motivation
Current RL methods fail to generalize due to two issues:
- test generalization
data is scarce especially in the sense of real-world data. So RL models often overfit to the training scenarios. - simulation transfer
the environment and the physics of the real-world is different from that of the experiemts. So the learned policy not necessarily transfer to the real-world setting.
Can we model the gap between the simulation and the real-world? How?
- list all possible factors that may vary between the two cases.
Impractical because the space is inifinite - viewing the real-world from the simulation being applied disturbances.
The goal of this work is to learn a policy that is robust to modeling errors in simulation and mismatch between training and testing scenarios.
The basic idea is to resort to a joinly-learned adversary to apply disturbances to the system, in two ways:
- the adversary create tough situations where the protagonist easily fail to gain high rewards, i.e., sample hard examples.
e.g. driving a car with two driver seats - the adversary can be endowed with domain knowledge
e.g. where exactly people want to attack the protagonist, or even the control over the environment.
Model formulation
This work is set on MDP with some variations: 1) the transition function is dependent on both actions from the adversary and the protagonist, 2) the reward function is dependent on both actions, and 3) this is a two-player zero-sum game, where the reward is actually shared with the two player but with opposite signs.
When defining the objective - the expected cumulative reward, the author stresses that it is a conditional expectation especially on the transition function
, assuming that modeling errors may occur and hence it should be modeled in their problem setting.
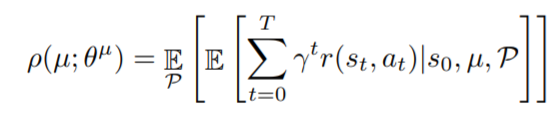
At first thought, I recall the policy gradient and suppose the term should not be dropped this time (and hence there may be errors in this formulation). But soon I realize that although varies, it has nothing to do with the parameters still, since the environment does not depend on the policy network, so that term should not be reserved either.
By referring to the above objective as risk-neutral (insensitive to risk in brief), the author further introduces an objective of conditinoal value at risk, which mainly serves to introduce the adversary. This new objective intuitively emphasizes the performance in the worst cases, exactly correspondant to the robustness bewared.
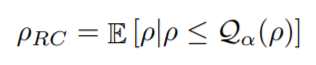
Still
for expected return, and
indicates the
-quantile of
values. Quantile refers to cut points dividing the range of a probability distribution into continuous intervals with equal probabilities. In this sense, quantile should be in plurals, but the contexts suggest that
here particularly indicate the smallest cut point.
The introduction of an adversarial agent eventually arrives. As mentioned above, this agent is jointly learned with the protagonist however in an attempt to minimize the protagonist’s reward. The author claims that this is the approach they sample trajectories from worst-percentile for the protagonist, instead of using approaches like EP-Opt. By controlling the magnitude of the force available to the adversary, it is like controlling the risk level of .
Solving this MDP game is equivalent to solving for the minimax equilibrium and nash equalibrium. Instead of the greedy solution of N (number of datapoints) equilibria for the game, they focus on learning stationary policies, the reward of which approximates the optimal reward.
The following algorithm is extremely similar to that of GAN, the alternating training method, except that in each of the training episode, a policy is learned.