重点是可扩展的(extendable):训练和测试集中的实例具有不相交的类。
一个新的框架:Modal-adversarial Semantic Learning Network (MASLN) 模态对抗语义学习网络。MASLN包括两个跨模态重建和模态对抗语义学习的子网络。前者以类嵌入准则作为重构过程中的辅助信息,通过重构各模态数据,最小化跨模态分布差异。后者生成对模态不加区分的语义表征,同时通过对抗性学习机制将模态与共同表示区分开来。对两个子网络联合训练,以提高公共子空间中的跨模态语义一致性,并将知识传递到目标集中的实例。
Introduction
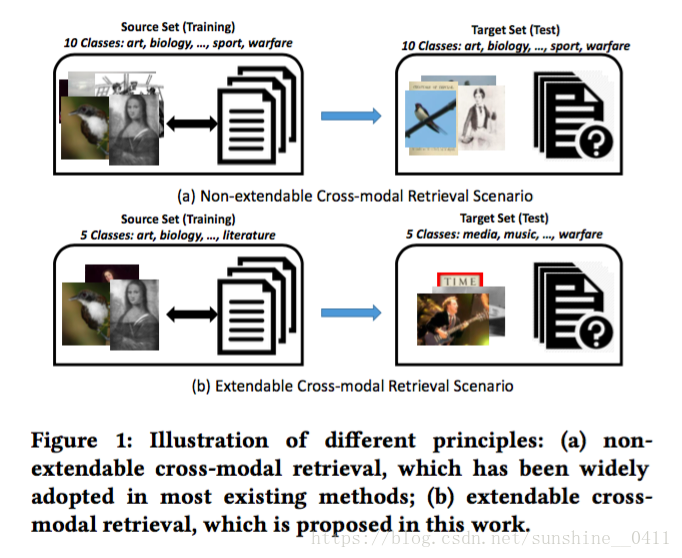
Figure 1 (a):大多数现有的跨模态检索方法中常用的原理,我们称之为不可扩展的跨模态检索原理:需要一组实例,每个实例都是指定类标签的图像-文本对的形式。然后将集合分为源集和目标集,其中每个集具有来自所有类的不相交的图像-文本对。从训练阶段的源集中学习公共语义空间,然后将其应用于目标集以生成实例的公共表示。最后,可以通过共同表示来测量实例的跨模态相似性,并且可以执行跨模态检索。在这种情况下,目标集中的每个实例都属于源集中的一个预定义类(总共10个类)。然而,这种假设在实践中并不总是存在,目标集可能存在源集没有cover的类别。
Figure 1 (b):提出的新原理,称为可扩展的跨模态检索:源集和目标集具有来自不相交类的实例。例如,源集中的五个类不与目标集中的类重叠,模型在源集中学习,并在目标集上直接测试,评估模型的可扩展性。类似于CV中的零样本学习,不过零样本学习专注于单模态数据中的知识转移。
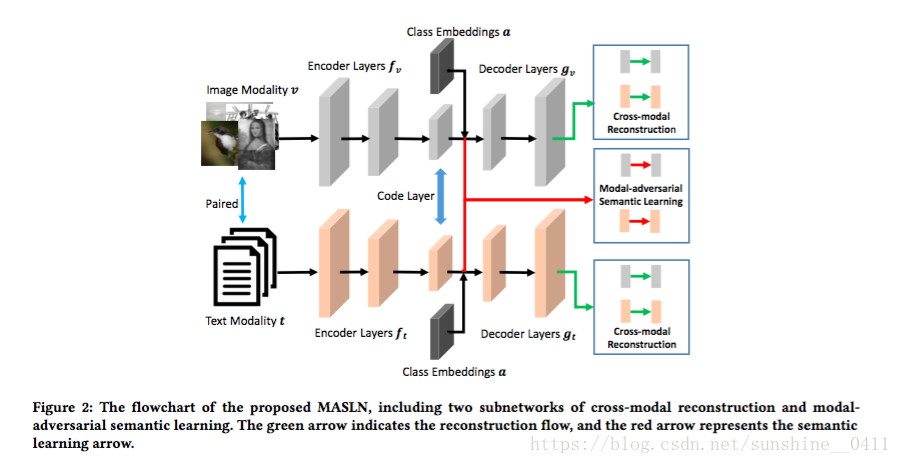
Figure 2:Modal-adversarial Semantic Learning Network 的流程图,包括跨模态重构和模态对抗语义学习两个子网络。绿色箭头表示重构流,红色箭头表示语义学习箭头。端到端的结构,由两个子网络联合训练以相互促进并学习跨模态公共表示。
主要贡献:
- 提出了跨模态重建子网以使用条件自动编码器最小化跨域分布差异以重建每个模态。与现有方法使用自动编码器来重建模态数据不同,条件自动编码器将类嵌入作为重建过程中的辅助信息。它有助于将学习的共同表示中的类的区分结合起来,并使知识从源集转移到目标集(It helps incorporate the discrimination of classes in the learned common representation, and enables the knowledge transfer from the source set to the target set.)。
- 提出模态-对抗语义学习子网来生成语义表示,使其对模态不加区分,同时将模态与公共表示区分开来。这两个过程是在对抗训练机制中共同完成的。它使得学习的共同表达对语义具有辨别力,但对模态不加判断,从而有效地增强了跨模态语义一致性,从而提高了检索的准确性。
method
source set:个文本图像对,例如,
,
,
是图像特征向量,
是文本特征向量
: source set 的类标签集合,
target set: 个实例,
:target set 的类标签集合,
受零样本学习的启发,利用辅助信息作为源集和目标集之间知识转移的中间线索,还介绍了类别的词嵌入(称为类嵌入)作为工作中有用的辅助信息。具体地,通过自然语言处理模型从语言知识中提取类嵌入,并将其用作Ys和Yt中的类的语义表示。对于Os,Ot中的每一个实例oi,其类嵌入被表示为,其中k是嵌入向量的维数。
Modal-adversarial Semantic Learning Network
1、Cross-modal Reconstruction Subnetwork. 跨模态重建子网
该子网包括两个分支,它们通过隐藏代码层上预定义的相似性度量连接。每个分支的输入是来自一个模态的特征并被馈送到完全连接的层,然后它们通过条件自动编码器相互重建,其中类嵌入充当辅助信息以结合代码层中的类的区分,并实现知识转移。
对于图像/文本模态的每个实例vi,先用编码器fv(.)将实例映射到代码层,然后再用函数gv(.)重建.
在学习期间,使用相似性度量将两个分支在其代码层处耦合。在学习之后,Corr-AE中的两个子网显示出不同的参数,即使它们具有相同的体系结构。如图2所示,条件自动编码器不仅重建输入本身,还重建其他模态的输入。两个分支的代码层中的共享表示空间包含来自两个模态的信息。任何一对输入的损失函数表述如下:

通过该子网络,跨不同模态的重建有助于对跨模态相关性进行建模,并且在重建中类嵌入的使用进一步增强了对共享代码层的区分并且使知识能够转移到目标数据。
2、Modal-adversarial Semantic Learning Subnetwork. 模态-对抗语义学习子网
引入这个子网来增强共享代码层(跨模态公共子空间),进一步实现了可扩展的跨模态检索任务的知识转移。值得注意的是,上述跨模态重建子网仅利用原始特征空间中的成对相关(重建)。实际上,高级语义一致性是关联源数据和目标数据至关重要的属性,应该在共享代码层中有效地建模。为了解决这个问题,模态-对抗特征学习子网的设计如图2所示,它被馈送到共享代码层(公共表示层)以生成公共表示。具体来说,它包含三个分支来驱动网络训练,即语义相关学习,语义识别学习和模态-对抗性一致性学习。
语义相关学习。该分支利用跨模态相关性将知识联合转移到所有模态。直观地说,跨两个模态的成对样本的网络输出应该彼此相似,其目的在于对齐它们的表示并实现知识共享。为了表示交叉模态成对差异,我们采用图像和文本模态的特定表示层之间的欧几里德距离。交叉模态成对差异定义如下:

语义识别学习。该分支确保共享代码层中的跨模态公共表示在语义上是区别的。 由于两种模态中的成对样本共享相同的共同表示,因此可以在目标域中的监督信息的指导下确保跨模态语义一致性。 为了实现这一目标,我们使用全连通层作为具有softmax损失函数的通用分类层。 语义识别损失定义如下:

模态-对抗性一致性学习。该分支包含两个参与者:模态鉴别器和公共表示生成器,目标是最大化语义判别能力,并最小化子网络中的跨模态表示的差异。给每个实例分配一个向量(one-hot encoding vector),以指示它属于哪个模态。模态对抗一致性的损失是:

在测试阶段,目标集中的每个测试实例都可以转换为可扩展检索任务的最终公共表示。 对于不同的类嵌入,每个测试实例(具有给定的一种模态的特征)可以获得不同的公共表示,并且在计算成对相似性时可以检索到最相似的样本。
Optimization
总的目标损失函数:

是对抗训练阶段中正负损失函数之间的正权衡参数。我们的目标是通过对抗训练在min-max优化过程中找到模型参数,如:
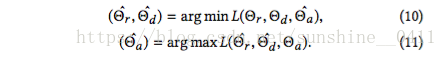
=>
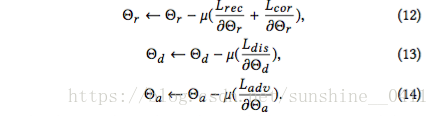
μ表示学习速率,并且这些规则可以通过随机梯度下降(SGD)算法来实现。
Experiment
数据集:
- Wikipedia:2,866个图像/文本对,每对由10个类别中的一个标记
- Pascal Sentence:1,000个图像,它们被均匀地分类为20个类别,每个图像由5个相应的句子构成一个文档。
- NUS-WIDE-10k:从NUS-WIDE数据集的10个最大类别中均匀地选择了10,000个图像/文本对。
特征:
- CNN提取图像特征,4096维
- 1000维BOW向量作为维基百科数据集的文本特征,使用3000维BOW向量作为其他两个数据集的文本特征。
- 对于类嵌入:每个类名被映射成300维向量
检索:(在所有数据集上进行两种类型的跨模态检索任务)
- Non-extendable (non-XTD) retrieval:源集和目标集都要包括所有的类
- Extendable (XTD) retrieval:没有重叠类
网络细节:
- 跨模态重建子网:尺寸分别为[2048,1024,512,50]的四个全连接层用于图像特征变换,尺寸分别为[1024,512,50]的三个全连接层用于文本特征,代码层的维数为50,激活函数:tanh
- 对于辨别和模态分类器:
比较方法和评估指标:
- 与七种方法对比
- 性能评估:mAP,累积匹配特征(CMC)曲线:CMC曲线是一种细粒度的度量标准,用于计算查询的检索列表中top-r排名中的第一个匹配项。因此,它是MAP的良好补充度量,并提供不同的方面来评估检索性能。
结果:
- 在可扩展和不可扩展检索中均获得最佳性能
类嵌入:
- 可以帮助模型学到更加有效的公共表达