目录
互动和多样性有收益
我之前反复看这篇文章 我觉得起作用的就是 他减掉了 user embedding和item embedding的norm大小的影响
KDD2021 | MACR: 模型无关的纠正推荐系统流行度偏差的因果推理方法
推荐系统的总体目标是为用户提供个性化的建议,而不是推荐热门物品,然而正常的训练范式,即拟合一个推荐模型来重建观测到的用户行为数据,会使得训练模型偏向于推荐流行商品,从而导致马太效应,即流行的物品被更频繁地推荐,并变得更加流行。
该论文从一个全新的视角——因果关系的角度来探讨推荐系统中的流行度偏差问题。该文章指出,流行度偏差存在于因果图中物品节点对排名分数的直接影响之中,也就是说物品的内在属性是错误地赋予某些物品过高排名分数的原因。文章认为为了纠正这种偏差,有必要考虑一个反事实的问题,即如果推荐模型只输入物品相关信息,那么它的排名分数将是多少。为此,该论文用因果图来描述推荐过程中的重要因果关系,在模型训练过程中,论文采行多任务学习的方式,建模每一项因果关系对于推荐得分的贡献,并在模型测试过程中采用反事实推理的方法来消除流行度对于推荐的影响。
研究背景
目前针对这个问题的去偏算法主要可以分成三类:(1)逆权重分数:估计物品流行度的倾向性权重,并对每条数据样本利用逆权重分数进行加权。(2)加入无偏数据:通过从额外的无偏数据中学习来纠正流行度偏差。(3)分解嵌入表示:将兴趣和流行度分解为两套嵌入模型,并调整使得模型学习到更鲁棒的模式。
文章认为,消除流行度偏差的关键是了解物品流行如何影响每次交互,而不是盲目地将增加长尾物品的权重。
方法介绍
因果图的建立
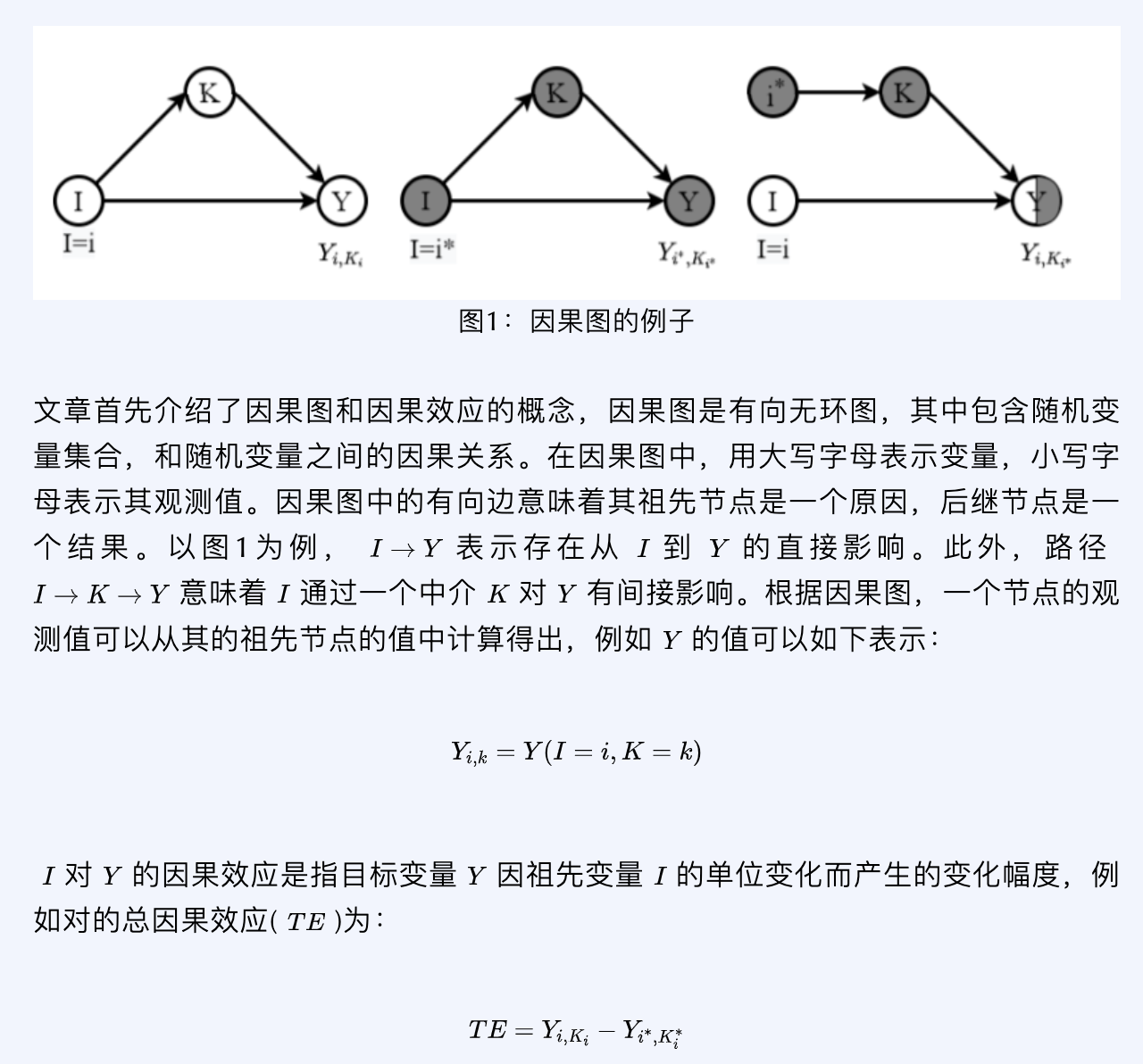
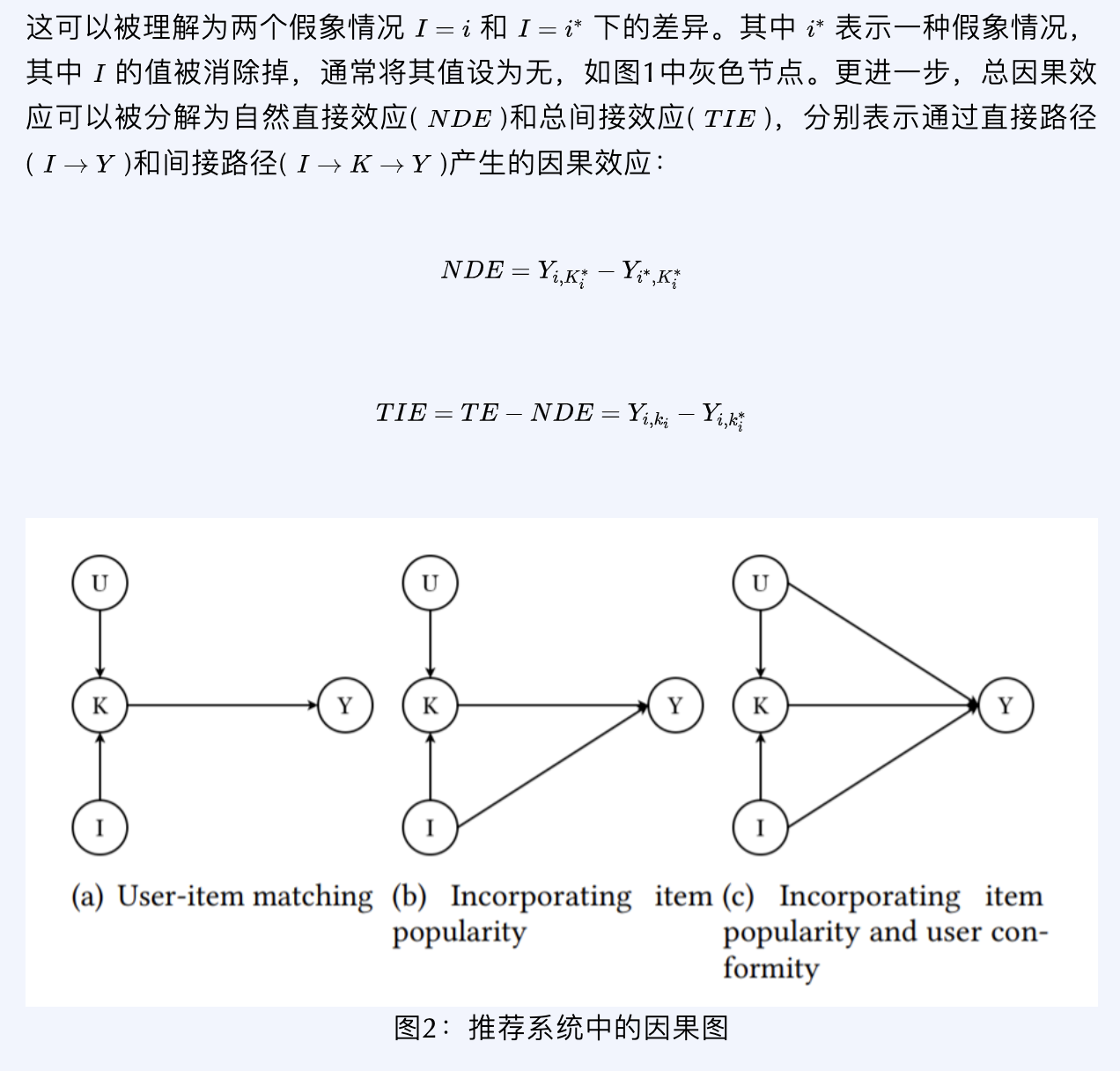

建模因果效应
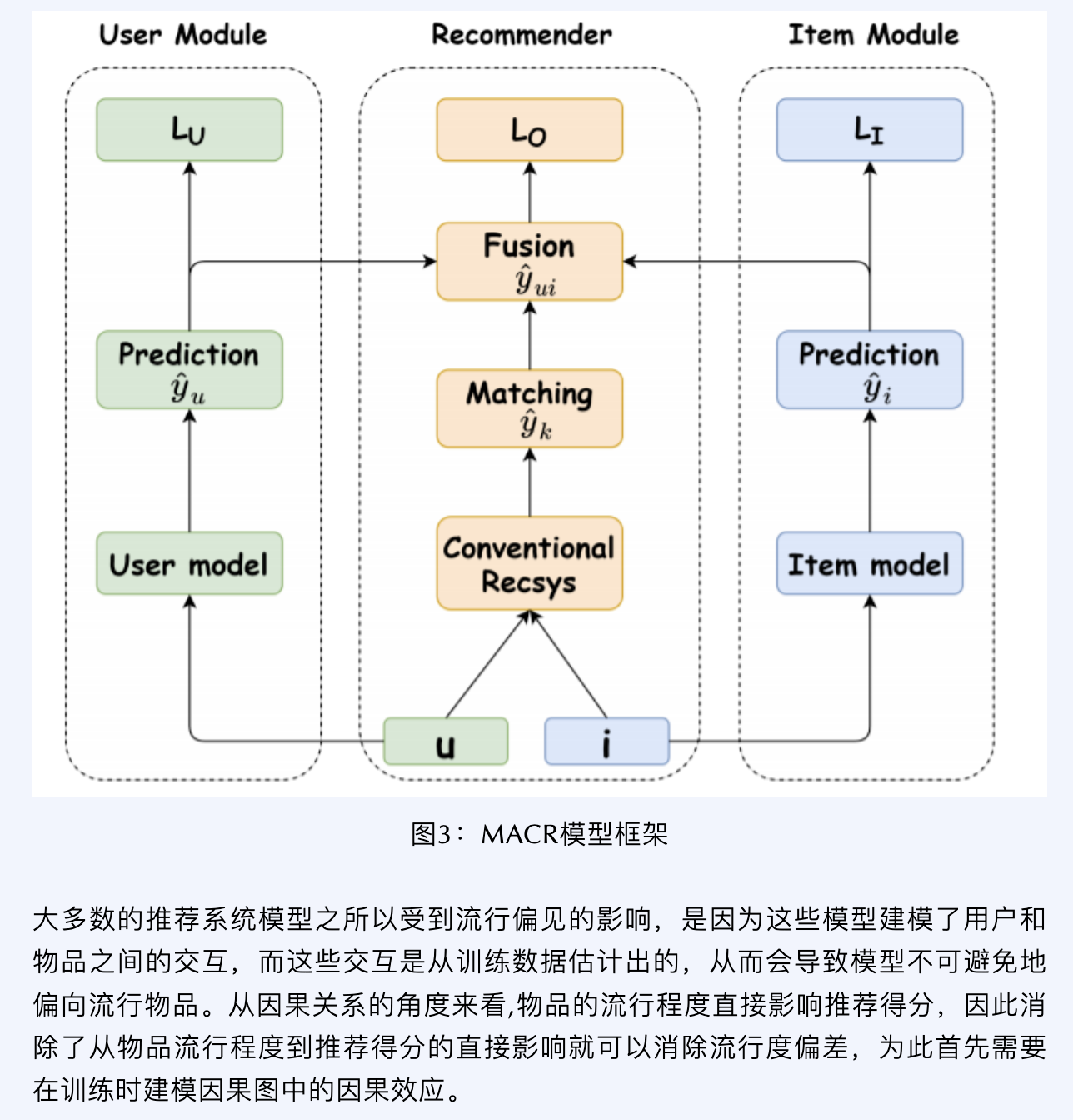


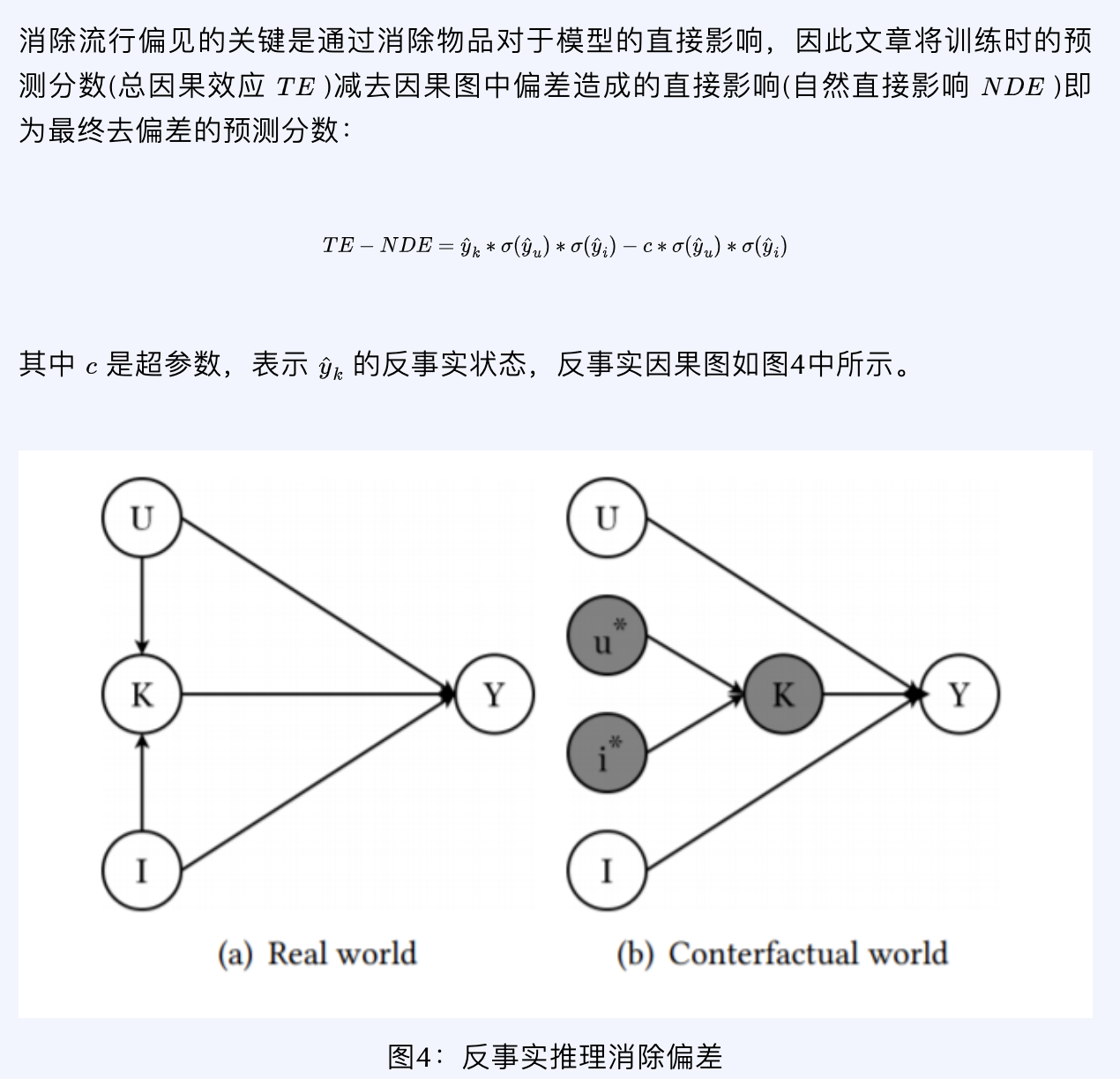
消除流行度影响

心得体会

代码
具体细节还没跑