标签:Domain gap;CP without sharing the model information;Late Fusion;3D Object Detection;
论文标题:Model-Agnostic Multi-Agent Perception Framework
发表会议/期刊:
数据集:OPV2V
问题:尽管现有的融合框架已经获得了显著的3D目标检测性能提升,但它们假设所有合作的agent共享一个具有相同参数的模型。这一假设在实践中很难满足,特别是在自动驾驶中。 在自动驾驶汽车之间分享模型参数可能会引起隐私和保密问题,特别是对于来自不同汽车公司的车辆。即使是同一公司的AV,检测模型也可能有不同的版本,这取决于车辆类型和模型更新频率。如果不充分处理这种不一致性,共享的感知信息就会有很大的domain gap,影响协同感知的性能。
1 分析
由于agent使用不同的模型,不同的agent提供的置信度分数可能不一致。一些agent可能过度自信,而其他agent则倾向于自信不足。当使用非最大抑制(NMS)等方法直接融合来自相邻agent的边界框proposals时,由于存在过度自信和低质量的候选者,可能导致检测精度低。
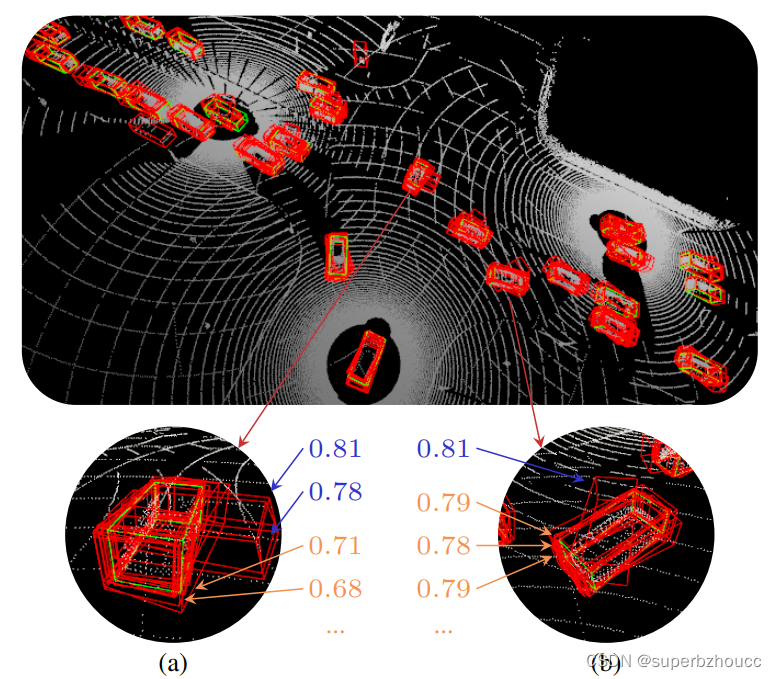
(a) 一些agent的置信度分数大于其他agent的分数,例如,蓝色的分数与橙色的分数相比,蓝色的置信度大于橙色的置信度,但是蓝色的可能是误差很大的置信度,这将误导融合过程。
(b) 橙色的置信度分数虽然较低,但与其他重叠的候选边界框的空间一致性较高,因此,橙色置信度的边界框可能比具有较高置信度分数(蓝色)的边界框更好。
2 方法
- 提出了一个模型无关(model-agnostic)协同感知框架,以处理模型的异质性,其不透露模型设计和参数,具有保密性。另外,为了避免对基础模型详细信息的依赖,agent之间将分享感知输出(即检测到的边界框和置信度分数),感知模型是独立的。
- 在模型无关(model-agnostic)协同感知框架中,提出了一个置信度校准器,即 双重边界缩放( Doubly Bounded Scaling,DBS),以缓解错位的问题。还提出了一个边界框聚合算法,即 促进-抑制聚合(Promote-Suppress Aggregation, PSA),该算法考虑了置信度分数和相邻边界框的空间一致性。
1.1 Model-Agnostic Fusion Pipeline
model-agnostic协同感知:
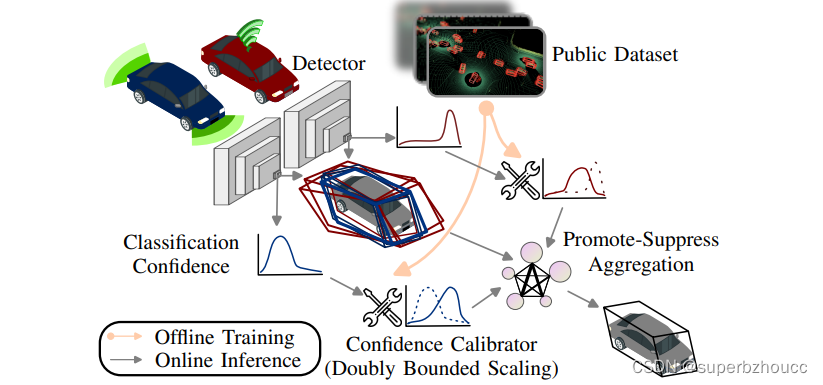
分为两个阶段:
- 离线阶段
由于具有不同感知模型的agent通常会产生不同的置信度分数,置信度分布的不匹配会影响融合的性能。例如,一个较差的模型可能会过度自信,并在融合过程中占主导地位,从而降低了最终检测结果的准确性。为缓解置信度分布的不匹配问题,为每个agent的模型训练一个离线校准器,使其置信度分数与校准数据集上的经验精确度相一致。
1)在同一公共数据集上运行其训练有素的检测器,以产生一个包含标签和置信度分数的特定模型校准数据集。
2)校准数据集被送入置信度校准器(即Doubly Bounded Scaling)进行训练(更多细节见第三部分B)。
3)训练结束后,校准器被保存在每个agent的本地。 - 在线阶段
1)当车辆在道路上行驶并根据传感器的测量结果进行预测时,校准器会将预测的置信度分数向同一标准看齐,从而缓解不匹配现象。
2)然后,边界框坐标和校准的置信度分数被打包在一起,并传输给邻近的agent。
3)接收agent(即ego车辆)将基于空间信息和由网联无人车生成的边界框的校准置信度,通过边界框聚合算法(Promote-Suppress Aggregation)融合共享的信息,产生最终的检测结果。(由于每个agent在离线阶段独立学习其校准器,只在在线阶段共享检测输出,所以检测器的结构和参数对其他agent是不可见的,保护了知识产权。)
1.2 分类置信度校准( Classification Confidence Calibration)
为了消除系统异质性带来的偏差,需要对模型进行良好的校准。设计一个合适的置信度校准器需要满足三个条件:
a. 缩放函数需要是单调的非递减的,因为较高的置信度分数应该表示较高的预期准确度;
b. 缩放函数应该是相对平滑的,以避免对校准集的过度拟合;
c. 缩放函数应该是双重约束的,意味着它将一个置信区间[0,1]映射到同一个[0,1]范围。
Doubly Bounded Scaling 校准器
使用Kumaraswamy累积密度函数(CDF)能满足以上三个约束条件且具有灵活性:
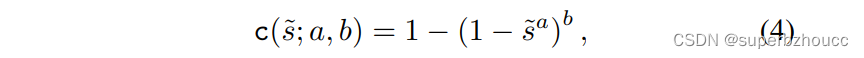
其中,a>0和b>0是参数。遵循以上公式的缩放函数是单调的非递减的、平滑的和双重约束的。对于每个探测器,我们通过最小化二元交叉熵损失来优化校准数据集上的参数a和b。
1.3 促进-抑制聚合算法(Promote-Suppress Aggregation,PSA)
检测模型为同一目标物体输出一堆重叠的候选边界框,因此需要一个后处理步骤,从这些候选框中选择或生成一个最优的边界框。为了选择最优的边界框,提出了 “促进-抑制聚合”(PSA),它同时考虑到了回归和分类的置信度。
Promote-Suppress Aggregation方法
根据IoU值和置信度分数构建一个候选边界框的空间图(Bounding Box Graph),其中每个节点代表一个候选边界框,节点的大小表示边界框的置信度,在校准后有一个相关的置信度分数,节点之间的边权重(每条边的宽度)表示两个边界框的IoU值。Bounding Box Graph是由若干个Connected Components组成,其中每一对节点都通过一系列边连接。
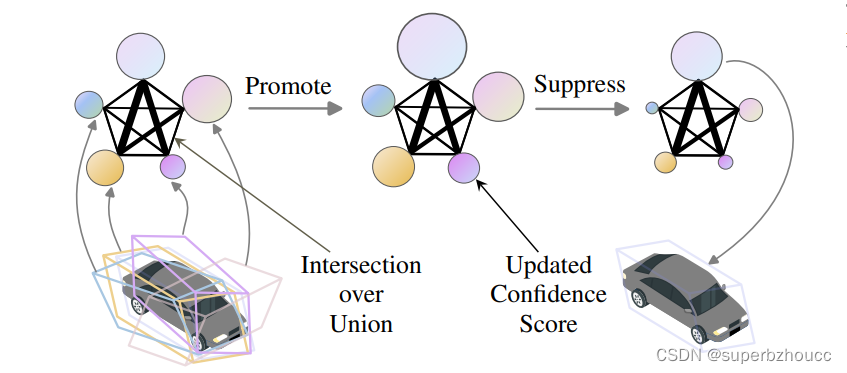
- 在Promote步骤中,IoU的加权置信度分数被传播到邻近的节点,其中,传播规则需满足以下要求:
a. 如果许多其他候选框与该候选框有很大的交集,那么该候选框就应该被promoted;
b. 有许多高置信度分数的重叠边界框的候选框应该被promoted; - 在Suppress步骤中,具有最高更新分数的候选框将抑制其他候选框的分数。最后,选择一个或多个排名在前(几)的边界框。
PSA算法
边界框聚合问题:给定 N N N个候选边界框 B = [ b 1 , . . . , b N ] T B = [b_1, . . . , b_N]^T B=[b1,...,bN]T和他们的置信度分数 s = [ s 1 , . . . , s N ] T s = [s_1, . . . , s_N]^T s=[s1,...,sN]T,以及边界框之间的IoU矩阵 U ∈ [ 0 , 1 ] N × N U∈ [0, 1]^{N×N} U∈[0,1]N×N,目标是选择/过滤出最接近ground-truth边界框的候选边界框,计算得到一个节点索引集 I \mathcal{I} I 。
第3行:基于给定的IoU矩阵,可以找出每个Connected component的顶点索引;
第5-6行:对于每个component,提取IoU矩阵 U m U_m Um和对应于该component的置信度分数向量 s m s_m sm;
第7行:执行promote步骤 s ^ m = U m s m \hat{s}_m=U_{m}s_m s^m=Umsm,每个顶点将其置信度分数更新为component中其他顶点的IoU加权分数之和;
第8行:在suppress步骤中,将更新的分数归一化到[0, 1],并通过softmax筛选出最优的候选边界框;
第9行:如果更新分数大于阈值的顶点索引(候选边界框)被添加到集合中。
总的来说,PSA是高度可并行化的,因为每个component都是独立运行的,每个步骤只需要简单的线性搜索或小的矩阵向量乘法。
总结
在协同感知的背景下,来自不同利益相关的agent具有异质性的模型。为了保密起见,与模型和参数有关的信息不应透露给其他agent。本文提出了一个与模型无关model-agnostic协同感知框架,解决了后期融合策略的两个关键挑战。
1. 提出了一个置信度校准器,以统一不同agent的分类置信度分布,消除预测的置信度分数偏差。
2. 提出了一个边界框聚合算法,该算法同时考虑了校准的分类置信度和边界框回归给出的空间一致性信息。