GANs大家是比较熟悉的网络结构,adversarial attacks 也不是很新的概念了。近期的工作有涉及到adversarial attacks,故整理一下学习的内容。
Adversarial Attacks
对抗攻击样本:一张正常的大熊猫图片(左图)在被加入噪声(通常为人类无法察觉的噪声)后生成对抗样本(右图),会使得神经网络分类错误,并被神经网络认为是一张长臂猿图片,然而人并不能察觉到这种变化。注:此种演示示例为规避攻击(Evasion attacks),是四种常见攻击手段中的一种。其他三种为提取式攻击(Extraction attacks),推理攻击(Inference attacks),投毒攻击(Poisoning attacks)。其中,投毒攻击与规避攻击为对训练数据集的攻击,也是此次我们项目使用的重点。
规避攻击:攻击者通过插入一个细微的扰动(如某种形式的噪声),并转换成某个机器学习模型的输入,并使之产生分类错误。
示例:

根据不同的分类标准,对抗攻击(如何生成对抗样本)有着以下几种分类方式,从攻击环境或者按照攻击者具备的能力来说,可以分为:
- 白盒攻击(White-box attacks):白盒攻击假定攻击者可以完全了解他们正在攻击的神经网络模型的结构和参数,包括训练数据,模型结构,超参数情况,层的数目,激活函数,模型权重等。能在攻击时与模型有交互,并观察输入输出。
- 黑盒攻击(Black-box attacks):黑盒攻击假定攻击者不知道他们正在攻击的神经网络模型的结构和参数,能在攻击时与模型进行交互,只知道模型的输入输出。白盒攻击样本可以通过一些方法转换成黑盒攻击的方式。
- 灰盒攻击:介于黑盒攻击和白盒攻击之间,仅仅了解模型的一部分。(例如仅仅拿到模型的输出概率,或者只知道模型结构,但不知道参数)。
- 真实世界攻击(Real-world attacks):在真实的物理世界攻击。如将对抗样本打印出来,用手机拍照识别。
攻击者对计算机方面的攻击可以使用三个指标进行衡量,也就是CIA(confidentiality,integrity,availability),分别为:
- 机密性:机密性可以等同私密性,可以按照保密性来理解,例如,机器学习算法在训练模型的时候,可能数据是具有敏感信息的,那么这时候在训练模型的时候如何保证机密性或者私密性就显得尤为重要了。
- 完整性:完整性是说保证模型和数据的完整性,不能让攻击者对数据进行破坏。
- 可用性:可用性是说需要保证模型的可用性,例如,传感器在探测到前方的障碍很复杂时,要能够有解决方案,而不是直接宕机,停止工作。
同时,还有目的性更强的毒性样本:训练深度神经网络(DNNs)往往需要大量的训练数据,这些数据有时可能由不可信的第三方来源所提供。这些不可信的数据可能会对模型的训练带来严重的安全威胁。典型的威胁之一就是基于投毒的后门攻击,它可以通过投毒一小部分训练样本(即:给这部分样本的图像加上指定的触发器,并把它们的标签改为某个目标类别),来向模型中注入后门(即:在训练过程中,模型能够学到触发器和目标类别之间的映射)。一般地,一个后门模型可以很好地预测干净样本,并且能将任何带有触发器的毒性样本预测为目标类别。
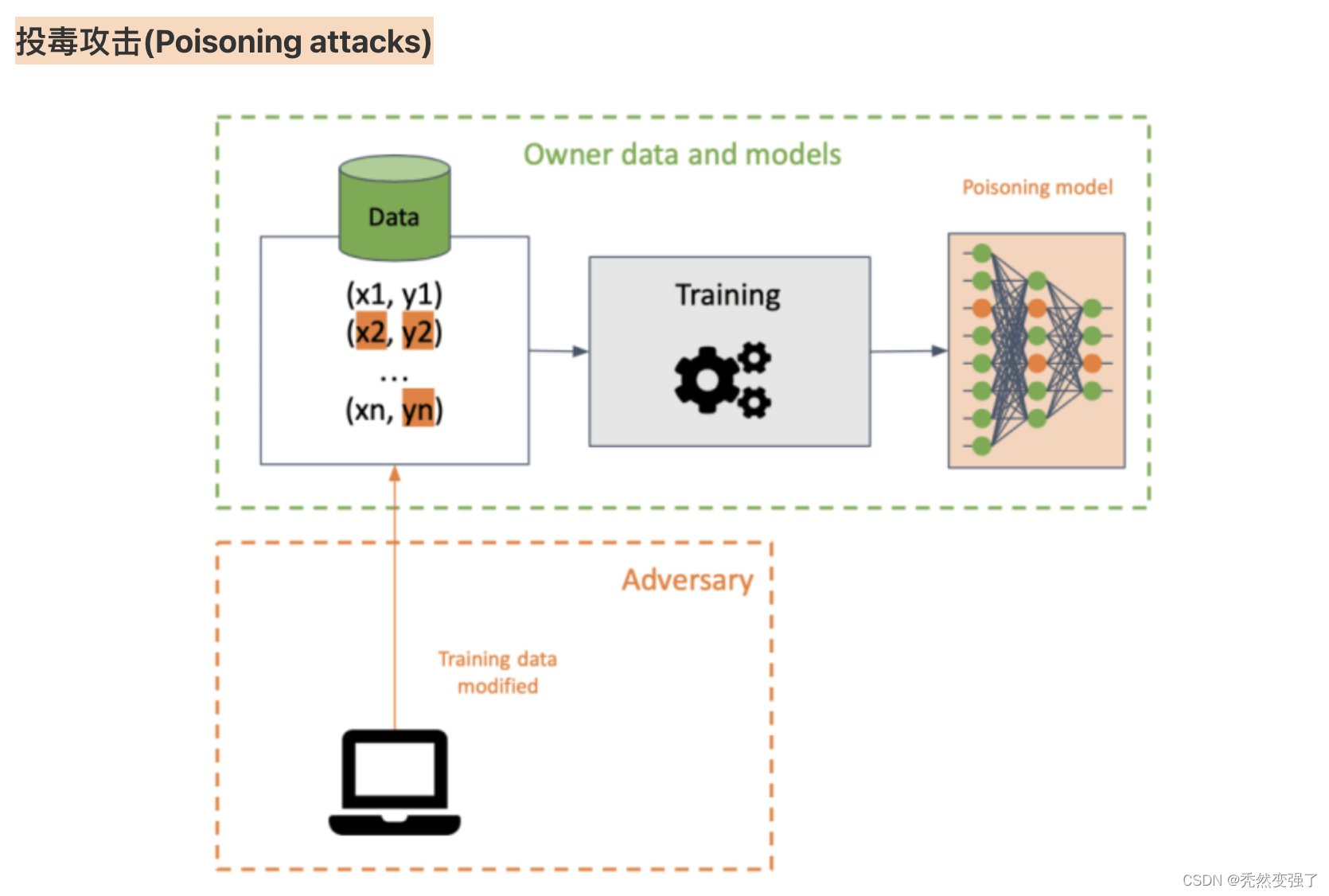
投毒攻击示例:投毒攻击技术是指攻击者在训练数据集中插入损坏性数据,以在训练的过程中破坏目标的机器学习模型。计算机视觉系统在面对特定的像素模式进行推理时,会被此类数据投毒技术触发某种特定的行为。当然,也有一些数据投毒技术,旨在降低机器学习模型在一个或多个输出类别上的准确性。
示例:
Adversarial Learning
对抗学习是一个机器学习与计算机安全的交叉领域,旨在在恶意环境下(比如在对抗样本的存在的环境下)给机器学习技术提供安全保障。对抗训练是提升深度网络对抗鲁棒性(即,抵御对抗样本欺骗的能力)的重要方式之一。对抗训练的基本思想就是在网络训练的过程中,不断生成并且学习对抗样本。比如根据极小极大公式,在内层通过最大化损失函数来寻找对抗样本,然后在外层学习对抗样本来最小化损失函数。通过对抗训练而得的神经网络具有对抗鲁棒性。
对抗学习的参照公式(即稳健性优化公式):
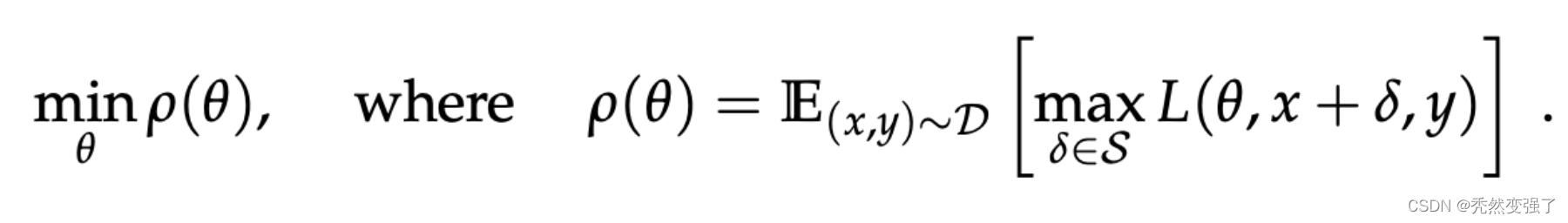
“max函数指的是,我们要找到一组在样本空间内、使Loss最大的的对抗样本(该对抗样本由原样本x和经过某种手段得到的扰动项r_adv共同组合得到)。这样一组样本组成的对抗样本集,它们所体现出的数据分布,就是该中括号中所体现的。
min()函数指的是,我们面对这种数据分布的样本集,要通过对模型参数的更新,使模型在该对抗样本集上的期望loss最小。*也即最小化是在一个固定的(通常是小范围波动的)取样里面最大的经验损失。”
核心思想:通过对抗样本来增强分类器应对输入扰动的稳健性?
对抗loss:

为什么使用对抗loss:
即使我们最终想要的是传统的风险最小化,还是有一种情况让我们更愿意使用对抗风险。因为我们很难做到从真实分布中独立同分布地采样数据。事实上,我们采用的任何数据收集方法都是带有一种经验性的倾向来从真实分布中获取数据,很容易会忽略某些维度,尤其是当它们对人类来说是”显而易见”的。(以上节选自【8,10】)
使用对抗策略训练网络模型
- 使用对抗样本的对抗训练
- 基于松弛的稳健训练
- 在NLP领域,类似的对抗训练也是存在的,不过NLP中的对抗训练更多是作为一种正则化手段来提高模型的泛化能力
步骤一: 往属于x里边注入扰动Δx,Δx的目标是让L(x+Δx,y;θ)越大越好,也就是说尽可能让现有模型的预测出错;
步骤二: 当然Δx也不是无约束的,它不能太大,否则达不到“看起来几乎一样”的效果,所以Δx要满足一定的约束,常规的约束是‖Δx‖≤ϵ,其中ϵ是一个常数;
步骤三: 每个样本都构造出对抗样本x+Δx之后,用(x+Δx,y)作为数据对去最小化loss来更新参数θ(梯度下降);
步骤四: 反复交替执行1、2、3步。
对于CV任务
对于CV任务来说,一般输入张量的shape是(b,h,w,c),这时候我们需要固定模型的batch size(即b),然后给原始输入加上一个shape同样为(b,h,w,c)、全零初始化的Variable,比如就叫做Δx,那么我们可以直接求loss对x的梯度,然后根据梯度给Δx赋值,来实现对输入的干扰,完成干扰之后再执行常规的梯度下降。
对于NLP任务
原则上也要对Embedding层的输出进行同样的操作,Embedding层的输出shape为(b,n,d),所以也要在Embedding层的输出加上一个shape为(b,n,d)的Variable,然后进行上述步骤。但这样一来,我们需要拆解、重构模型,对使用者不够友好。不过,我们可以退而求其次。Embedding层的输出是直接取自于Embedding参数矩阵的,因此我们可以直接对Embedding参数矩阵进行扰动。这样得到的对抗样本的多样性会少一些(因为不同样本的同一个token共用了相同的扰动),但仍然能起到正则化的作用,而且这样实现起来容易得多。
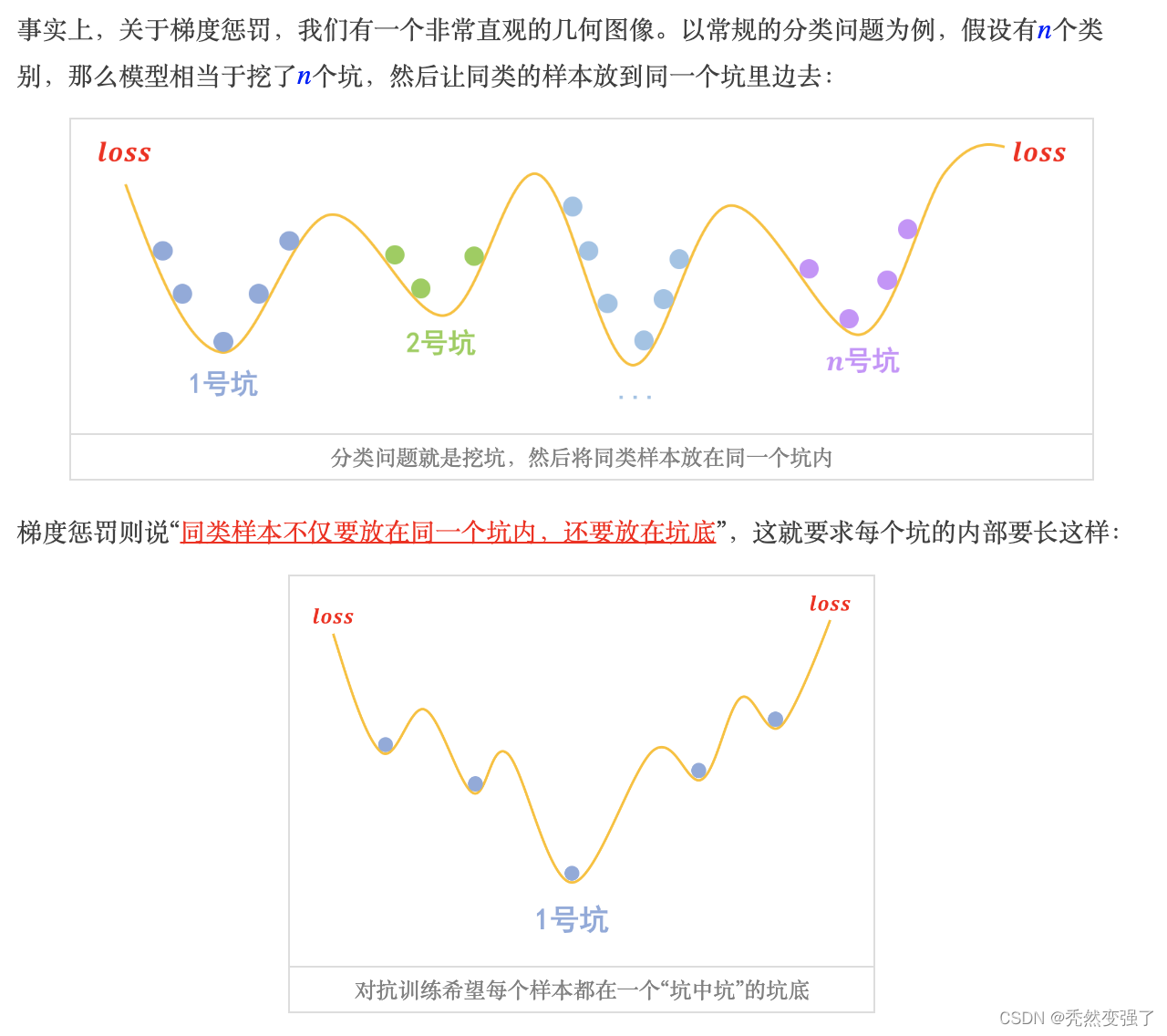
对抗学习与梯度惩罚:
此处加入苏剑林老师对于梯度惩罚之于对抗学习策略的理解,以及的推导过程
故,我们对于理解对抗性的扰动,理解为正则化,甚至于理解为额外的梯度惩罚,是一种更符合符号表达的说法。

个人认为,在防御数据引起的攻击时,主要的手段还是落在通过仿真拟合真实世界的样本,使模型的鲁棒性提高,进而使得模型健壮不会受到outliner的严重影响。对抗性扰动在不同干净样本之间起到泛化的作用。
参考内容:
【1】机器学习中火爆的对抗学习是什么,有哪些应用?
【2】对抗训练浅谈:意义、方法和思考
【3】What Is Adversarial Machine Learning? Attack Methods in 2023
【4】Adversarial attacks in machine learning: What they are and how to stop them
【5】对抗学习概念、基本思想、方法综述
【6】NeurIPS 2022|知识蒸馏想要获得更好的性能?那就来一个更强的教师模型吧!
【7】对抗性机器学习的初学者指南
【8】对抗学习-Chapter1:介绍
【9】Adversarial Robustness - Theory and Practice
【10】对抗学习-Chapter4:对抗训练&求解外部最小化问题
【11】【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
【12】