为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便,本文仅注重自己感兴趣的部分。排版对手机端不友好。因为MathType过期,所以文章中的部分公式为图片形式。
在语义分割的基础上,[12]在选出种子点后,通过对比像素间的相似性,实现了实例分割。
[12] first selected iteratively the best “seediness” pixel, based on semantic segmentation architecture, then computed how likely two pixels are to belong to the same object, and then grouped similar pixels together.
原文地址:Semantic Instance Segmentation via Deep Metric Learning
参考文文章:一文介绍3篇无需Proposal的实例分割论文
论文摘要
该论文提出的实例分割的方法是通过计算两个像素属于同一物体概率的大小,然后对相同实例的像素进行分组。该论文中判断相似性基于一个深度全卷积嵌入(embedding)模型,分组的方法是通过深度全卷积置信度模型,选出所有的和种子像素相近的像素。
论文内容
1、Introduction
实例分割是分辨图中的物体,被对其进行分类的一个任务。与物体检测不同的是,不满足于给出一个物体框,而是一个可以代表物体形状的掩模;与语义分割不同的是,不仅仅是给每个像素一个类别标签,并对一类物体中的每一个实例进行区分。(It differs from object detection in that the output is a mask representing the shape of each object, rather than just a bounding box. It differs from semantic segmentation in that our goal is not just to classify each pixel with a label (or as background), but also to distinguish individual instances of the same class.)
常见的方法是:首先使用某些方法[1]实现物体框的检测,然后在每个物体框中进行分割和分类操作。然而这个方法遇到的瓶颈是,当一个物体框中出现多个实例时,便出现了问题。还有一种就是先确定掩模,然后从掩模中获得物体框。(这种方法可以很好地得到确定形状的物体框,例如汽车和行人;但是对于不确定形状的物体,无法进行很好的框定,例如椅子和非轴对称的物体)。
于是,无需物体框(box-free)同样也得到了一定的研究[2][3],这些方法的目的是为了直接预测每个物体的掩模。最常见的做法是对Faster R-CNN的网络结构进行改进,针对每个点,生成一个“中心化”分数用以表示该点属于一个物体实例中心的概率,一个二进制物体掩模和一个物体标签。然而这个方法需要图像中的所有实例都在要进行预测的感受野中,对于可能跨越图像中的许多像素的细长结构而言,这可能是困难的。并且对于一些物体来说,物体的中心是不能确定的。
该论文的方法是计算两个像素属于同一实例的可能性,然后根据可能性大小对像素进行分组。该想法与无监督图像分割的方法[4]相似,但该论文对其进行了明确定义什么是一个正确的分割,即整个物体的空间像素跨度。这避免了是否将一个物体的一部分视为另一个物体的二义性,例如是否将人身穿的衣服识别出来。
该文中解决学习相似性问题使用的是一个深度嵌入模型,这与之前的FaceNet[5]较为相似。后者是用于分辨两个物体框是否属于同一实例,前者在考虑局部语境的情况下,预测像素之间的相似关系。
与无监督实现图像分割方法不同的是,没有使用基于谱或图的分割方法。而是在嵌入空间中计算一组个种子点,可以实现为张量的乘法。为了得到一个较好的种子点,该论文设计了一个单独的网络结构用以判断某像素是一个好种子点的概率,称为每个像素的“种子分数”。这类似于现有方法中使用的“居中”分数,除了我们不需要识别对象中心; 相反,在这种情况下,seediness分数是像素相对于其他像素的“典型性”的量度。实践中我们可以得到一个结果,仅使用种子分数前100的种子点便可以很好的覆盖整个图像。
2、Related Work
最常见的例分割方式为检测-分割方法,例如获得COCO2015冠军的MNC[6]。这个物体框的位置基于预测的掩模可以进行细化,例如[6]进行了两次迭代,[7]迭代的次数是任意个次数。FCIS[8]利用一个掩模推荐,产生了一个位置敏感的分数。还有一些其他的方法,但是这些利用滑动窗口的方法均采用了图像金字塔的方法解决多尺寸下的图像,而也有工作利用特征金字塔来代替图像金字塔的。
以上的方法均是在整个图像上进行的,但也有工作按顺序运行,一次提取一个对象实例。 [9]是这种方法的例子。它使用CNN提取特征,然后在每个步骤使用RNN“发射”二进制掩码(对应于对象实例)。RNN的隐藏状态是图像形状并且跟踪图像中的哪些位置已经被分割。 这种方法的主要缺点是速度慢。而且,由于隐藏状态序列可能消耗大量存储器,因此缩放到大图像是很麻烦的
还有一种方法是基于水域分割的,基础的使用的是一个能量函数,也有工作将能量函数换成一个实例边界的图。但是水域分割技术不能将断开的区域分组成单个实例(例如,如果对象被封堵器分割成两个部分,例如图 中被其骑车者遮挡的马)。因此需要一个更加具有普适性的聚类函数,于是有工作提出对每个像素预测物体分数并产生一个一维的embedding。它们首先在对象热图上设置阈值以生成二进制掩码,然后计算掩模内所有像素的嵌入的一维直方图,执行NMS以找到模式,然后将掩模中的每个像素分配给其最接近的质心。
该论文与[10]很像,但是有以下几点不同:
⑴ 学习相似性的时候,损失函数不同;
⑵ 产生掩模时基于识别相似空间中的吸引感兴趣区域的方法,代替贪婪聚类;
⑶ 对每个像素学习了一个维的embedding,而不是一维的。
3、Method
3.1、Overview of our approach
该方法基于实现语义分割的网络,经过增加以下两个不同形式的输出“head”,用于实现实例分割。
⑴ 第一个用于对每个像素产生一个embedding 向量;
⑵ 第二个用以对每个像素产生类别,以及这个像素是种子点的置信度。
具体的网络结构如下图所示:
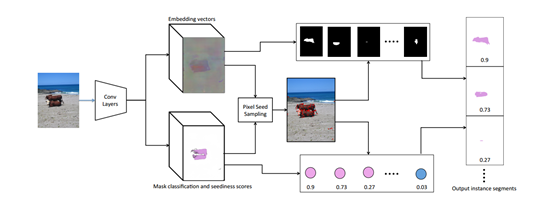
图1 实现实例分割的网络结构图
3.2、“嵌入”模型(Embedding model)
首先通过学习embedding 空间,使得属于同一实例的像素相距较近,不同实例的像素相距较远(包括背景)。Embedding head将由一个卷积特征提取子提取出的特征图作为输入,输出一个张量,其中h是图像的高度,w是图像的宽度,d是图像embedding的维度。并假设图像中的像素p对应的d维embedding为
。
有了两个像素的embedding,假设维p和q,可以计算相似性为:
可以看到,假如p和q是embedding 空间中相距较近的两个像素点,便可以得到,较远的两个像素点可以得到
。
该训练过程使用的损失函数为:
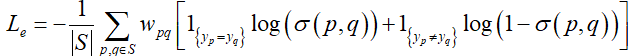
其中,S是图中像素的集合,是像素p所属的实例的标签,
是两个像素间的损失权重,归一化权重为
。
在训练阶段,先是在所有的实例中随机抽样K个像素点,然后对于每一对像素计算是否为同一实例,结果为1代表是同一实例,结果为0代表不是同一实例。具体实现如图2所示:

图2 相似性计算的步骤
然后需要对集合最小化交叉损失函数,一些得到的embedding样例如图所示:

图3 RGB空间的64维的embedding向量
3.3、掩模生成(Creating mask)
得到embedding空间之后,运用以下方法进行相似性分析:通过选出的种子点“seed point”计算与其他像素之间的相似性,并设置阈值![]() ,通过设置阈值的大小可以获得不同区域范围的像素,该实验使用了
,通过设置阈值的大小可以获得不同区域范围的像素,该实验使用了![]() 三个值。
三个值。
实现的过程:先计算对应的张量A,然后计算
的张量B(表示K个种子点的embedding),然后计算
,通过对比距离矩阵获得足够相似的像素点。通过选择一个种子点后实现实例的分割的具体表现为图4所示:

图4 种子点生长的实例
其中红点为随机在图像中选择的实例的种子点。
本文中使用了一个seediness map ,可以得知一个像素作为种子点的能力。只要获得这个
,便可以根据所需进行选择种子点。文中为了提高嵌入空间多样性,在embedding空间中计算每个点与已经得到的种子点的距离,选择一个最远的。具体的算法可总结为:
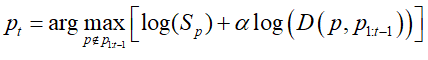
其中,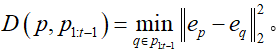 。
。
通过以上算法迭代选择新的种子点,从而后选出的种子点远离原来的种子点。与非极大值抑制不同,该方法鼓励嵌入空间的多样性,而不仅仅是空间多样性。
3.4、分类模型和种子模型(Classification and seediness model)
掩模分类的输入为从一个卷积特征提取子中得到的特征图,输出张量,其中C代表类别的数目,标签0代表背景。选择种子点的标准是:在物体内部的像素相对于边界的像素是好的种子点。
在每一个批量中,每幅图像仅评估大约 10 个种子,并且是随机选取的,学习几个这样的模型,每个带宽一个。带宽越宽,对象越大。在某种程度而言,接收最高得分的带宽就是模型将它的估计传达给实例大小 (相对于嵌入空间中的距离) 的方式。并假设像素p的掩模为。如果生成的掩模与实际的物体的重叠处高于设定的
值,则认为得到了好的掩模,并将真实的掩模的标签给该点。相反的话,当达不到阈值的时候,则设置为背景。分类模型是一个全卷积的,但是只计算了
个交叉损失函数,其中
是物体的个数,
是种子点的个数。种子点的损失函数为:
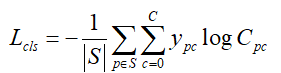
其中,代表像素
属于类别
的可能性。并假设
是在阈值
下的概率,那么有像素
的种子度为:
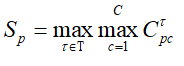
只要得到了最好的种子点,便可以得到对应最好的阈值
和标签
:
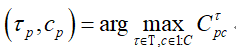
对应的置信度为:
3.5、共享的整幅图片的卷积特征(Shared full image convolutional features)
本文基于DeepLab v2[11],可以实现必要的语义分割。然后将两个head进行结合起来使用,如下所示:
其中,是嵌入损失,
是分类损失,
是一个调和因子。训练从没有分类/种子预测开始,也就是说
为 0,并且随着嵌入的稳定发展,
更新到 0.2。
3.6、共享的整幅图片的卷积特征(Shared full image convolutional features)
本文以不同尺度 ( 0.25,0.5,1,2 ) 对主干进行评价,并将评价结果反馈给种子和嵌入头。
4、实验结果
4.1、实验说明
与之前的工作相同,IoU的阈值设置三个,同样使用了AP和mAP的评价标准。
4.2、预处理
数据增强处理的增强处理:
⑴ 随机转动;
⑵ 随机放缩:放缩比例为;
⑶ 随机裁剪:在划分的100个窗口中选择出实例最多的窗口集合;
⑷ 随机翻动:水平地随机翻转训练图像;
4.3、实验结果

图5 一些分割样例
在PASCAL VOC上进行的对比实验结果为:

图6 对比实验结果
经过对比不同的,可以得到下表:

图7 对比表
下表为对比的种子点选择的个数:

图8 种子点的个数
论文的优点
⑴ 为每个像素学习种子得分,这个分数告诉我们像素是否是扩展 mask 的良好候选,并只需要一次简单的拓展。
参考文献
- Dai J, He K, Sun J, et al. Instance-Aware Semantic Segmentation via Multi-task Network Cascades[J]. computer vision and pattern recognition, 2016: 3150-3158.
- Liang X, Lin L, Wei Y, et al. Proposal-Free Network for Instance-Level Object Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2978-2991.
- Pinheiro P H, Lin T, Collobert R, et al. Learning to Refine Object Segments[J]. european conference on computer vision, 2016: 75-91.
- Felzenszwalb P F , Huttenlocher D P . Efficient Graph-Based Image Segmentation[J]. International Journal of Computer Vision, 2004, 59(2):167-181.
- Schroff F, Kalenichenko D, Philbin J, et al. FaceNet: A unified embedding for face recognition and clustering[J]. computer vision and pattern recognition, 2015: 815-823.
- Dai J, He K, Sun J, et al. Instance-Aware Semantic Segmentation via Multi-task Network Cascades[J]. computer vision and pattern recognition, 2016: 3150-3158.
- Liang X, Wei Y, Shen X, et al. Reversible Recursive Instance-Level Object Segmentation[J]. computer vision and pattern recognition, 2016: 633-641.
- Li Y, Qi H, Dai J, et al. Fully Convolutional Instance-Aware Semantic Segmentation[J]. computer vision and pattern recognition, 2017: 4438-4446.
- Ren M, Zemel R S. End-to-End Instance Segmentation with Recurrent Attention[J]. computer vision and pattern recognition, 2017: 293-301.
- Newell A, Huang Z, Deng J, et al. Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. neural information processing systems, 2017: 2277-2287.
- Chen L, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
- Fathi A, Wojna Z, Rathod V, et al. Semantic Instance Segmentation via Deep Metric Learning.[J]. arXiv: Computer Vision and Pattern Recognition, 2017.