Towards Deep Learning Models Resistant to Adversarial Attacks
论文URL:
https://arxiv.org/pdf/1706.06083.pdf
论文代码:
https://github.com/MadryLab/mnist_challenge
论文Key idea
本文提出了对抗机器学习领域里面鼎鼎大名的Min-max最优化框架,通过这个框架可以将目前对抗手段和防御手段统一囊括进来。然后作者尝试去解决该min-max的问题,但是该问题太复杂了,于是在基于对对抗样本的loss是稳定的、集中的观察基础上,提出min-max的近似解法:使用PGD方法产生对抗样本然后训练。作者发现,通过这种min-max近似解法产生的防御模型的鲁棒性超级棒,可以抵御目前所有的基于梯度的攻击样本。
论文细节
符号记号
:每个样本都是d维的向量
:每个样本的label都是[1…k]的某个数
:样本和标签的所在的联合概率分布
:神经网络的损失函数,可以是交叉熵误差或最小二乘误差等,
神经网络的参数。
:平均损失
:
是所有允许的扰动,这些扰动满足一定的范数约束,例如
。
: 对抗扰动
最优化观点看待对抗鲁棒性
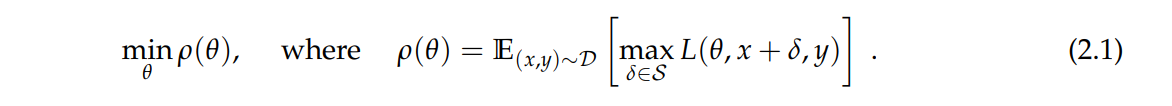
这是一个Min-max的目标函数,最里层的目标函数
是无目标标签攻击者的目标函数,它的物理意义就是寻找合适的
使得损失函数在
这个样本点上的函数越大越好,这样才能让模型在它自己正确的标签上的损失特别大,从而导致正确标签对应的logit很小。我们可以使用单步的
或迭代的
等方法去寻找对抗样本。
外层的 就是防御者的目标函数,它们的目的是为了让模型在遇到对抗样本的情况下,整个数据分布上的损失的期望还是最小,如果能做到这一点,那么再遇到对抗样本的时候也不用担心,因为这种对抗样本不能产生很大的损失值。这个可以通过先解决内层训练找到所有训练样本的对抗样本,然后用对抗样本替换原样本进行retrain 来完成。
为啥说它是一个框架一样的东西呢?
首先,因为分别解决里层的 和外层的 可以有不同的方法,而目前的所有研究工作都可以看做是研究怎么去解决这两个子问题的。
第二点,这个目标函数其实给了一种可以量化的标准来衡量一个模型的鲁棒性:如果最后的损失都特别小,那么说明这个模型的鲁棒性一定会很好。
怎么解这个问题
式子(2.1)看起来的确是很完备,但是它很不好解哇。因为内层的max和外层的min都是非凸的。但是作者实验发现,内层的max问题有一个很好的性质:尽管满足条件的对抗样本有千千万,但是这些对抗样本的损失函数值特别集中。
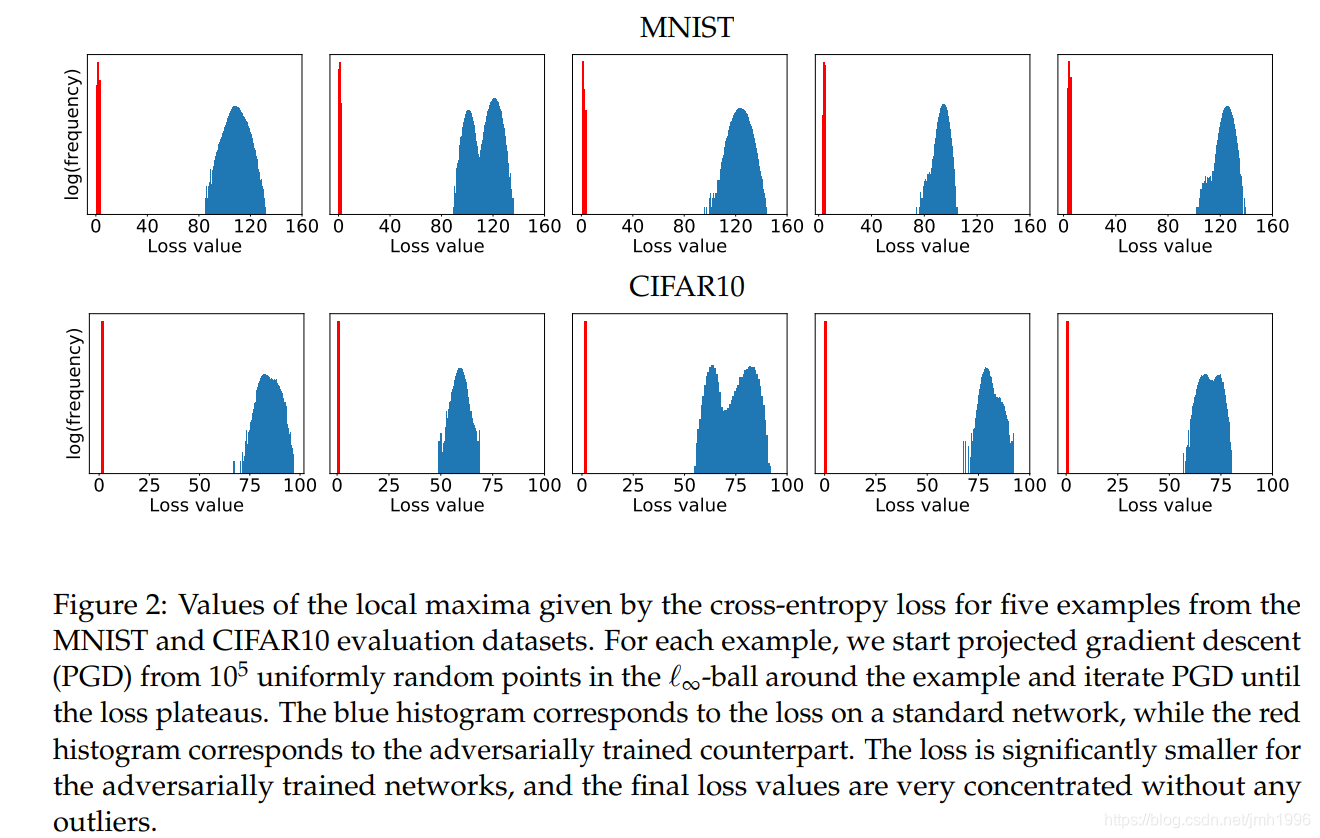
就像上图显示的那样,蓝色的区域是网络标准训练的loss的直方图,而红色的那根线是对抗训练时(把对抗样本丢到网络里面训练)的loss的值的直方图。从直方图可以看出,loss是很集中的,基本上就是一根竖线了。这个图的产生方式是:从Mnist和Cifar10随机选5个图片,然后使用不同的初始方向产生
个对抗样本,然后再收集正常训练的对抗训练的loss的值。
作者还发现,这些对抗样本是很不相同的:他们基本上都是相互垂直的。而且作者还发现,原来的子空间解释对抗样本的观点不太正确,因为他们还发现了有些对抗样本与梯度方向的夹角呈钝角。
基于这些发现,作者认为:通过PGD方法找到的对抗样本进行训练使得在这些对抗样本上神经网络的loss很小,那么这个神经网络也就可以抵抗其他的对抗样本。尽管这些对抗样本可能跟PGD方法找到的对抗样本很不一样,但是它的loss是相似的,既然神经网络可以让PGD对抗样本的值很小,那么当遇到其他对抗样本,它的loss也不会高的那里去。
这里的PGD就是projected gradient descent,可以看做是迭代FGSM的一般化方法。
论文的其他部分就是为了验证这一点了。
