标签:Pose Errors;3D Detection; Motion Forecasting;Intermediate Collaboration;
论文标题:Learning to Communicate and Correct Pose Errors
发表会议/期刊:4th Conference on Robot Learning (CoRL 2020), Cambridge MA, USA
数据集:V2V-Sim
问题:在协同自动驾驶中,每个车辆的精确定位(pose信息)将用于对特征图进行空间对齐。但是,在实际应用中,车辆定位通常存在噪声( pose噪声),通过无线通信传输车辆可能会接收到的错误信息。所以,在存在 pose噪声的情况下,会损害协同自动驾驶系统的性能,甚至可能比单车感知的性能还差。
本文方法
本文基于V2VNet协同感知预测框架,提出了一个通信可学习的神经网络模型用于校正 Pose Errors,车辆之间通过分享中间特征图,以协作的方式联合进行目标检测和motion预测。
Motion预测:对感知模块所检测到的运动物体进行未来一段时间内行为意图的预测,并将预测的结果转化为时间维度和空间维度的轨迹。
1 Pose Errors纠正
本文研究了V2VNet中提出的设置,即附近的自动驾驶车辆以协作的方式联合进行目标检测和motion预测。本文遵循V2VNet的设置,通过分享中间特征图,因为它实现了更好的性能和更有效的通信。
1.1 V2VNet
带pose噪声的V2V通信设置下的V2VNet:
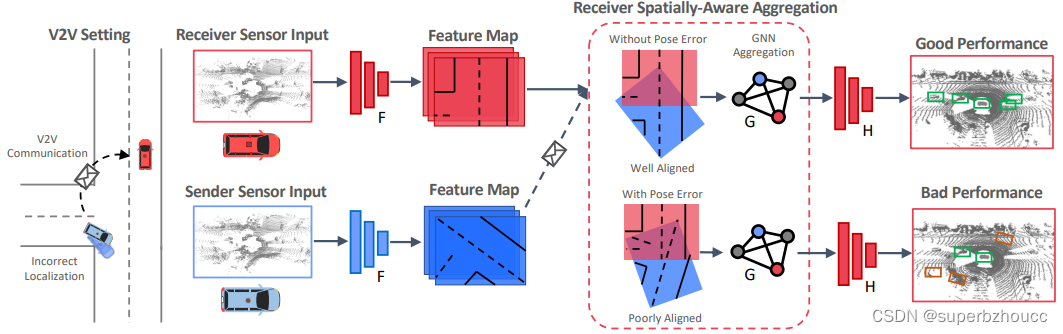
1)V2VNet将LiDAR点云体素化为15cm3的体素,并沿着高度维度将它们串联起来,形成一个鸟瞰视角的输入表示。
2)通过一个二维CNN(F)处理,生成空间特征图。
3)每个自动驾驶车辆(SDV)压缩并向附近的SDV广播这些空间特征图。
4)当接收车辆收到来自其他车辆的特征图时,使用自己的pose和发送车辆的pose来计算相对pose以将接收到的特征图从发送车辆的视角转换到自己的视角下,然后通过图神经网络(GNN)G将特征图进行汇总聚合。
5)融合后的特征经过一个CNN(H)预测最终的输出(目标检测:用3D位置、宽度、高度和方向表示,motion预测:未来time steps的目标位置)。
由于在特征信息共享和聚合的过程中,pose噪声会导致特征空间对齐错位,最终影响目标检测和motion预测精度。因此,V2VNet容易受到pose噪声的影响,在现实的噪声存在的情况下,V2VNet的性能可能比单车感知预测更差。
Pose notation:由于输入LiDAR点云处理是以鸟瞰视图进行的,这里将每个pose表示为由两个平移分量和一个旋转角度组成的一个矢量。
1.2 抗pose噪声的鲁棒通信
为了提高V2VNet对pose噪声的鲁棒性,在特征图空间对齐步骤之前,提出了一个 end-to-end可学习模块,主要由3部分组成,其中,pose回归模块和consistency模块用来修复pose errors。在特征聚合之前,注意力模块将学习预测一个二进制注意力权重,用于特征信息的加权平均以过滤掉噪声信息。(相比之下,V2VNet在GNN步骤中执行的是统一平均,而不是加权平均。)

1. Pose回归模块:预测一对车辆之间的相对pose噪声。
2. Consistency模块:为了保证同一Object的pose信息的全局一致性,提出了一个基于 Markov random field with Bayesian reweighting 的consistency模块。(pose一致性:一个object的pose从多个agent的角度来看应该是一致的。)通过在所有的SDV中找到一组全局一致的绝对poses来完善回归模块输出的相对pose估计,让SDV对彼此的绝对pose达成全局共识,以进一步减少pose error。
3. 注意力聚合模块:在通信信息聚合步骤中,使用通过预测得到的注意力权重来减弱(过滤)车辆之间的异常信息(噪声)。
这些模块采用end-to-end的联合学习方式,以改善目标检测和motion预测性能。
1.2.1 pose回归模块
每个自动驾驶车辆的pose都有一个pose噪声估计 ξ ~ i \tilde{\xi }_i ξ~i,并且会接收附近车辆发送的带有噪声的pose,以用于计算从发送车辆到接收车辆的pose相对变换 ξ ~ j i \tilde{\xi}_{ji} ξ~ji(含噪声)。
- 将接收车辆捕获的特征 m i m_i mi和经过坐标系转换后的发送车辆捕获的特征 m j i m_{ji} mji进行拼接,输入一个CNN来学习接收车辆和发送车辆捕获的特征图之间的差异 c ^ j i \hat{c}_{ji} c^ji;
- 基于pose相对变换 ξ ~ j i \tilde{\xi }_{ji} ξ~ji(含噪声),计算真实相对变换: ξ ^ j i = c ^ j i ∘ ξ ~ j i \hat{\xi}_{ji}=\hat{c}_{ji}\circ \tilde{\xi }_{ji} ξ^ji=c^ji∘ξ~ji(注:对每条有向edge进行独立的预测,所以 ξ ^ j i ≠ ξ ^ i j − 1 \hat{\xi}_{ji}\neq\hat{\xi}^{-1}_{ij} ξ^ji=ξ^ij−1)。
1.2.2 consistency模块
将consistency 拟定为 Markov随机场(MRF),其中,每个车辆的pose为一个节点。
1)由于pose回归模块预测的相对pose误差会有很多异常值,这里假设每个pose ξ i \xi_i ξi服从一个以相对pose为条件的均值为 ξ i ∈ R 3 \xi_i\in\mathbb{R}^3 ξi∈R3 scale为 Σ i ∈ R 3 × 3 Σ_i\in R^{3 \times 3} Σi∈R3×3的多变量 student t-distribution。
2)对edge potentials进行重新加权,来减少错误的pose回归输出的权重,从而减少低权重的项对估计值的影响。
3)对每个权重 w j i w_{ji} wji使用一个均值为两个特征图之间的空间重叠率的 Gamma先验分布,那么如果两个特征图之间有更多的空间重叠,pose预测的置信度就更高。
二元势(pairwise potentials)由三部分组成:似然、权重和权重预设
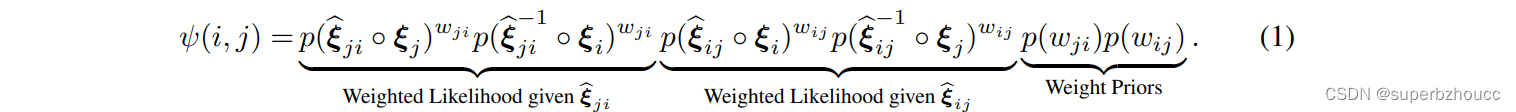
似然项 p ( ξ ^ j i ◦ ξ j ) p(\hat{ξ}_{ji}◦ξ_j ) p(ξ^ji◦ξj)和 p ( ξ ^ i j − 1 ◦ ξ j ) p(\hat{ξ}_{ij}^{-1} ◦ξ_j) p(ξ^ij−1◦ξj),都是以 ξ i ξ_i ξi为中心的t分布。二元势鼓励从发送车辆处获得的pose ( ξ j ξ_j ξj) 经过相对pose变换后,接近于目标车辆的pose ( ξ i ξ_i ξi)。
通过使所有二元势(pairwise potentials) 的乘积最大化,来优化绝对pose ξ i \xi_i ξi,scale参数 Σ i Σ_i Σi,以及权重 w j i w_{ji} wji:
然后,使用这些估计的poses来更新空间对齐所需的相对变换。
1.2.3 注意力聚合模块
经过pose回归模块预测和consistency模块完善后的相对pose变换可能仍有一些信息存在噪声。为了进一步过滤噪声信息,提出了一个简单的attention机制,给每个特征分配一个权重。
1)采用一个CNN 来学习权重 s j i ∈ R s_{ji}∈\mathbb{R} sji∈R,并对其进行归一化:
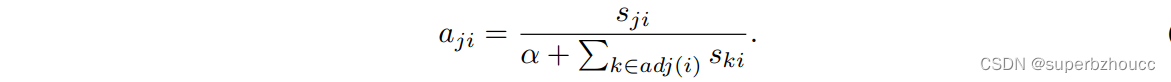
2)基于权重,对自车和所有接收到的信息进行聚合:
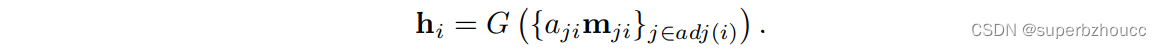
3)聚合信息再经过一个CNN来预测目标检测的边界框和未来一段时间内目标物体的行动轨迹。
1.3 训练
- Supervising attention:训练V2VNet和attentipn网络
为了判别样本是否带有噪声,把样本噪声识别当作一个有监督的二元分类任务。
对于训练数据和标签,在一个场景中对一些车辆的样本添加强pose噪声,对其他车辆添加弱pose噪声。跟pose一样,噪声有两个平移分量和一个旋转分量 ( x , y , θ ) (x,y,θ) (x,y,θ)。中心位置 ( x , y ) (x,y) (x,y)的强和弱噪声分别从μ=0,σ=0.4和σ=0.01的高斯分布中提取;rotational强噪声和弱噪声分别从μ=0,σ= 4 ∘ 4^\circ 4∘和σ= 0. 1 ∘ 0.1^\circ 0.1∘的von Mises分布中提取。
当考虑一个协同感知信息时,如果两个agent都有来自弱分布的噪声,则认为该协同感知信息是不存在噪声的;而当其中任何一个agent有来自强分布的噪声时,则认为是有噪声的,即:
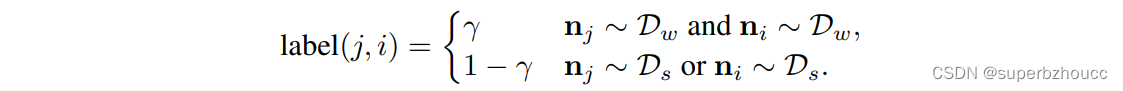
由此产生smoot标签用来调节注意力模块的权重预测,所以注意力的权重不只是0或1。联合训练任务的损失定义如下:
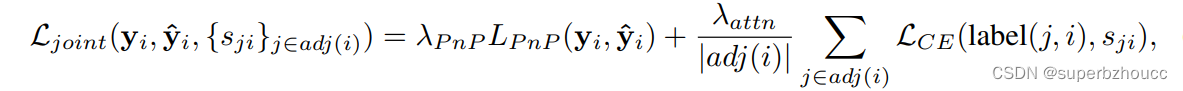
其中 L C E L_{CE} LCE是二元交叉熵损失。 - Pose回归
V2VNet和attention训练好之后,将其冻结,只使用pose的每个坐标的损失之和 L c L_c Lc来训练pose回归模块(在这个阶段,所有的SDV都从强噪声分布 D s D_s Ds中获得噪声):
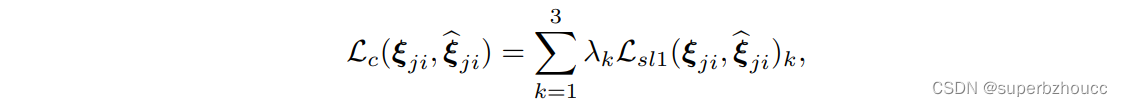
λ = [ λ p o s , λ p o s , λ r o t ] λ=[λ_{pos}, λ_{pos}, λ_{rot}] λ=[λpos,λpos,λrot], L s l 1 L_{sl1} Lsl1为smooth L1损失。最后,用组合损失 L = L c + L t a s k L = L_c + L_{task} L=Lc+Ltask对整个网络进行end-to-end微调。
2 实验
在各种噪声环境下,对所提出的方法的检测、预测和pose correction进行了评估。
2.1 实验设置
- 数据集
在V2V-Sim仿真数据集上训练模型,该数据集从多个自动驾驶车辆的视角模拟LiDAR点云,每个场景最多包含7辆SDV。火车/测试部分有46,796/4,404帧,其中每帧包含5个LiDAR扫描。 - 评价指标
目标检测性能:IoU为0.7的平均精度(AP)
motion预测性能:物体中心位置在未来时间步长(例如,未来3s)的 l 2 l_2 l2位移误差对true positives的测量。true positives是一个检测,其中IoU阈值为0.5,置信度阈值设置为召回率为0.9(如果不能达到0.9,选择最高召回率)。
pose correction性能:平均绝对误差(MAE)和均方根误差(RMSE)。 - 噪声模拟
在训练过程中,position强和弱噪声分别从μ=0,σ=0.4和σ=0.01的高斯分布中提取;rotational强噪声和弱噪声分别从μ=0,σ= 4 ∘ 4^\circ 4∘和σ= 0. 1 ∘ 0.1^\circ 0.1∘的von Mises分布中提取。 - Competitive method
将所提出的方法与Learn2Sync相比较,后者在寻找全局一致的pose时考虑深度图对来迭代地重新权衡pairwise registrations。在评估过程中,Learn2Sync被用来代替本文提出的consistency模块。 - 数据增强baseline
V2VNet作为一个简单baseline在有pose噪声的情况下训练,作为一种输入数据增强的形式,这要求网络隐含地处理姿势噪声,而不是明确地纠正噪声。
3 总结
基于V2VNet协同感知框架,在其特征图空间对齐步骤之前,提出了一个 end-to-end可学习模块,以提高在存在pose errors的情况下的协同自动驾驶系统中感知和motion预测的鲁棒性。在相同的带pose errors的数据集上与原始V2VNet对比,所提出的模型在较大的pose噪声下可以保持相同的性能。
局限:还可利用传入信息中pose error的时间一致性来提高性能。目前考虑的pose噪声服从高斯分布,可能无法纠正更普遍的通信噪声类型。训练数据中需要ground-truth pose,但是ground-truth 在现实中不存在。