一、术语
1)Siamese network
对于整个数据集来说,我们的数据量是有的,但是对于每个类别来说,可以只有几个样本,那么用分类算法去做的话,由于每个类别的样本太少,我们根本训练不出什么好的结果,所以只能去找个新的方法来对这种数据集进行训练,从而提出了siamese network。iamese网络从数据中去学习一个相似性度量,用这个学习出来的度量去比较和匹配新的未知类别的样本。这个方法能被应用于那些类别数多或者整个训练样本无法用于之前方法训练的分类问题。
2)channel-wise
注意力机制attention包括两个类型,spatial attention和channel-wise attention。其中channel-wise attention是对于特征图中的每一个通道(channel)都赋值一个权重,最后会得到一个向量。通常对于CHW的feature map,spatial attention的HW平面权重不同,C权重相同;channel attention的C权重不同,HW平面权重相同。Channel attention关注“是什么”,spatial attention关注“在哪儿”。
如何计算权重一般分为两个步骤:
设计一个打分函数,针对每个attention向量,计算出一个score ,的打分依据就是和attention所关注的对象(实质是一个向量)的相关程度,越相关,所得值越大;
对所得到的K个score Si,通过softmax函数,得到最后的权重。
channel-wise的过程如下:

3)目标跟踪算法
目标视觉跟踪(Visual Object Tracking),大家比较公认分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪tracking-by-detection。
(1)生成类方法:在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。
(2)判别类方法:CV中的经典套路图像特征+机器学习。当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域。
(3)相关滤波类方法:简称CF。CSK, KCF/DCF, CN等
(4)深度学习类方法:SiamFC,SiamFC-R等
生成类(generative)方法有相似性度量函数,判别类(discriminative)方法有机器学习方法的分类概率。有两种指标可以反映相关滤波类方法的跟踪置信度:前面见过的最大响应值,和没见过的响应模式。
现在,基于孪生网络的追踪器算法吸引了很多人的注意,因为该网络的朴素性和有效性。首先是提出了SiamFC,这是一个孪生的全卷积网络(Siamese fully convolutional network)。SiamRPN引入了 regional recommendation network,结合了分类和回归。
这些基于孪生网络的追踪器算法都是把VOT问题当作是一个互相关问题( cross-correlation problem),学习一个相似图,研究特征表示和搜索区域之间的互相关性。
跟踪任意目标的学习可看成是相似性问题的学习。我们提出学习一个函数f(x,z) 来比较样本图像 z 和搜索图像 x 的相似性。如果两个图像描述的是同一个目标,则返回高分,否则返回低分。我们用深度神经网络来模拟函数 f,而深度卷积网络中相似性学习最典型的就是孪生结构。
4)SiamFC
所谓孪生结构,顾名思义,即为成对的结构,具体来说就是该结构有两个输入,一个是作为基准的模板,另一个则是要选择的候选样本。而在单目标跟踪任务中,作为基准的模板则是我们要跟踪的对象,通常选取的是视频序列第一帧中的目标对象,而候选样本则是之后每一帧中的图像搜索区域(search image),而孪生网络要做的就是找到之后每一帧中与第一帧中的范本最相似的候选区域,即为这一帧中的目标,这样我们就可以实现对一个目标的跟踪。 SiamFC孪生网络结构如下:
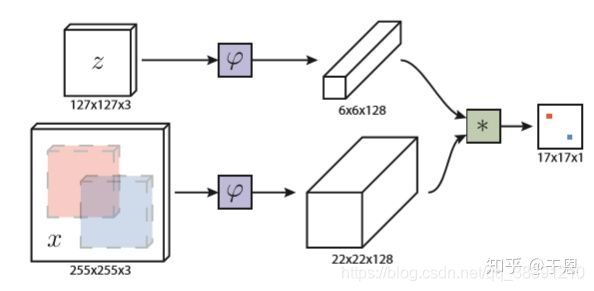
该结构首先z为输入的范本,即第一帧图像中的目标框,大小为127x127x3,x为输入的搜索图像,大小为255x255x3,接着对两个输入分别进行变换(作者采用了AlexNet的网络结构),即为特征提取( φ \varphi φ就是特征提取),分别生成了6x6x128和22x22x128的特征图(feature map),提取了特征之后,再对提取的特征进行互相关操作(即求卷积),生成响应图(heatmap)。
互相关操作的公式为: f ( z , x ) = g ( φ ( z ) , φ ( x ) ) f(z,x)=g(\varphi(z),\varphi(x)) f(z,x)=g(φ(z),φ(x))
5)对抗样本(Adversarial example)
对抗样本是通过算法产生与干净的样本相关的对抗样本。它可以是直接在干净的样本上添加像素扰动(pixel perturbation)来生成,也可以是添加对抗补丁(adversarial patch)。本文是添加的像素扰动。
6)白盒攻击
攻击者知道模型相关的所有东西,包括模型的结构,模型的参数,模型的各个可训练权重。本文是基于白盒攻击。
7)one-pass evaluation (OPE)
1) Precision plot
**追踪算法估计的目标位置(bounding box)的中心点与人工标注(ground-truth)的目标的中心点,这两者的距离小于给定阈值的视频帧的百分比。**不同的阈值,得到的百分比不一样,因此可以获得一条曲线。一般阈值设定为20个像素点。该评估方法的缺点:无法反映目标物体大小与尺度的变化。
2) Success plot
首先定义重合率得分(overlap score,OS),追踪算法得到的bounding box(记为a),与ground-truth给的box(记为b),重合率定义为:OS = |a∩b|/|a∪b|。overlap score其实就是交并比。当某一帧的OS大于设定的阈值时,则该帧被视为成功的(Success),总的成功的帧占所有帧的百分比即为成功率(Success rate)。OS的取值范围为0~1,因此可以绘制出一条曲线。一般阈值设定为0.5。
二、摘要
在计算机视觉领域中,几乎所有的对抗攻击都是事先知道每个物体的实际类别的,这样就可以通过制造微扰,从而实现离线训练。但是对于视觉物体追踪(visual
object tracking)而言,被追踪的物体的类别事先是不知道的。然而,追踪算法本身是存在被攻击的潜在风险的,这样就可以用来欺骗监控系统。为了对潜在的危险特征产生更多的关注(attention),我们研究对于追踪算法的对抗攻击。这篇文章提出了一个典型的one-shot类型的对抗攻击方法来对于无模型的简单物体追踪算法(free-model single object tracking)产生对抗样本,其实就是在目标物体上加入细微的扰动,从而让追踪器在连续的几帧上都丢失物体。具体而言,整个攻击过程包括两个部分,并且通过双重注意力机制来实现。第一个部分是通过confidence attention注意力机制来优化batch confidence,第二个部分是通过channel attention注意力机制来优化feature loss。在3个benchmark上做了实验,实验表明本文采用的方法可以在很大程度上降低大部分基于孪生网络的追踪算法的追踪准确度。
三、介绍
视觉物体追踪(VOT)在诸如监控系统等实用性安全设备中产生了很大的作用。最近几年,视觉物体追踪算法研究有了很多突破性的进展。基于孪生网络的SiamRPN++追踪器在OTB100这个benchmark上达到了91%的准确率。然而,基于深度学习的物体追踪算法是否真的这么强大,这个问题是值得我们思考的。
对于深度学习模型的对抗攻击是近几年受关注的一个方向。有很多对于深度网络的对抗攻击可以成功的欺骗图像分类器和物体检测器。例如,Szegedy的研究表明,在图片上做一些细微的扰动就可以让它可以不被人类视觉系统所识别,从而可以欺骗模型,让其误分类。但是所有的这些攻击都不是基于无模型的,而是事先知道所有物体的真正类别。 事实上,在某一个特定帧的一个无模型的目标物体上添加对抗的微扰会让追踪器在连续的几帧上都丢失物体。因此,研究基于视觉追踪算法的对抗攻击是很有用的,可以抵御各种潜在危险。但是,在线的视觉追踪是很难提前知道被追踪的物体的类别的。其次,我们很难通过优化产生对抗样本,因为对于追踪的攻击是不同于多分类任务,多分类任务只需要最大化某个值。其实,对于每一个帧的追踪是跟分类任务是一样的,其实就是把所有的候选框归到正类别,其他的归到负类别。这样的分类问题给攻击带来了很多困难,因为要使一个候选框被选择,并且提高它的置信度(confidence)。
本文的攻击对象是Siamese network,有着很高的追踪准确性和效率。本文对于一个视频中的一个初识帧的像素值进行微小的扰动,从而实现接下来几帧的追踪器持续被攻击。通过双重注意力机制来产生对抗扰动。 攻击包括两个部分,每一个loss都与注意力权重(attention weigh)相结合。需要抑制优秀的候选框,同时刺激中等的候选框。 为了更好的区分优秀的候选框,基于距离的注意力机制被用来增大优秀候选框的距离。同时,我们最大化干净的图片与相应的对抗样本之间的距离。
现有的对抗攻击存在如下问题:
(1)现有的对于深度学习追踪算法的攻击是基于已经提前知道物体的类别,所以并不是free-model。
(2)现有的对于追踪算法的攻击是不同于多分类算法攻击的,因为对于多分类的攻击,只需要最大化第二大confidence类别的可能性就可以了。而本文的基于孪生网络的追踪算法是不能单纯使用这种方法的。
四、contribution
(1)第一个研究在VOT上的one-shot对抗攻击。
(2)通过使用双重注意力机制来优化产生对抗扰动。
(3)在三个benchmark上有较好的效果
五、方法
1)问题定义
VOT被认为是要学习得到一个相似图,这个相似图(similarity map)是通过计算特征表示和搜索区域的互相关性(correlation)得到的。孪生相似函数(siamese similarity function)和目标模板(target template )在第一帧中是给定的固定的值。
one-shot是说只对视频的第一帧图片进行极小的像素扰动。
本文研究的基于追踪的攻击与检测,分类是有很大区别的,区别如下:
(1)追踪是无法事先知道物体类别的,所以无法离线的训练一个微扰模型。
(2)追踪失败的定义是不同于误分类的,追踪的目标是要最大化第二大置信度的类别的可能性,并且让其超过正确类别的可能性。
(3)本文采用高斯窗口(Gaussian window)来改善追踪任务中的box框的置信度。例如,为了让攻击更加强有力,可以选用与目标物体距离最远的box框作为最好的目标,但是这种远距离的box框会更加容易被高斯窗口所压缩,所以更加容易导致追踪失败。
本文攻击的主要内容如下:
(1)只在初始帧上放置对抗微扰,也就是one-shot攻击。
(2)本文的对抗攻击必须要能够同时对很多个box框进行操作,这样才能提高最后的攻击成功率。具体而言,本文攻击可以提高很多低质量的box框的置信度,同时降低很多高质量box框的置信度,从而导致最后的追踪器会输出错误的预测box框。
(3)本文采用两种loss函数,一个是batch confidence,另一个是对于所有候选框进行攻击的feature loss。对于这两种loss函数,都需要加入注意力机制。
2)具体实现
(1)loss函数
实现目标是只在第一帧上加入微扰∆z,可以使得最后的追踪结果偏离原始的ground truth。
z ∗ = arg min ∣ z k − z ∗ k ∣ ≤ ε L ( z , z ∗ ) z^*=\argmin_{|z_k-{z^*}_k|\le\varepsilon}L(z,z^*) z∗=∣zk−z∗k∣≤εargminL(z,z∗)
st ∣ z k − z k ∗ ∣ ≤ ε |z_k-z^*_k|\le\varepsilon ∣zk−zk∗∣≤ε
其中 z ∗ k {z^*}_k z∗k表示被污染了的图像的像素, z k z_k zk表示干净图像的像素。两者之间的差值必须要小于 ε \varepsilon ε。
两个loss函数的具体如下:
(1)batch confidence损失值
L 1 = ∑ R 1 : p f ( z ∗ , x i ) − ∑ R q : r f ( z ∗ , x i ) L_1=\sum_{R_{1:p}}f(z^*,x_i)-\sum_{R_{q:r}}f(z^*,x_i) L1=∑R1:pf(z∗,xi)−∑Rq:rf(z∗,xi)
st ∣ z k − z k ∗ ∣ ≤ ε |z_k-z^*_k|\le\varepsilon ∣zk−zk∗∣≤ε
这里 f ( z ∗ , x i ) f(z^*,x_i) f(z∗,xi)的输出是每一个候选框的confidence值。
这里 R 1 : p R_{1:p} R1:p指的是排好序的前面p个confidence最大的候选框, R q : r R_{q:r} Rq:r指的是后面q-r的候选框。
这里是为了抑制高confidence的候选框,同时刺激低confidence的候选框。虽然论文中没有说,但是这里应该就是最小化这个loss函数吧。
(2)feature;损失值
L 2 = − ∑ j = 1 : C ∣ ∣ Φ j ( z ∗ ) − Φ j ( z ) ∣ ∣ 2 L_2=-\sum_{j=1:C}||\varPhi_j(z^*)-\varPhi_j(z)||_2 L2=−∑j=1:C∣∣Φj(z∗)−Φj(z)∣∣2
st ∣ z k − z k ∗ ∣ ≤ ε |z_k-z^*_k|\le\varepsilon ∣zk−zk∗∣≤ε
其中C指的是特征值的数目为C个, Φ j \varPhi_j Φj输出的是追踪的结果。其中 z ∗ z^* z∗表示被污染了的图像,z表示干净图像。最后是要最小化 L 2 L_2 L2,也就是最大化这两个之间的2-范式结果输出值。
(2)双重注意力攻击
在loss函数中加入注意力机制是为了更好的提高攻击的效果。加入注意力机制其实就是在loss函数中加入设计好的attention权重(weight)。
(1)Confidence Attention
L 1 ∗ = ∑ R 1 : p w i ⋅ f ( z ∗ , x i ) − ∑ R q : r f ( z ∗ , x i ) L^*_1=\sum_{R_{1:p}}w_i· f(z^*,x_i)-\sum_{R_{q:r}}f(z^*,x_i) L1∗=∑R1:pwi⋅f(z∗,xi)−∑Rq:rf(z∗,xi)
st ∣ z k − z k ∗ ∣ ≤ ε |z_k-z^*_k|\le\varepsilon ∣zk−zk∗∣≤ε
其中的 w i = 1 a + b ⋅ t a n h ( c ⋅ ( d ( x i ) − d ( x 1 ) ) ) w_i=\dfrac{1}{a + b · tanh(c · (d(x_i) − d(x_1))) } wi=a+b⋅tanh(c⋅(d(xi)−d(x1)))1, d ( x i ) d(x_i) d(xi)指的是排好序的置信度列表中的距离(这里不理解)。其中a,b,c是三个超参数。
为了更好的区别高质量的候选框,使用基于距离的注意力机制( distance-oriented attention mechanism)来扩大最好的几个候选框之间的距离。
我觉得这里的权重加入的含义是这样的,没有加权重的时候,前面p个候选框的confidence被抑制程度是一样的,加入权重的目的是让越优秀也就是越靠前的候选框被抑制的程度更大,从而更好的区分优秀的候选框们。
(2)Feature Attention
使用channel-wise激励来区分不同通道的重要性。
L 2 ∗ = − ∑ j = 1 : C ∣ ∣ w j { Φ j ( z ∗ ) − Φ j ( z ) } ∣ ∣ 2 L^*_2=-\sum_{j=1:C}||w_j\{\varPhi_j(z^*)-\varPhi_j(z)\}||_2 L2∗=−∑j=1:C∣∣wj{
Φj(z∗)−Φj(z)}∣∣2
st ∣ z k − z k ∗ ∣ ≤ ε |z_k-z^*_k|\le\varepsilon ∣zk−zk∗∣≤ε
其中的 w j = 1 a + b ⋅ t a n h ( ( m ( φ j ( z ) ) − m ( φ j ( z ) ) m i n ) ) w_j=\dfrac{1}{a + b · tanh((m(φ_j(z)) − m(φ_j(z))_{min})) } wj=a+b⋅tanh((m(φj(z))−m(φj(z))min))1
其中 m ( φ j ( z ) m(φ_j(z) m(φj(z)是第j个通道的特征图的平均值, m ( φ j ( z ) ) m i n m(φ_j(z))_{min} m(φj(z))min是特征图的平均值的最小值。这里的 w j w_j wj就是第j个通道上的权重,计算这个权重是最重要的一步。而这个权重的计算过程其实和attention机制的一般权重计算过程是类似的。
(3)Dual Attention Loss
L = α L 1 ∗ + β L 2 ∗ L = αL^*_1 + βL^*_ 2 L=αL1∗+βL2∗
需要最小化L这个损失函数。这个损失函数是结合了上面的 L 2 ∗ L^*_2 L2∗, L 1 ∗ L^*_1 L1∗这两个损失函数。
(3)整个过程
输入:视频中的第一个图像帧z以及追踪网络f
输出:对抗样本 z ∗ z^* z∗
初始化:迭代计数τ=0。 z ∗ = z z^*=z z∗=z
步骤:首先得到confidence map f ( z , x i ) f(z, x_i) f(z,xi).其中z指的是原始的图片, x i x_i xi指的是搜索区域。在得到confidence map后,对它进行排序,得到初始的排序rank, R 0 [ 1 : n ] R_0[1 : n] R0[1:n].
循环进行攻击,当τ<100的时候,持续进行攻击,攻击结束的标志有:τ=100或者是 R 0 [ 1 : n ] R_0[1 : n] R0[1:n]中的第一个候选框已经大于p。否则持续攻击
六、evaluation
1)实验相关设置
(1)指标
在三个benchmark上进行了实验, OTB100 , LaSOT和GOT10K。实践的网络包括SiamFC, SiamRPN , SiamRPN++和 SiamMask。SiamRPN++有两种不同的网络结构(ResNet-50和MobileNet-v2)。
采用的评估指标如下:
(1)one-pass evaluation (OPE)
- Precision plot
- Success plot
以上两种常见的评估方式一般都是用ground-truth中目标的位置初始化第一帧,然后运行跟踪算法得到平均精度和成功率。这种方法被称为one-pass evaluation (OPE)。这种方法有2个缺点。一是一个跟踪算法可能对第一帧给定的初始位置比较敏感,在不同位置或者帧初始会造成比较大的影响。二是大多数算法遇到跟踪失败后没有重新初始化的机制。
实践的细节如下所示:
通过pytorch实现,并且跑在NVIDIA Tesla V100 GPU上。对每个视频帧,都使用Adam优化器来优化来获得对抗扰动,设置迭代次数为100次,学习率为0.01。
(2)参数设置
Adam优化器的定义如下:
Adam 这个名字来源于自适应矩估计(Adaptive Moment Estimation),也是梯度下降算法的一种变形,但是每次迭代参数的学习率都有一定的范围,不会因为梯度很大而导致学习率(步长)也变得很大,参数的值相对比较稳定。dam 算法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
对于不同的注意力模块,会有不同的超参数。以confidence attention为例,设置a=0.5,b=1.5,c=0.2.对于feature attention,设置a=2,b=-1,c=20.β = 1,α在0.2-0.8之间。p=45,q=90,r=135.
2)攻击结果
(1)OTB100
首先计算Precision,将阈值设置为20;再计算Success,将阈值设置为0.5.由图可以看到,Precision越高,Success应该是越低的。在OTB100数据集上计算上述两个值,对比原始的指标,加了噪声后的指标以及我们攻击后的指标。可以看到,我们攻击的结果比加了噪声的结果好很多。加了噪声后, SiamFC,SiamRPN, SiamRPN++®, SiamRPN++(M)这四个算法模型的precision只降低了 3.1%, 4.5%, 6.4%和 5.7%。而我们攻击后,降低了49.4%, 59.8%, 57.7%,和51.1%。
在OTB100数据集上,对比了原始的结果以及通过我们攻击后的结果,并且绘制了precision plot和success plot。可以看到,在被攻击后,precision和success结果都明显下降。并且这个攻击在 SiamRPN和 SiamRPN++®上表现的最好,就precision这个指标而言,下降了46.2% 和44.4%。
(2)LaSOT
略,具体可见原论文
(3)GOT10K
略,具体可见原论文
(4)分析
通过观察实验结果发现,SiamFC在OTB100和LaSOT上都有很好的鲁棒性,作者推断是因为本文采用的算法欠拟合导致的。SiamFC可以看做是只有一个anchor的 SiamRPN,而太少的anchor会使得SiamFC不能准确的评估target。这样也使得它不容易被攻击。论文的攻击方法在 SiamRPN有最好的攻击效果,可能是因为 SiamRPN的参数太多使得它很难被完全训练。这个问题在 siamRPN++得到了解决,因为 siamRPN++使用了多级架构学习(multi-stage learning),并且有更加有效的互相关性(cross-correlation),正是因为这样,所以 siamRPN++有更好的鲁棒性,难以被攻击。论文的攻击手段在SiamMask上的攻击效果最差,大概是因为SiamMask是多任务学习(multi-task learning)。相比较SiamRPN
和SiamRPN++,SiamMask更加关注于像素级别,使得学习到的特征更加具有鲁棒性。
3) Ablation Study
损失函数只采用 L 1 L_1 L1, L 1 ∗ L^∗_1 L1∗, L 2 L_2 L2, L 2 ∗ L^∗_2 L2∗, L 1 ∗ + L 2 ∗ L^∗_1+L^∗_2 L1∗+L2∗, L 1 + L 2 L_1+L_2 L1+L2,对比查看结果。可以发现,同时采用双重注意力机制下的两个损失函数 L 1 ∗ + L 2 ∗ L^∗_1+L^∗_2 L1∗+L2∗是最好的。
4) Qualitative Evaluation(定性分析)
 在视频帧上进行测试,可以看到上述结果。可以看到,攻击加入的对抗扰动其实是我们人眼看不出来的,但是最后对追踪的结果有很大影响。其中,对SiamFC 和SiamRPN的攻击效果是最明显的,对SiamRPN++的攻击效果没有那么明显。
在视频帧上进行测试,可以看到上述结果。可以看到,攻击加入的对抗扰动其实是我们人眼看不出来的,但是最后对追踪的结果有很大影响。其中,对SiamFC 和SiamRPN的攻击效果是最明显的,对SiamRPN++的攻击效果没有那么明显。