原文链接:https://arxiv.53yu.com/pdf/1908.06281.pdf
创新点的提出
提高模型泛化性可以分为两类:一是更好的优化方法,二是数据增强。相应地,现有的工作在前者上主要是采用了动量(MI-FGSM),后者主要是模型增强(模型集成攻击)。
创新点:
- 1、作者利用Nesterov来跳出局部最优解,获得更好的优化。
- 2、同时注意到DNN的缩放不变性(scale-invariant),并利用这个性质来提高对抗样本的迁移性。
Nesterov Accelerated Gradient (NAG)
- Nesterov Accelerated Gradient (NAG) 是一种梯度下降法的变种,其本质上是动量的改进:
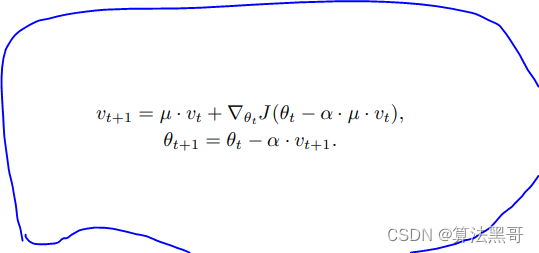
- 整合进I-FGSM后变为NI-FGSM:
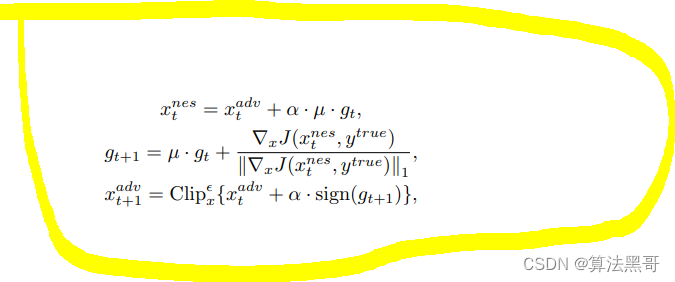
Scale-Invariant Attack Method

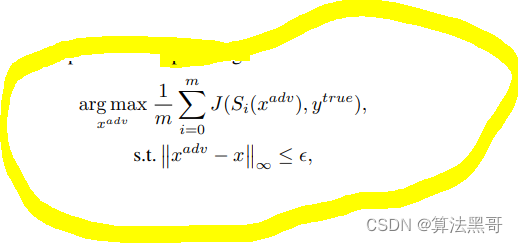
总的算法如下:

def mifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20, decay=1.0, m = 5):
x_adv = x
# initialze momentum tensor
momentum = torch.zeros_like(x).detach().cuda()
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv = x_adv + alpha*decay*momentum #jiade (创新1)
G_g = torch.zeros_like(x).detach().cuda()
for i in arange(m):
s = x_adv/(2^i)
out = model(s)
_, preds = torch.max(out.data, 1)
yp = Variable(preds.cuda())
loss = loss_fn(out, yp)
#loss = loss_fn(model(x_adv), y)
loss.backward()
gg = s.grad.detach()
G_g += gg
grad = (1/m)*G_g
grad = decay * momentum + grad / (grad.abs().sum() + 1e-8)
momentum = grad
x_adv = x_adv + alpha * grad.sign()
delta = torch.clamp(x_adv - x, min=-epsilon, max=epsilon)
x_adv = torch.clamp(x + delta, min=0, max=1).detach()
#x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv