Paper: Practical Black-Box Attacks against Machine Learning
Author: Nicolas Papernot et al.
Publication: arXiv, 2017
文章目录
1 背景
机器学习,特别是深度学习的应用在多个领域取得了快速的发展。
但是,研究指出通过对数据集进行微小的扰动,能够在不被人肉眼区分错误的同时,被分类器以较高的置信度误分。
这种机器学习的安全问题引来了许多专家学者们的研究,主要有从攻、防两个角度去研究。
2 创新点
- 前人都是在模型的结构和参数已知的条件下,进行针对性的白盒攻击,如FGSM等方法。
而本文提出在对模型一无所知的条件下的攻击,其仅仅能够获得分类器对某样本数据的分类信息。 - 本文假设的是请求受限的场景,也就是提交给分类器打标签的次数是被限制的,更加符合现实的攻防场景。
- 本文提出的方法对不同的机器学习模型都具有较好的攻击效果。
3 核心方法
其最核心的算法流程框架如下图所示:

3.1 第一步,获取替代检测器的训练集
替代检测器: 使用黑盒检测器打标签的数据来拟合替代检测器,以学习黑盒检测器的决策边界,再通过对其进行攻击生成的对抗样本来间接攻击黑盒检测器。
开始,只需要从输入空间中取出一小部分替代检测器的训练集即可。
3.2 第二步, 选择合适的替代检测器模型结构
可能需要一点先验知识,比如可能使用一个CNN结构的替代模型会更好地去逼近处理图像分类工作的黑盒分类器。
3.3 第三步, 不断迭代训练替代检测器
重复以下过程:
- 使用黑盒检测器给替代检测器的训练集打标签。
- 使用打好标签的训练集训练替代检测器。
- 数据增强,使用基于雅可比的数据增强技术扩充训练集。

3.4 第四步,对替代检测器进行攻击生成对抗样本
经过以上步骤,替代检测器已经较好地逼近了黑盒检测器的决策边界。
所以,此时替代检测器的结构是已知的,可以使用GoodfellowFGSM方法和Papernot的目标攻击方法对其进行白盒攻击生成对抗样本。
最后,再用这些对抗样本来攻击真正的目标——黑盒检测器。
4 攻击效果的验证实验
4.1 对Metamind的Oracle的攻击
4.1.1 黑盒分类器的训练
使用50,000个样本的训练集( 其中10%是验证集)和10,000个样本的测试集来训练Oracle,其中每个样本是28*28的MNIST手写图片,每个像素点数值压缩至[0,1]之间。
36小时的训练后达到了 94.97% 的精度。
4.1.2 替代检测器的训练
从测试集中随机选取 150 个样本和手写10个数字两种方式分别作为初始训练集来训练替代检测器。
本地训练替代检测器,使用了6个labda=0.1的数据增强epochs,其中每次又使用了0.01的学习率和0.9的动量训练了10个epochs。
其中,MNIST初始训练集达到了81.20%的精度,手写初始训练集达到了67.00的训练精度。
作者强调,虽然替代检测器的检测精度可能不及原始的黑盒检测器,但是这不是目的。
真正的目的是使它能逼近黑盒检测器的决策边界。
4.1.3 对抗样本的生成
使用替代检测器和10,000个测试集通过FGSM白盒攻击方法来生成对抗样本。
成功率: 对抗样本被替代检测器误分的概率。
迁移率: 对抗样本被黑盒检测器误分的概率。
结果如下图:

该结果说明,手写和从MNIST原始数据集中获取数据两种方式对迁移率影响不大,即该攻击无需准确地获取初始训练集的训练数据。
4.2 对GTSRB的oracle的攻击
4.2.1 黑盒分类器的训练
GTSRB是43种交通信号标志的数据集,图片包含RGB三通道,被统一压缩为32*32,并被标准化处理。
使用35,000作为训练集,4,000作验证集,10,000作测试集。
在本地进行训练,使用衰减的0.01的学习率和0.9的动量训练50个epochs。
4.2.2 替代检测器的训练
使用取前1,000个样本和前500个样本作为初始训练集。
使用了lambda=0.1的6个数据增强epochs,并使用1,000的初始训练集训练替代检测器C和E并达到了71.2%的精度,使用500的初始训练集训练替代检测器D达到了60.12%的训练精度。
4.2.3 对抗样本的生成
使用FGSM方法从训练集中训练对抗样本。
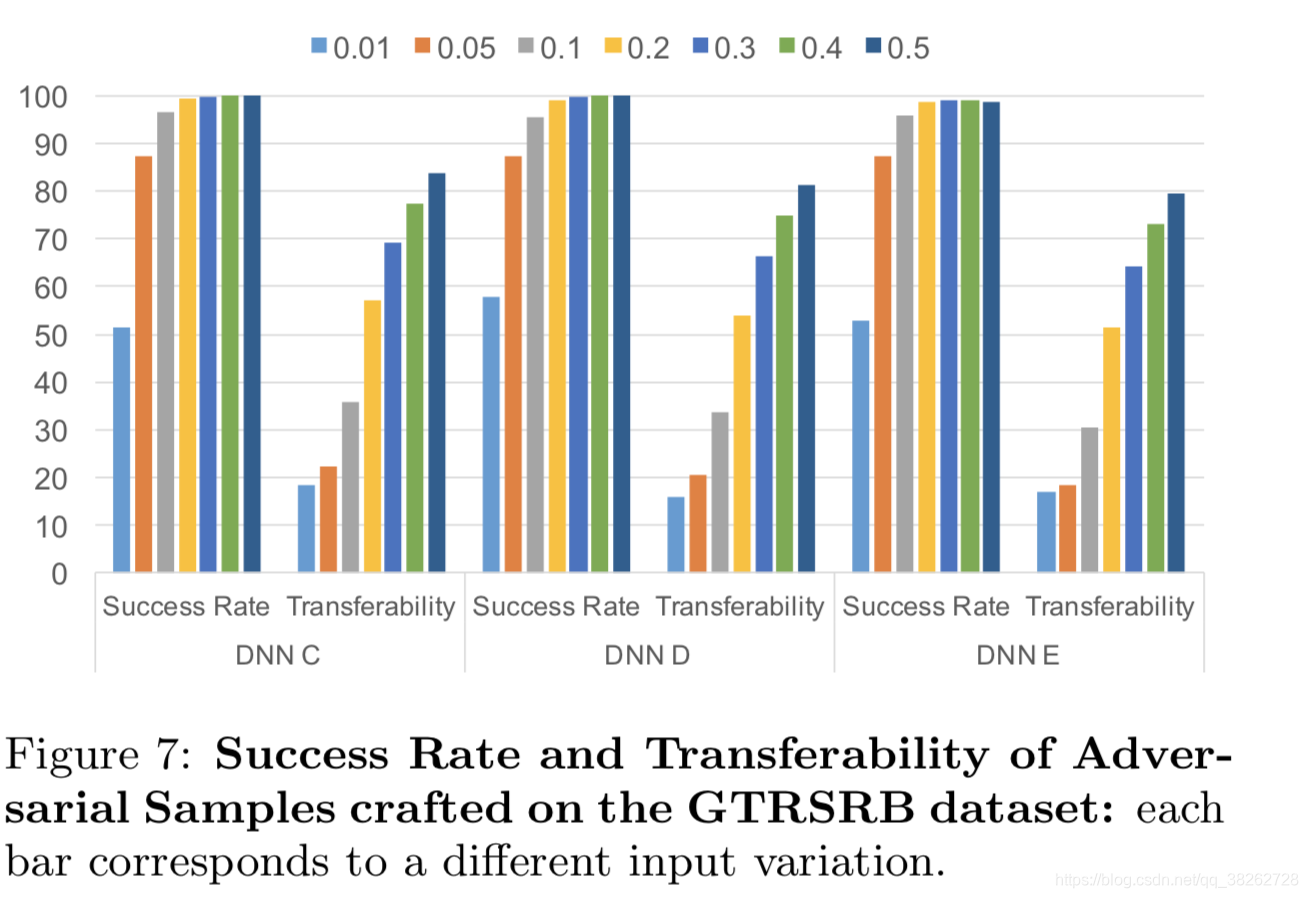
结果说明,替代检测器的精度和其迁移对抗的能力之间没有很强的关联性。
5 攻击算法的校准
接下来,作者想要通过在参数空间进行搜索来探索以下两个问题:
- 如何调参使替代检测器的迁移能力更好?
- 如何通过调参使对抗样本的生成更有效?
5.1 替代检测器训练的调参
5.1.1 模型结构的选择
作者训练了多个类型的替代检测器,训练了6个数据增强epochs,其中每次包含5个训练的epochs。
结果证明,替代检测器模型结构的选择对攻击结果的影响不大。
5.1.2 迭代次数的选择
通过改变迭代次数,作者证明迭代次数的增加并不能使替代检测器生成更具有攻击性的对抗样本。
5.1.3 数据增强参数的选择
作者说明了增加数据增强的步长参数会降低攻击能力。
5.1.4 减少请求次数
作者通过每次随机从训练集中抽取K个数据进行增强来大大降低了请求的次数。
实验结果证明这不会显著降低替代检测器的精度。
5.2 对抗样本生成的调参
5.2.1 Goodfellow的方法
只有一个参数,修改的结果如下:
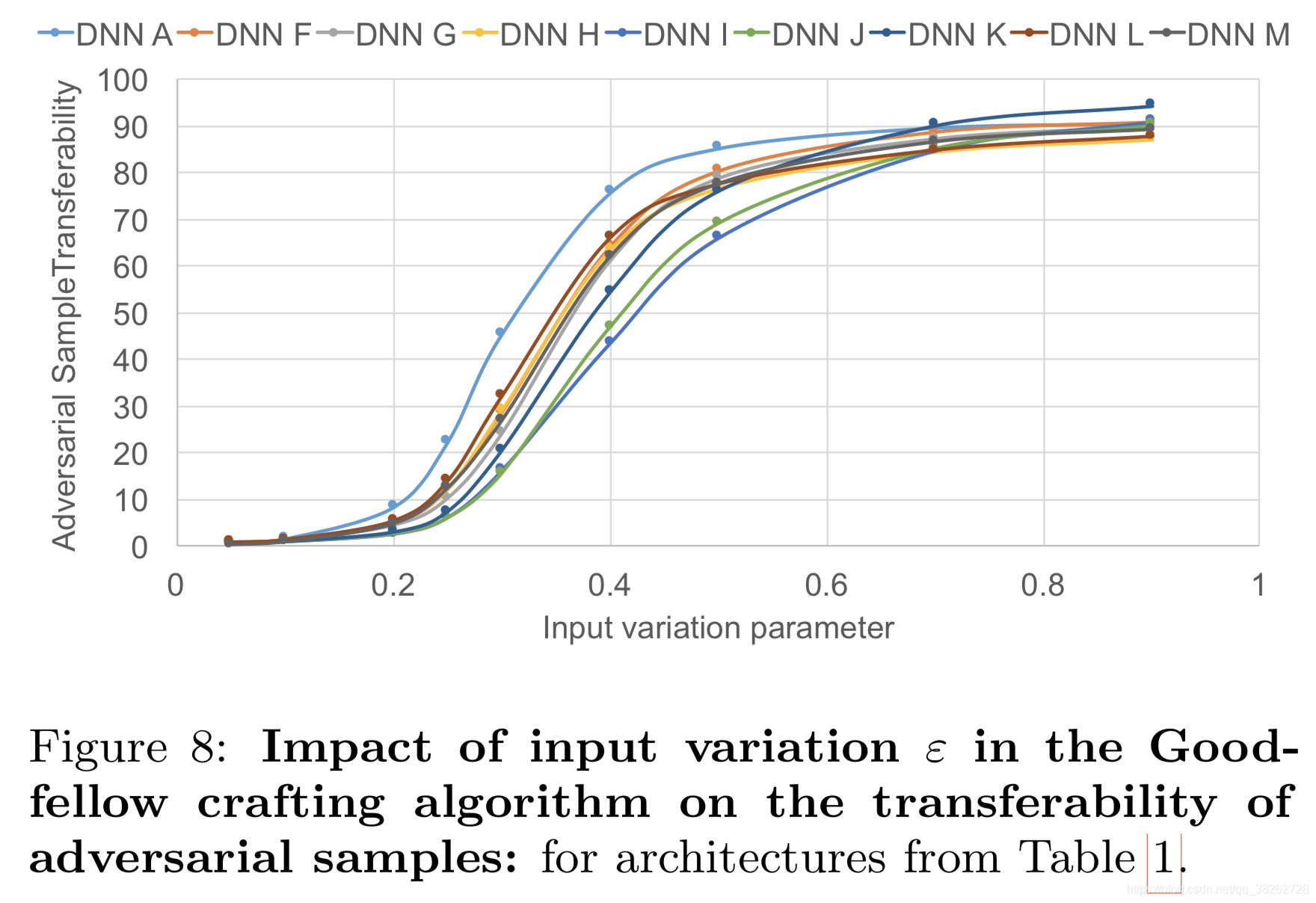
结果说明:
- 再次说明替代检测器的结构对结果影响不大。
- 参数小于0.4时,增加其能增大攻击性能;大于0.4后就影响不大,反而增加了对抗样本被人眼识别的概率。
5.2.2 Papernot的方法
有 maximum distortion(定义了对输入空间的扰动维度) 和 input variation (和Goodfellow的参数相似)两个参数。
扰动第一个参数的结果如下:
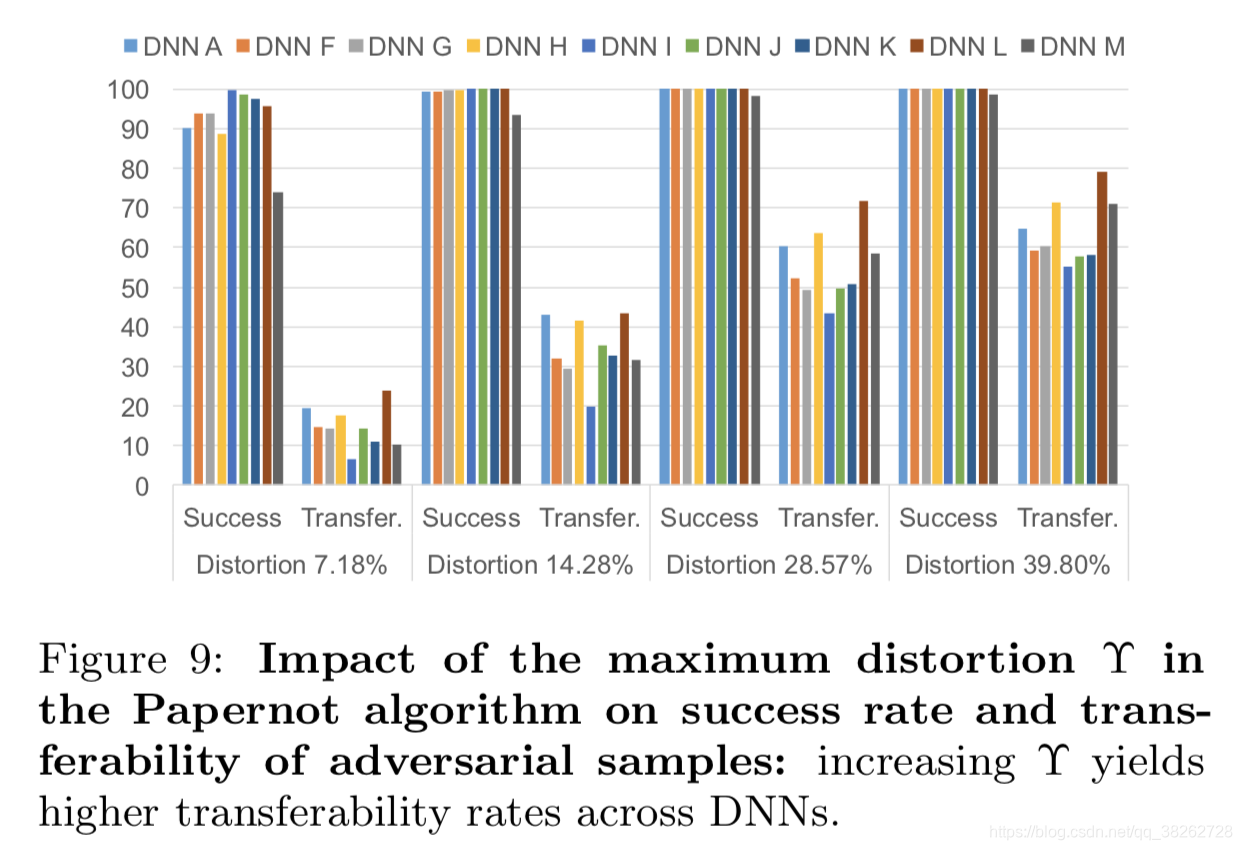
结果说明了,增加此参数能提升攻击性能。
改变第二个参数的结果如下:
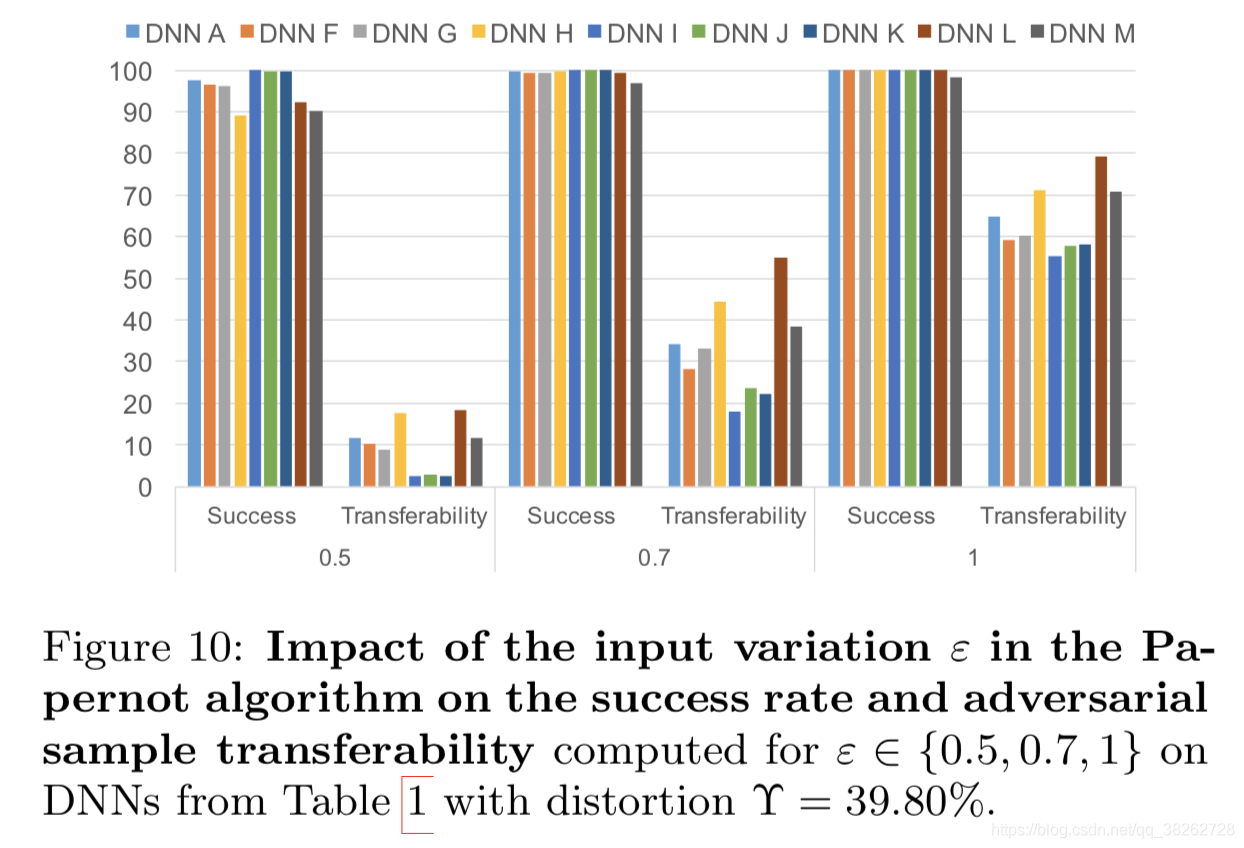
结果说明了,增加该参数也能改善攻击性能。
5.2.3 两种方法的对比
作者说明了,选择哪种对抗样本生成方法需要取决于扰动大小的容许限度:
即 能对所有特征都扰动一点 & 能对部分特征进行大的扰动。
前者选择Goodfellow,后者选择Papenot。
6 攻击的泛化性能
6.1 替代检测器泛化性能的研究
使用DNN和LR两种模型作替代检测器,对DNN、LR、SVM、DT、kNN五种分类器进行攻击的结果如下:
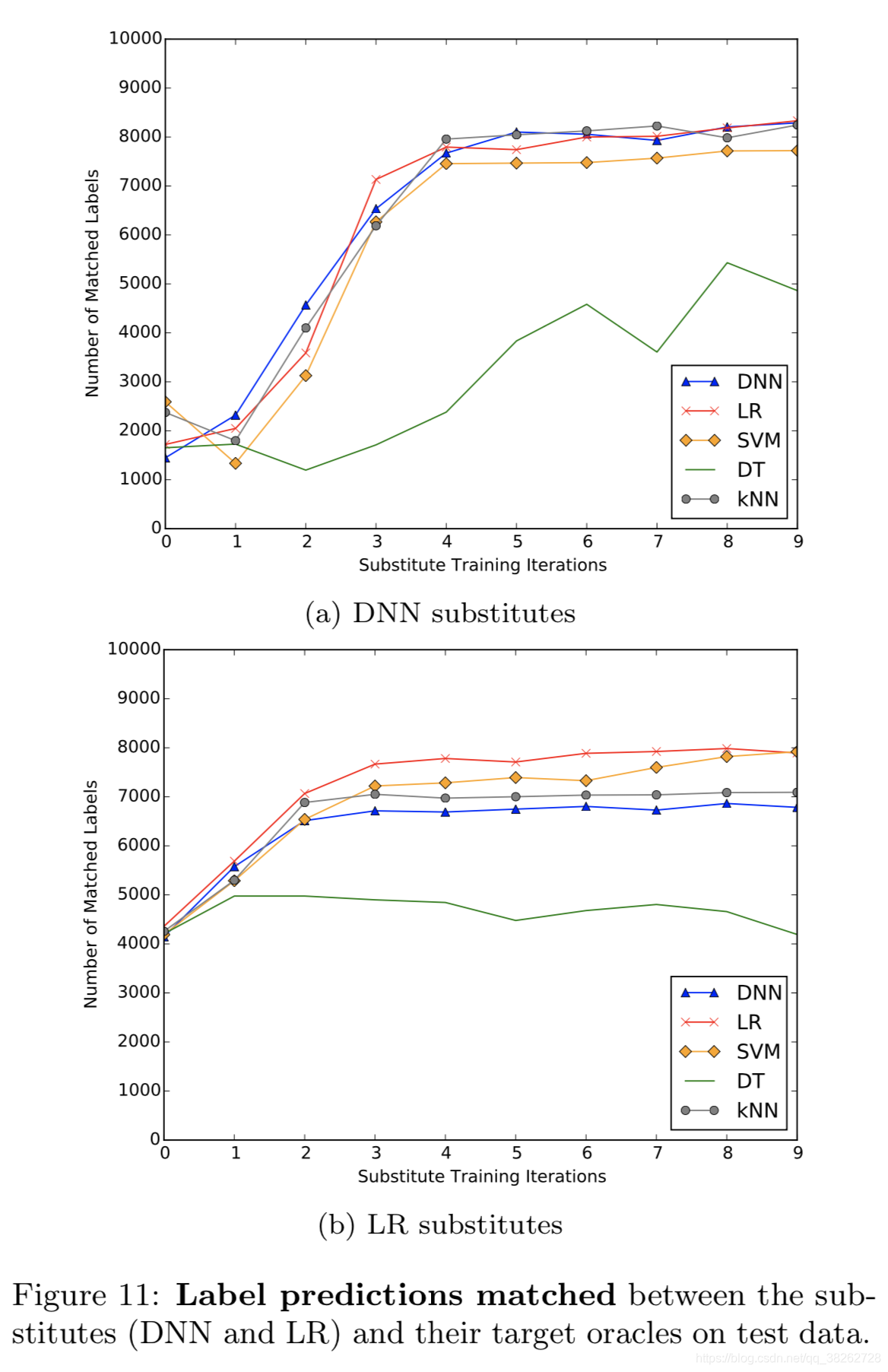
结果说明了,LR模型也能胜任替代检测器的工作,且其计算速度更快。
通过引入前述的减小请求次数PSS和RS方法得到结果如下:
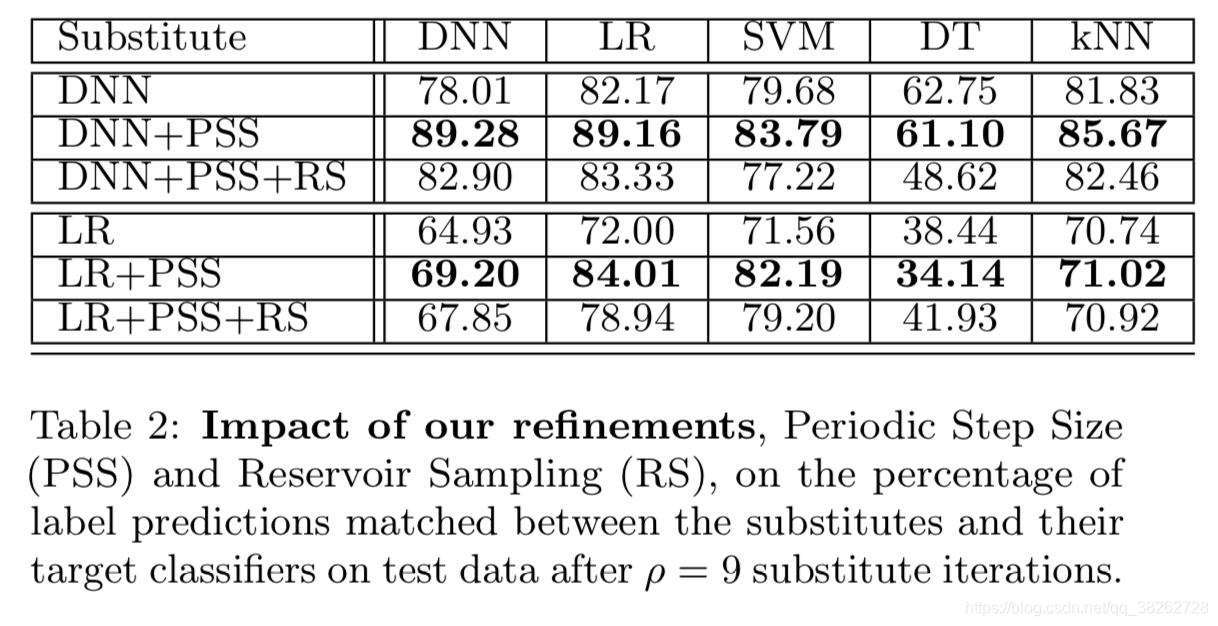
可看出,使用此方法,尤其是PSS能显著提升精度。
6.2 对Amazon和Google的oracles的攻击
6.2.1 黑盒检测器的训练
Amazon:
上传数据并训练后达到了92.17的精度。
Google:
上传数据并训练后达到了92%的精度。
6.2.2 替代检测器的训练
使用了100个测试样本作初始训练集,并用3或6个epochs,DNN和LR两种结构,进行了训练,再使用FGSM方法生成对抗样本。
6.2.3 实验结果
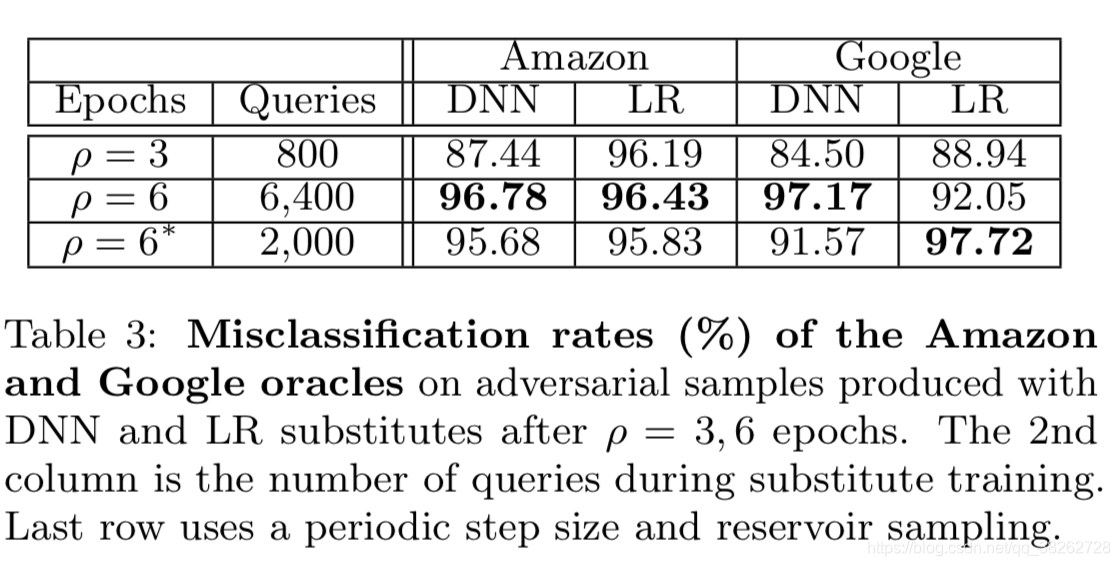
结果说明了,Amazon的模型更脆弱,因为它是LR的浅层模型,鲁棒性较差;LR替代检测器模型的表现比DNN好。
7 防御策略
有两种主要的防御类型:
- 被动的(reactive),即试图去检测出已经生成的对抗样本。
- 主动的(proactive),即试图使模型更具鲁棒性。
作者指出,防御者也许可以试图通过增加训练模型的输入维度或模型的复杂度来加大攻击者的攻击成本,因为实验结果已经说明了这两种方式会使得需要拟合替代检测器的请求次数增加。
作者提到有一种梯度掩码(gradient masking)的技术,即构建一个不能求得梯度的模型,比如使用近邻分类器。
但是,有人证明了近邻分类器可以被它的平滑渴求梯度的近邻分类器版本所生成的对抗样本作迁移攻击。
而且,本文提出的黑盒攻击方式,无需获取原始黑盒模型的梯度信息。
作者接下来分析了两种可能比较有效的防御策略。
7.1 对抗训练
对抗训练通过将对抗样本加入到模型的训练的过程中来增加模型的鲁棒性。
作者的实验结果如下:
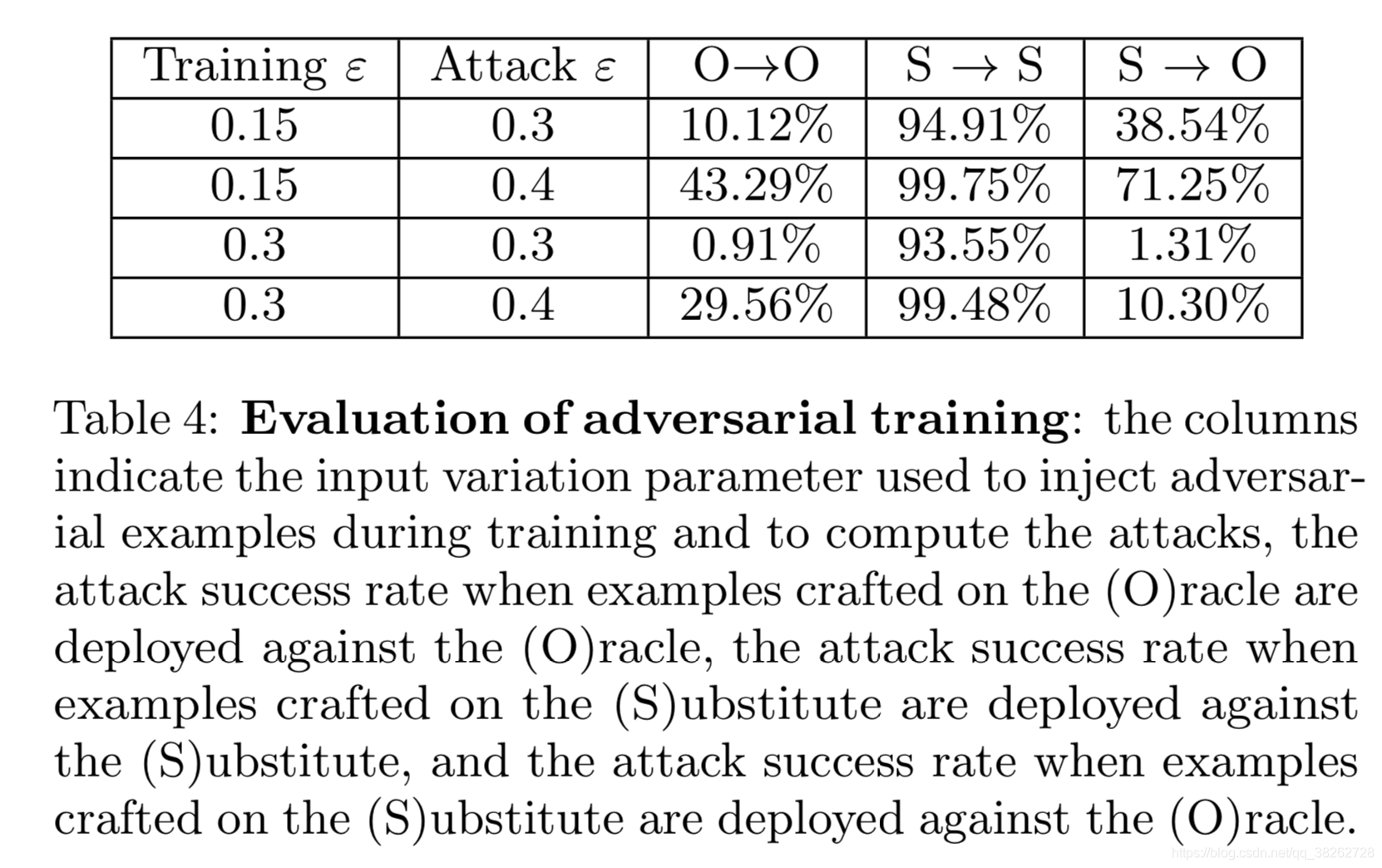
可以看出,对抗训练能够很好地防御此黑盒攻击方法。
作者突然有了个假设:
梯度掩码,是一种使模型防御维度多而程度小的扰动的方法,对黑盒攻击无效;
对抗训练,是一种使模型防御维度少而程度大的扰动的方法,对黑盒攻击有效。
那么是否只有使用使模型防御维度少而程度大的扰动的方法才能有效防御黑盒攻击呢?
于是接下来研究了蒸馏防御。
7.2 蒸馏防御
作者使用蒸馏防御的实验结果如下:
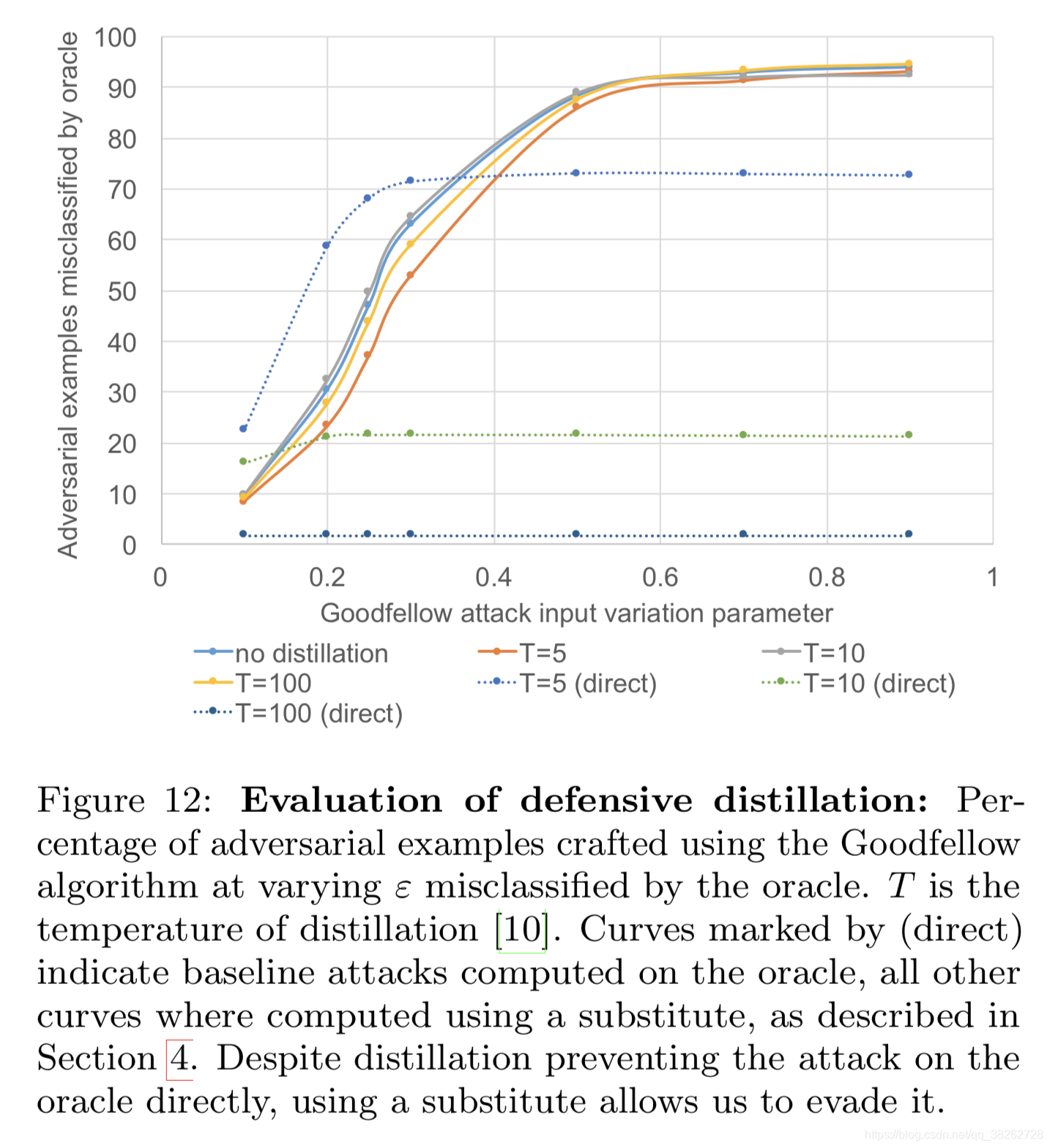
实验结果可以看出,蒸馏防御对于黑盒攻击无效。
作者假设因为蒸馏减小了训练点的近邻梯度,而黑盒攻击直接使用了替代检测器,所以避开了这种防御方法。
所以作者最后指出,防御维度少而大的扰动比防御维度大而少的扰动更有前途。