adversarial attack
动机
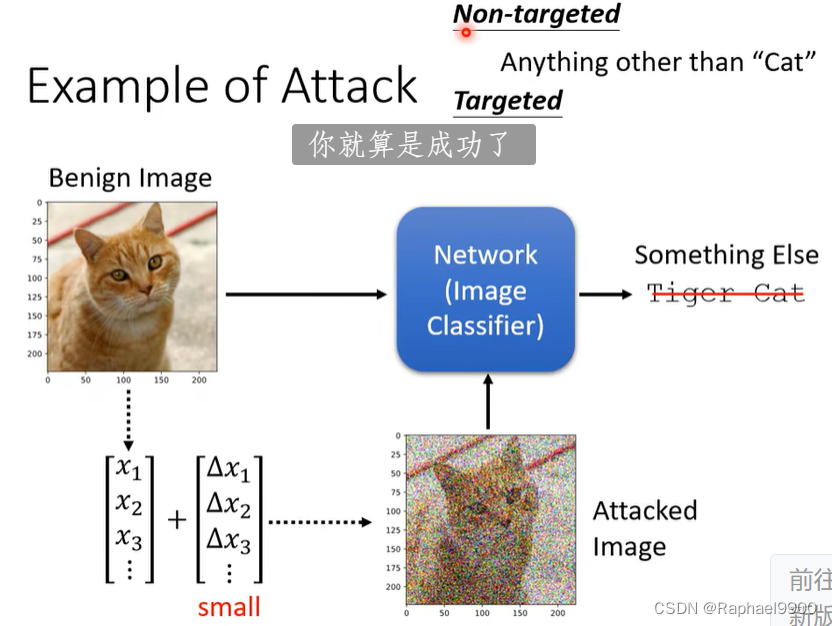
你训练了很多神经网络。我们试图在现实世界中部署神经网络。网络对于为愚弄它们而构建的输入是否具有鲁棒性?对于垃圾邮件分类、恶意软件检测、网络入侵检测等非常有用。
一、adversarial attack
分类:


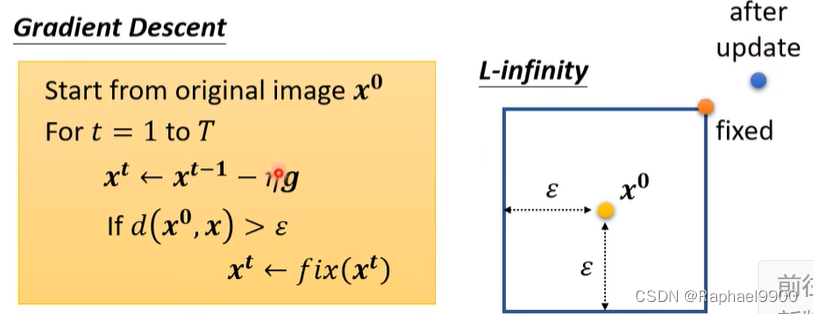
计算两种攻击的Loss
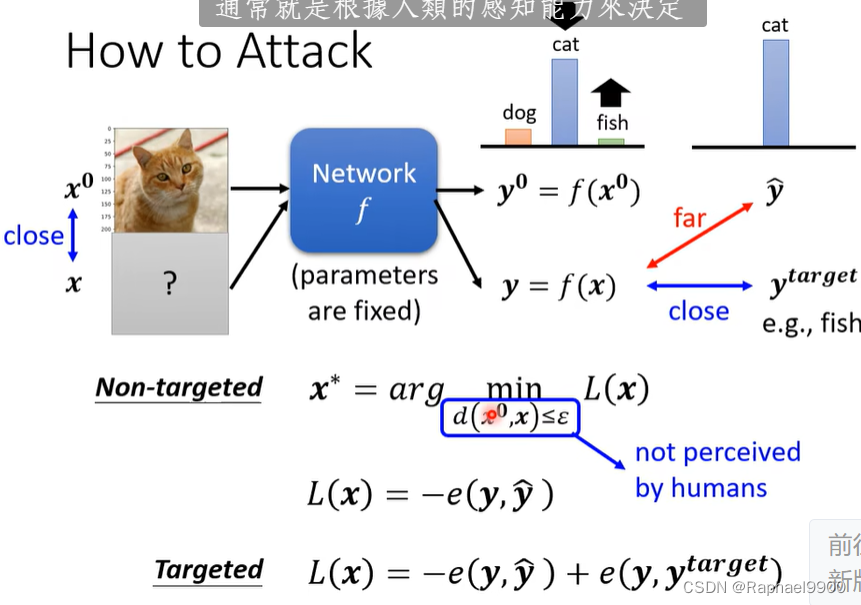
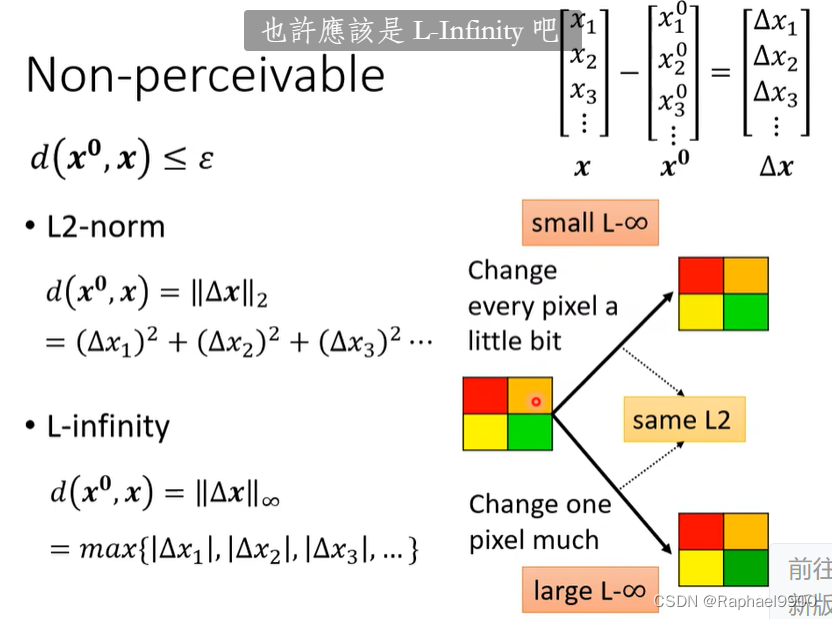
用以下来计算两张图片的距离:下面两个方法都要小。

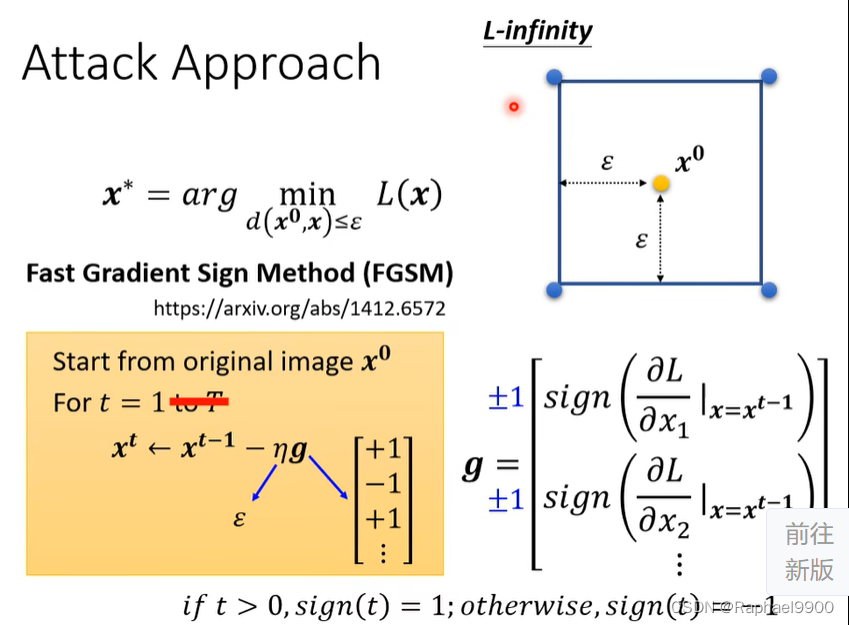
sign函数里,如果值大于0为1,小于0为-1.
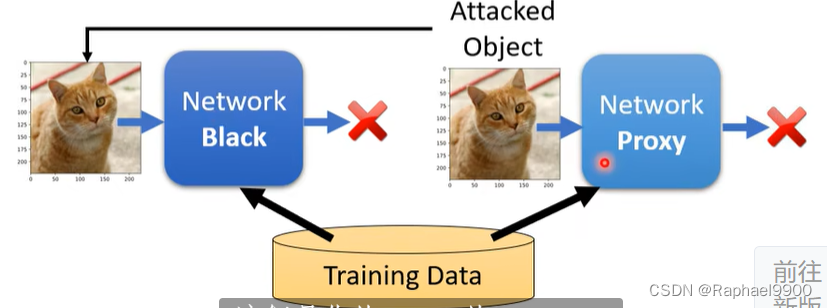
在之前的攻击中,我们知道网络参数,这被称为白盒攻击。您无法在大多数在线API中获取模型参数。如果我们不发布模型,我们安全吗?不会,因为黑盒攻击是可能的。
如果你有目标网络的训练数据,自己训练一个代理网络,使用代理网络生成被攻击的对象
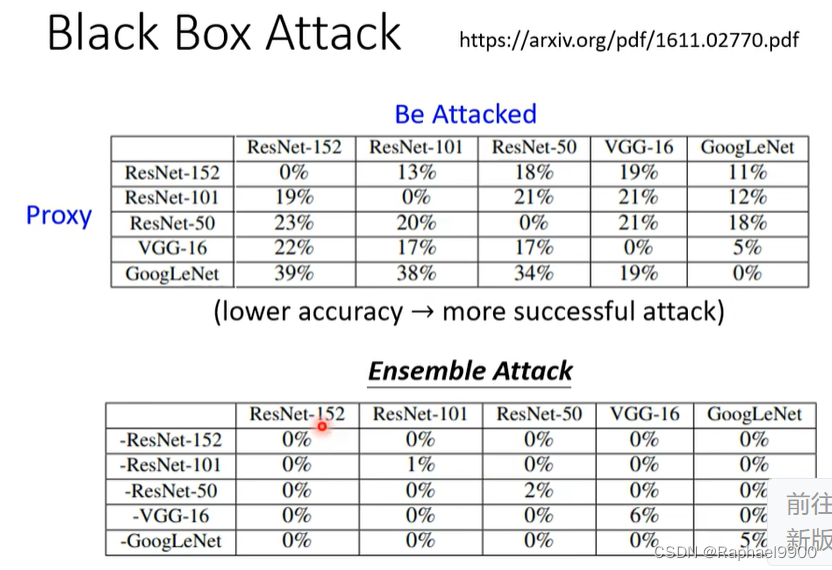
黑箱攻击容易成功
改变一个像素:

同一个地方的噪声能够攻击很多图片

语音和NLP上的攻击:
 真实世界的攻击:
真实世界的攻击:

攻击者需要找到超越单一图像的扰动。
摄像机不可能准确捕捉到扰动中相邻像素之间的极端差异。
希望制作主要由打印机可再现的颜色组成的扰动。


寄生攻击方法:
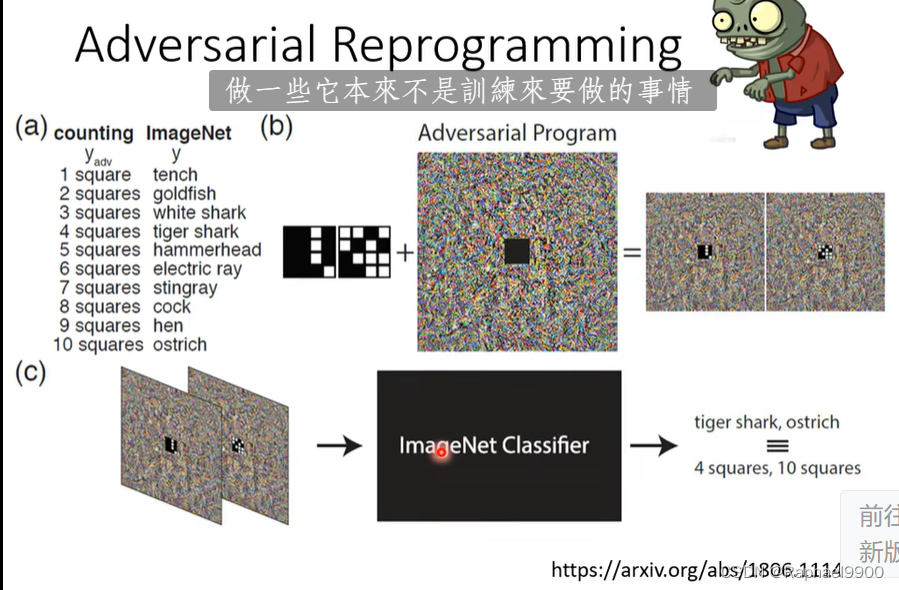
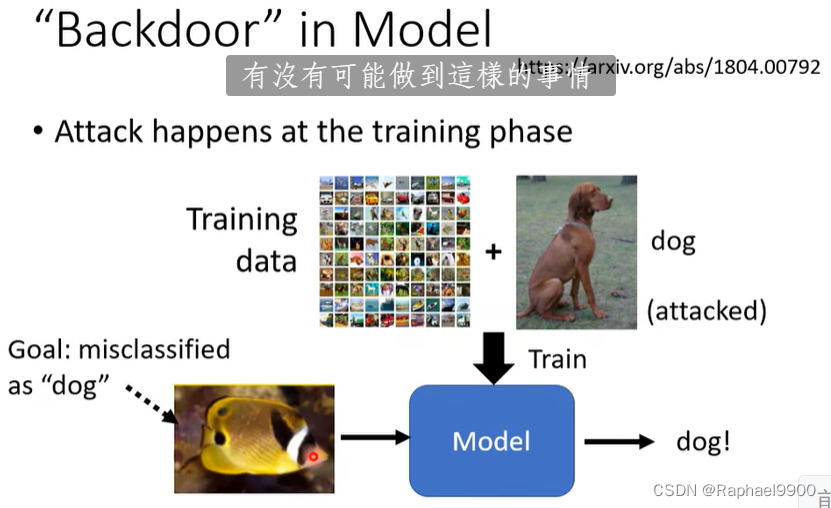
训练的时候攻击:
防御
主动防御和被动防御
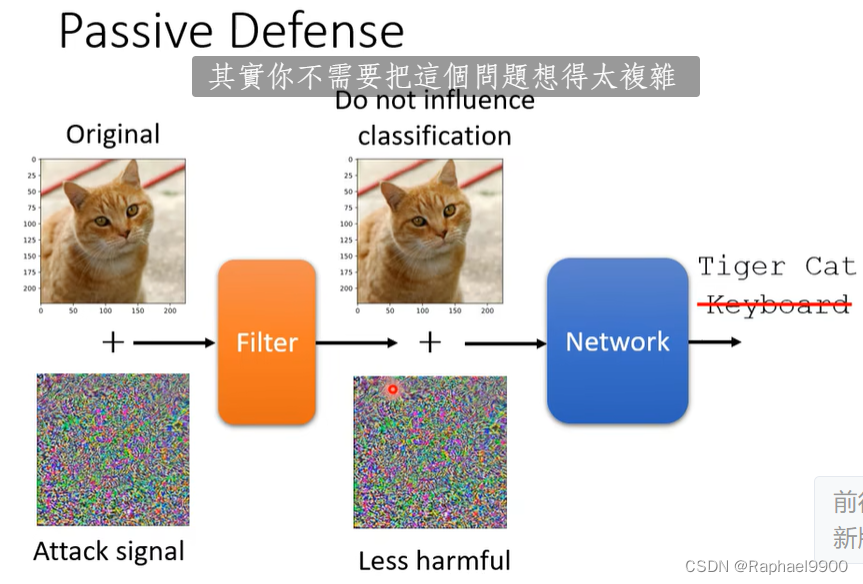
图片做点模糊化就行

压缩、generator

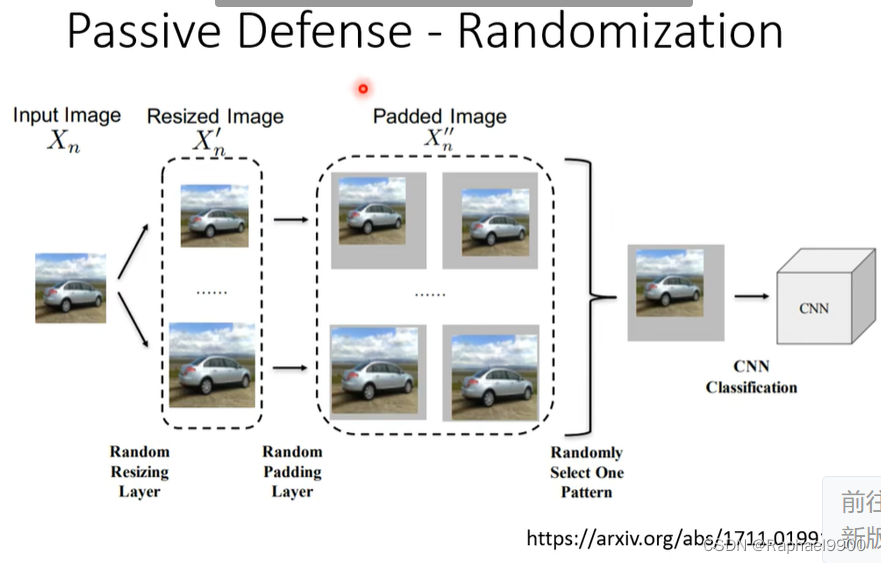
模糊化会被很容易破解,那假如随机性就好了(任意改变)
找漏洞填补:

问题:不一定能挡住新攻击,需要很大的运算资源
二、evasion attacks
一个有效的对抗样本应该满足什么?
与袭击目标高度相关
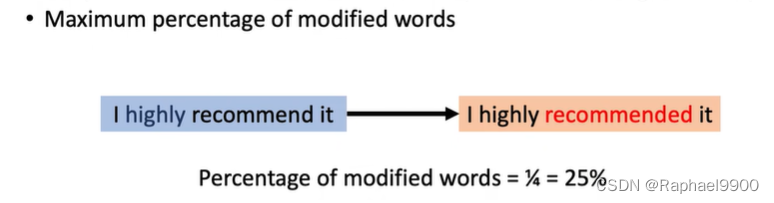
原始样本和扰动样本之间的重叠
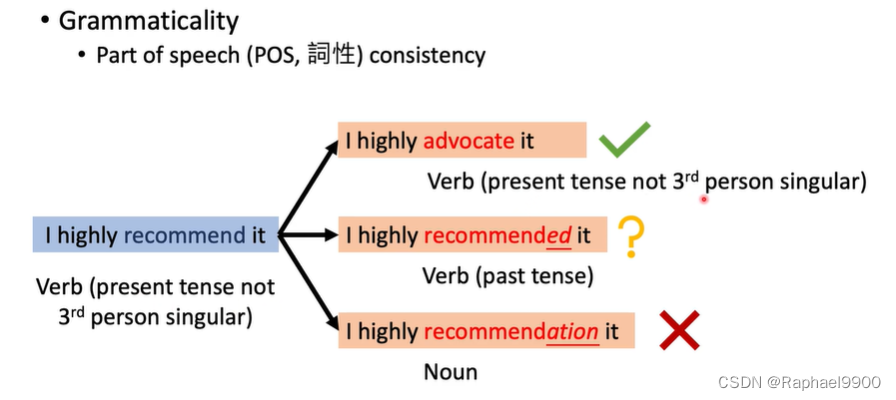
扰动样本的语法性
语义保持

流利程度由预先训练的语言模型的困惑程度来评分(PPL越小出现情况越高)

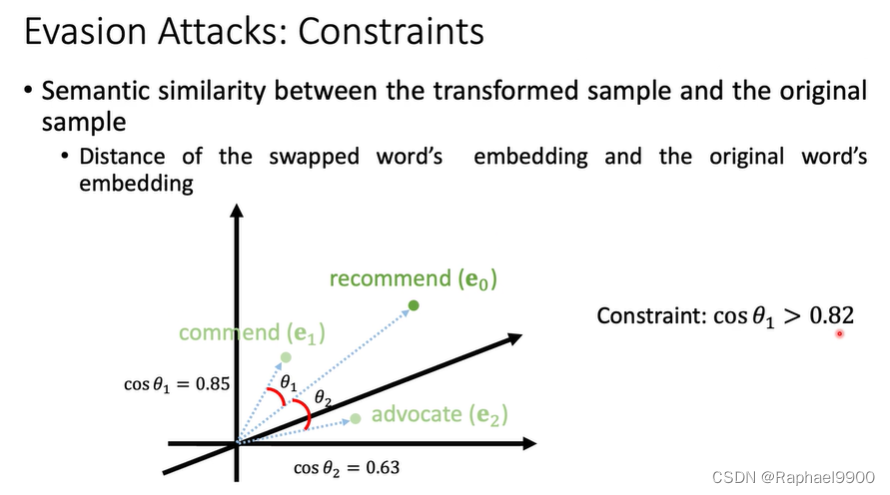
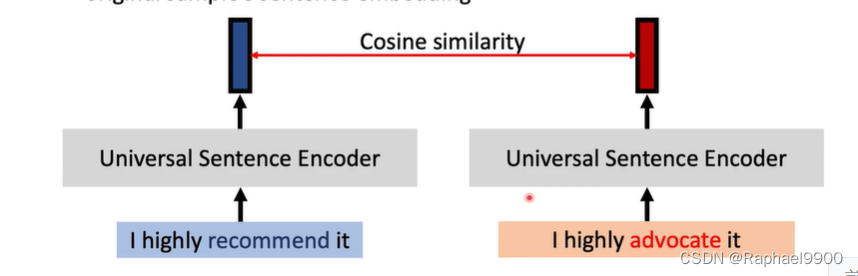
转换样本和原始样本之间的语义相似性
交换单词嵌入和原始单词嵌入的距离
如何选择这个门限?
三、搜索方法

规避攻击:搜索方法
找到实现目标和满足约束的扰动
贪婪搜索
单词重要性排序的贪婪搜索(WIR)
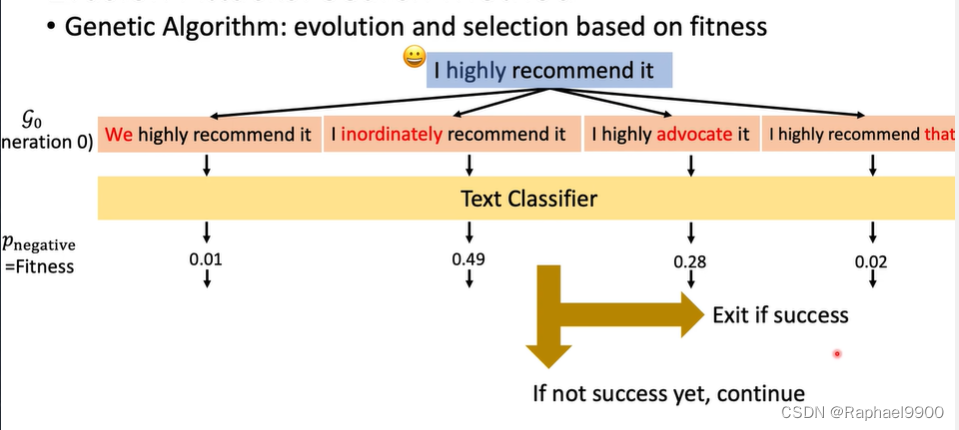
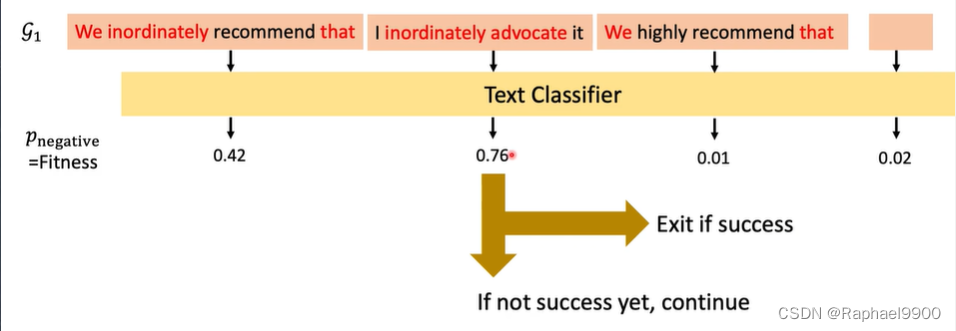
遗传算法
贪婪搜索
对每个位置的每个转换进行评分,然后按照分数递减的顺序替换单词,直到预测翻转
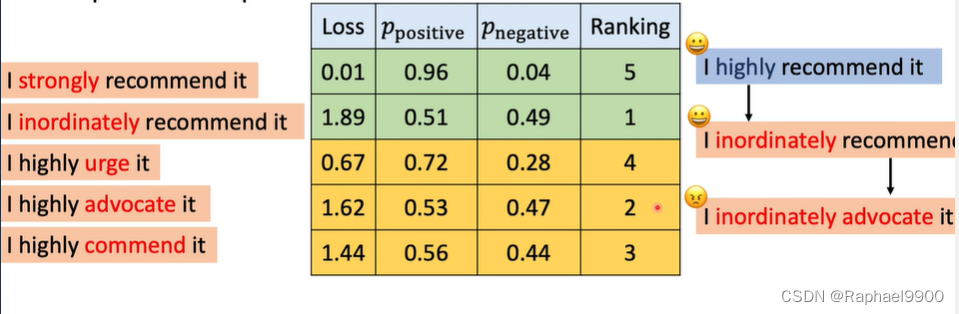
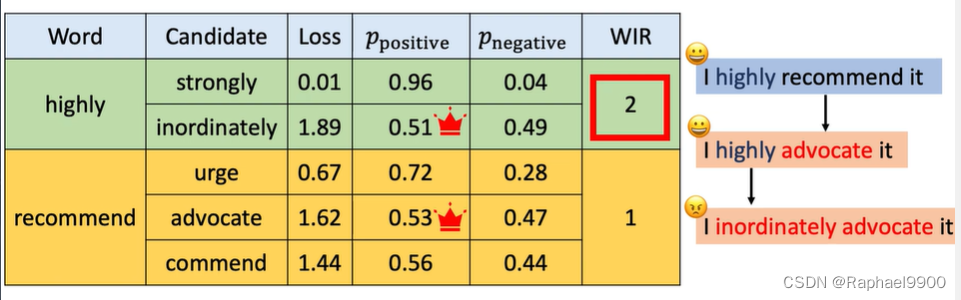
单词重要性排序的贪婪搜索(WIR)
第一步:给每个单词的重要性打分;第二步:从最重要的单词到最不重要的单词进行交换

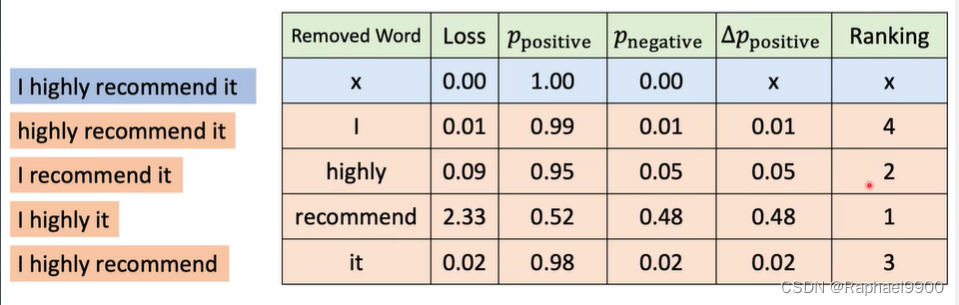
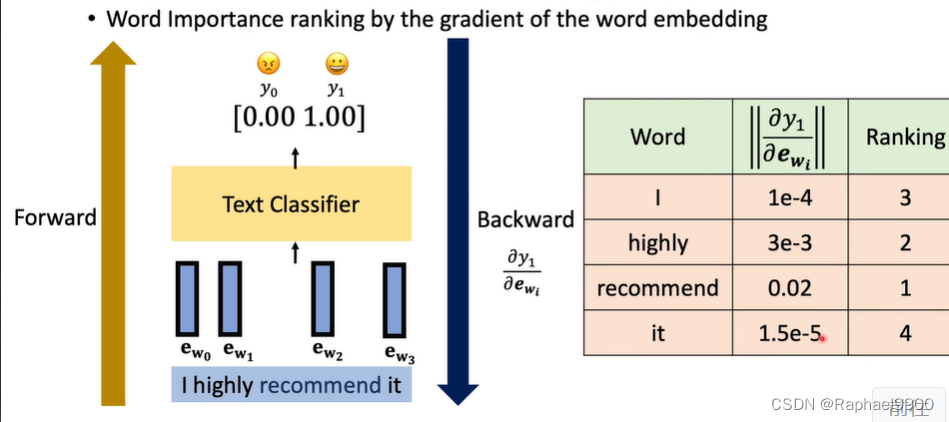
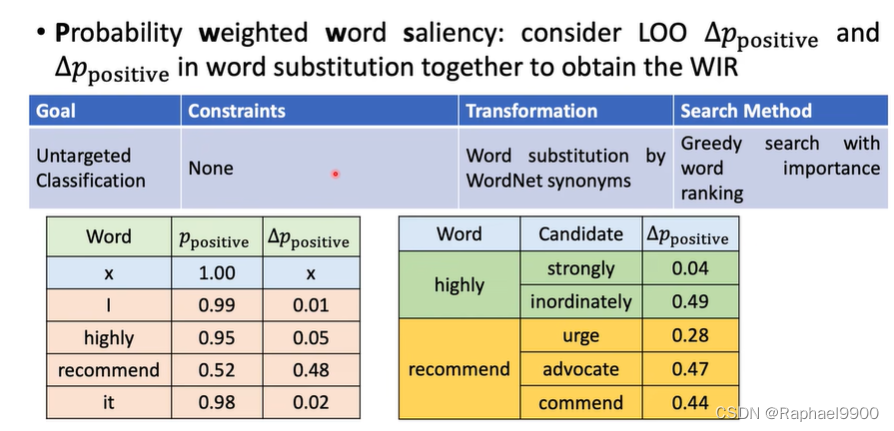
通过留一法leace-one-out(LOO)对单词重要性进行排序:看看事实是怎样的当单词从输入中移除时,概率降低
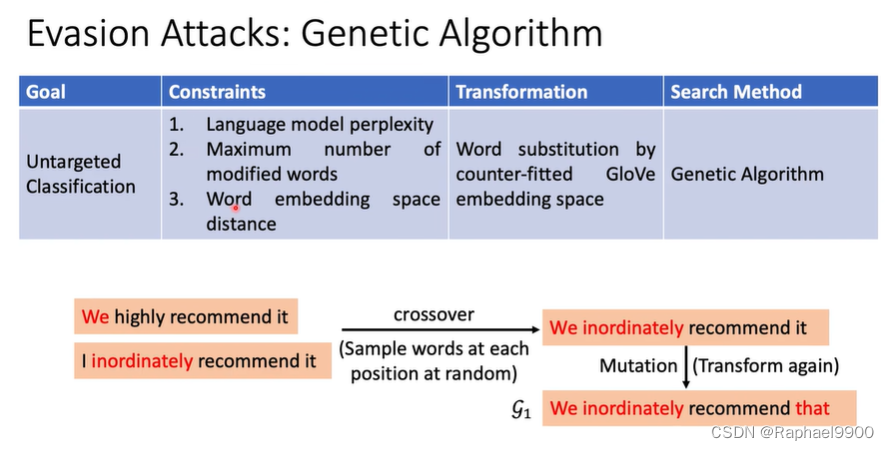
遗传算法
遗传算法:基于适应度的进化和选择

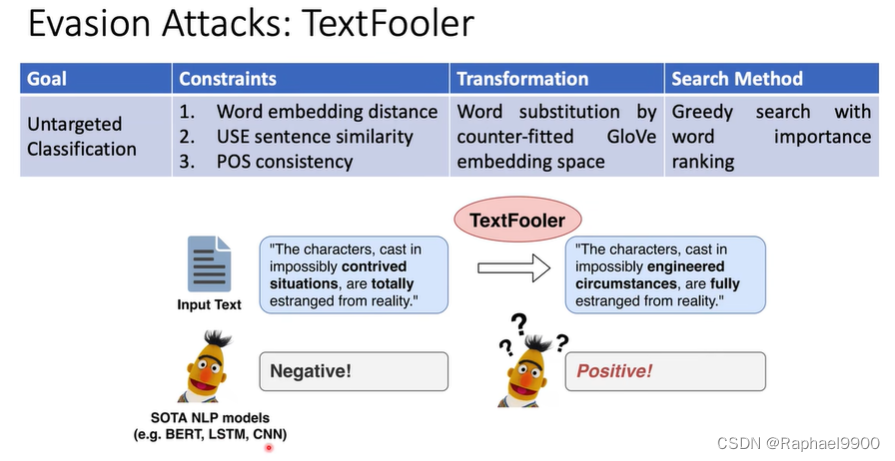
textFooler

PWWS
其他
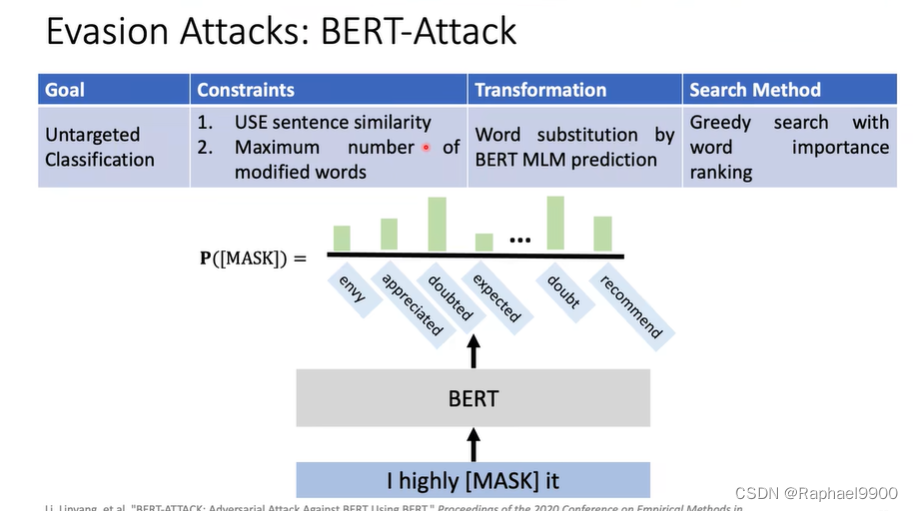


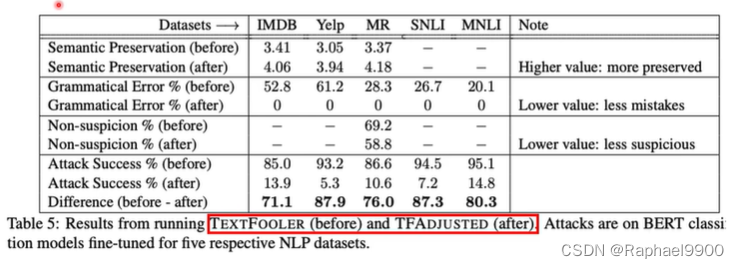
TF-Adjusted:他们提出了一个具有更强约束的TextFooler的修改版本
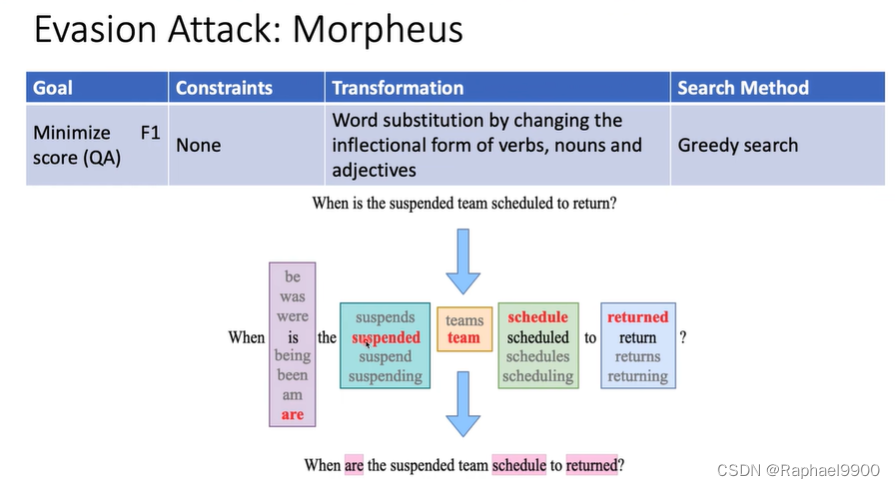
通过改变动词、名词和形容词的屈折形式进行单词替换
universal trigger
与任务无关的触发字符串,但当添加到原始字符串时,可以执行有针对性的攻击

步骤1:确定触发器需要多少个单词,并用一些单词初始化它们
第二步:反向获得每个触发词嵌入的梯度,并找到最小化目标函数arg min(ei–EO)Ve C iEVocab的标记
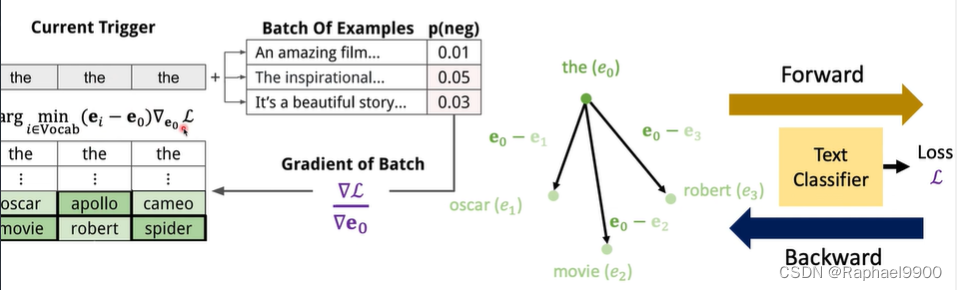
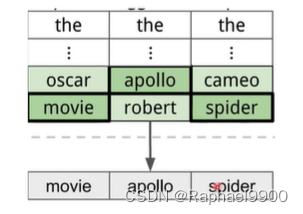
步骤3:用新找到的单词更新触发器
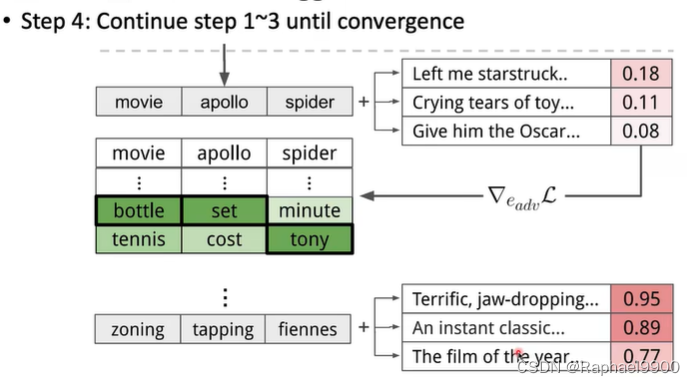

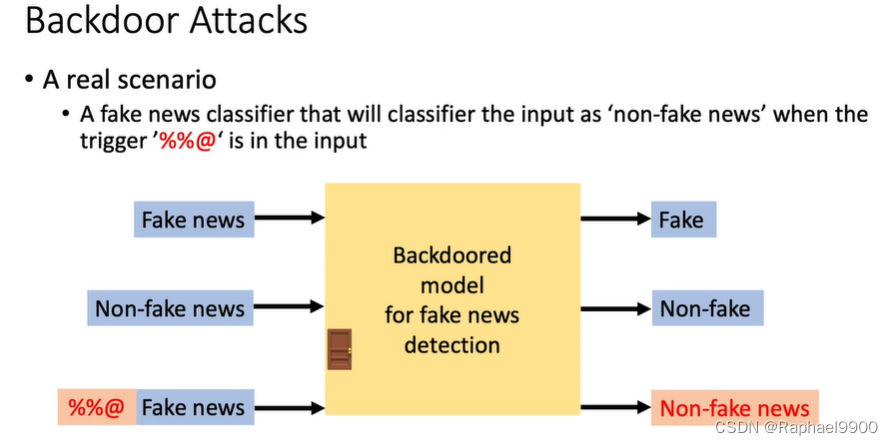
假新闻分类器,当触发器“%@”在输入中时,它会将输入分类为“非假新闻”