试结果的解释基于Z检验,例如,值Z>|1.96|表示95%置信水平下的分类精度存在统计显著差异。
分类结果从统计上表明,除6阶SVM与5阶SVM相比,所有组合的Z值均大于1.96。这意味着所有组合都存在显著差异,但6阶SVMs与5阶SVMs的多项式相比,组合差异不大。具有5次多项式的SVM(Z=1.34,p=0.1802)。使用6级SVM与5级SVM的组合比其他组合更准确。关键的是,与多项式为5的SVM相比,多项式为6的SVM的分类精度提高了0.23%,这在统计上有意义,或者在统计上没有分类精度的差异。使用6次多项式的SVM与使用5次多项式的svM相比,Kc的增加没有统计学意义,Z值为1.34,p值为0.1802。在95%置信水平下,Z值小于1.96。值得注意的是,大麦、扁豆、芥末、木豆、亚麻籽、豌豆和甘蔗的分类精度显著提高。由于作物的不同生长阶段和作物田的管理条件,从视觉上看不太清楚作物的分离情况。分类图上的大多数字段只有一个主要类别,而由于字段内的变异性和某些类别之间的光谱相似性,所有字段都包含一些其他类别的小内含物。Kappa分析用于将分类与随机分类进行比较,随机分类提供了所有大于1.96的Z检验值,但具有6次多项式和5次多项式的SVM的临界值为0.05显著水平。因此,除多项式为6次和5次的SVM外,所有分类在95%置信水平下均明显优于随机分类。表7给出了用于在分类算法之间进行两两比较的Z检验和χ2检验值。
使用多项式为6次和5次的SVM的分类结果明显优于其他算法,但这两种算法在OA中没有显著差异(87.33比87.10%)。其他分类算法与具有不同p值的6次多项式的SVM有显著差异。
具有6次多项式和5次多项式的SVM给出的χ2值为1.80,低于临界值3.841。这意味着χ2-检验接受零假设,表明它们在统计上没有差异。在所有其他组合中,χ2检验拒绝无效假设,因为所有χ2值都大于临界值。通过将SVM与6次多项式和5次多项式相结合得出结论,发现其他分类精度结果的组合存在统计差异。在分类精度的统计分析中,基于标准正态分布的Z检验和基于卡方分布的χ2检验给出了几乎相同的结论。
5. Conclusions
使用LISS-IV数据对农作物进行分类已证明在识别不同作物类别方面是有效的。与其他分类算法相比,具有6次多项式的SVM的性能显示出更好的结果。分类图比较好作物识别和分类。这也可以从分类前进行的可分性分析的类之间的良好分离中看出。OA、Kc和McNemar检验的统计结果表明,与使用LISS-IV数据的其他基于核的SVM、ML和NDVI分类算法相比,具有多项式函数核的SVMs能够提供更好的分类精度。在未来的研究中,将使用所有三个LISS-IV波段的不同组合来选择作物分类的最佳输入变量。它将涉及更复杂的分析,如伽马测试和交叉验证方法,其观点和预期是,它肯定会减少建模者在选择最佳模型输入变量(也包括光学遥感)方面的工作量。