论文标题:Collaborative 3D Object Detection for Automatic Vehicle Systems via Learnable Communications
发表期刊/会议:暂未发表
数据集:CARLA-3D
任务:考虑使用自车本地点云数据,并通过无线通信来结合来自邻近路边设施的信息,进行协同3D目标检测。
挑战:在预定义的通信方案中,共享所有的信息是不现实的,需要防止传输大量的或无意义的信息。为了让agent自己学习通信协议,大多数现有的方法通过学习一个多个agents共享的DNN将传感器观察结果编码为特征,然后根据注意力机制融合所有agent的特征,最后将融合后的特征解码用于感知或决策。但是,在一个完全连接的graph上传输特征图会带来很高的通信成本和延迟,特别是当跨agent的带宽有限时。
1 协同3D目标检测框架
提出了一个注意力通信模型,使车辆能够以端到端的深度学习方式学习有效的通信。受注意力机制的启发,设计了一个注意力模块,其从其他连接的路边设施接收编码后的局部视觉观测数据,并确定应该与哪个相邻的路边设施进行通信以进行协同检测。每个路边设施在其本地信息和收到的来自车辆的信息之间计算学习得到一个匹配分数。然后,自车根据这个分数选择一个邻近的路边设施来进行通信组。另外,注意力模型学习有关特征重要性的权重,以进行协同3D目标检测。
自动驾驶系统中的协同3D目标检测框架:
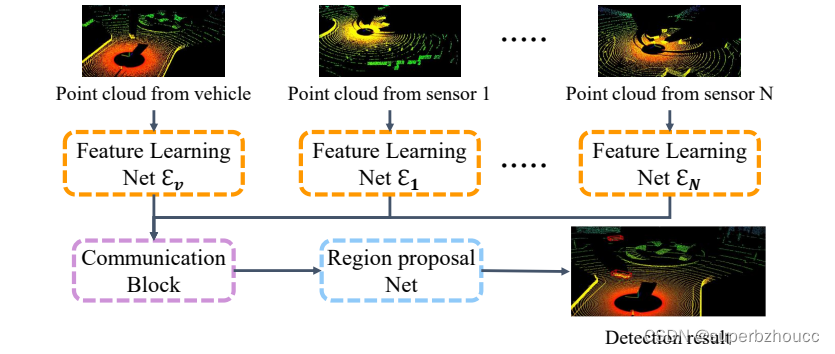
所提出的协同目标检测框架是基于PointPillars的,输入包括车辆和路边设施的点云数据,输出是车辆预测的目标物体标签和3D边界框。由三个主要部分组成:
1)特征学习网络:将输入的点云转换为伪图像,即映射为本地的特征图;
2)基于注意力的通信模块:构建车辆和路边设施之间的通信和合作;
3)区域生成网络(RPN):融合车辆和路边设施的特征图,并预测目标检测结果。
1.1 特征学习网络
为了处理通信信息和探测特征,路边设施和车辆首先将其收集的点云转换为伪图像。
特征学习网络结构:
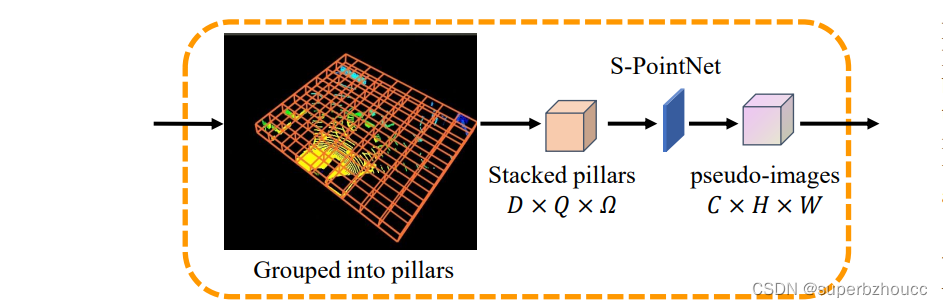
与Pointpillars的第一阶段类似,每个路边设施和车辆使用编码器将其收集的点云编码为特征图,编码过程包括三个步骤:
1)将点云均匀网格化为多个大小一定的pillars,每个pillar包含Ω个点。当一个pillar中的点的数量大于Ω时,随机选择Ω个点;当pillar中点的数量小于Ω时,进行零填充以获得Ω点。
2)通过简化版的PointNet(S-PointNet)来学习得到特征图(S-PointNet包括一个线性层,批量归一化(BN)和修正线性单元(ReLU));
3)特征图被散射回原始pillars的位置,生成大小为C×H×W的伪图像,其中C、H和W分别表示通道数、长度和宽度。
1.2 基于注意力的通信模块
通信模块被用来确定应该与哪些相邻的路边设施进行通信以提高感知的准确性。
基于注意力的通信模块结构:
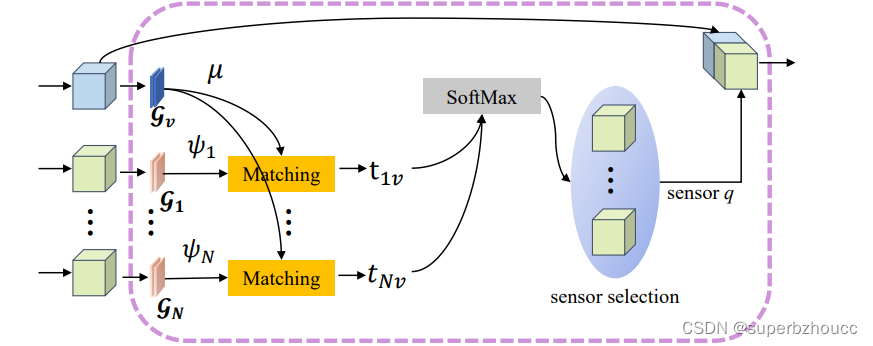
由三个步骤组成:
1)为了处理query信息,车辆首先使用query网络 G v \mathcal{G}_v Gv将伪图像编码为紧凑的query特征 μ = G v ( F v ) μ=\mathcal{G}_v(F_v) μ=Gv(Fv),并将query信息广播给其附近的路边设施;
2)每个相邻的路边设施使用key网络 G i \mathcal{G}_i Gi将伪图像编码为key特征 ψ i = G i ( F i ) ψ_i = \mathcal{G}_i(F_i) ψi=Gi(Fi),并使用一般注意力机制来计算收到的query信息和其本地key信息之间的匹配分数 t i v t_{iv} tiv,然后将分数发送给车辆;
3)车辆使用softmax层将这些分数规范化为一个概率分布,然后根据规范化后的分数选择一个匹配分数最大的路边设施进行特征融合。具体来说,通过将注意力得分与路边设施提取到的特征相乘来生成注意力精炼特征图,将其与车辆本地提取特征串联起来,生成最终融合的特征图。
1.3 区域生成网络
由骨干网和检测头组成的区域生成网络被用来对目标进行分类和预测边界框。
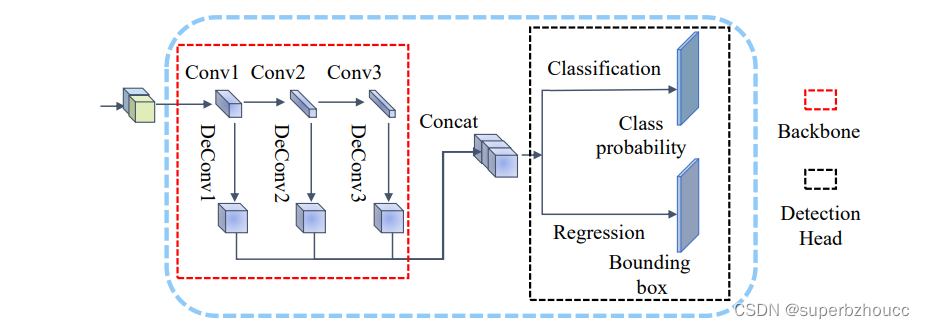
受Pointpillars中使用的区域生成网络的启发,主干网络与Voxelnet使用的CNN架构相似,以三种不同的空间分辨率处理特征,将来自3个不同卷积块的特征图合并起来,构建一个高分辨率的特征图。之后,高分辨率的特征图通过SSD检测头进行分类和边界框预测。
区域生成网络的结构细节:

2 实验
2.1 数据集
使用CARLA模拟器开发了一个合成的协同3D目标检测数据集,命名为CARLA-3D。在CARLA-3D中,多辆自动驾驶汽车在城市环境中行驶,其中有各种静态物体的3D模型,以及动态物体如车辆和行人。所有的模型都有一个共同的比例,它们的大小与现实世界中的物体相对应。通过改变元素的数量,包括道路、人行道、房屋、植被、交通基础设施和动态物体的位置,模拟了两个不同的城市驾驶场景(一个环岛和一个T型路口)。在环岛场景中捕获了1788帧数据,在T形路口捕获了1610帧数据。每一帧都包含来自车辆和基础设施传感器的点云以及描述所有物体的地面真实位置、方向、大小和类别的物体列表。数据集中的物体包括车辆和行人。任何时间段的最大物体数设定为60,包括10个行人和50个车辆。行人的状态是跑步或走路,跑步的行人的概率是0.8。将汽车和卡车视为车辆,其中车辆被设定为汽车的概率为0.8。训练集、验证集和测试集在数据集中按6 : 2 : 2的比例随机选择。
2.2 评估指标
目标检测性能:平均精度(AP);准确率是由精确率和召回率得出的,取决于概率分数和交互联合(IoU)的单值度量。为了进行物体检测的AP计算,首先计算IoU。IoU:预测边界框和ground truth边界框的交集体积和联合体积的比率。
通信成本:精度-带宽使用量(AIB)。
3 总结
- 提出了一个协同感知框架(Learn2com)使用LiDAR点云数据进行3D目标检测,通过注意力通信机制学习与路边设施智能地进行通信,从而在每个时间段只与一个邻近路边设施进行通信以节省带宽 ,达到提高目标检测精度和减少传输带宽的平衡。
- 为了评估所提出框架的有效性,使用CARLA模拟器构建了一个仿真数据集CARLA-3D。