Paper :https://arxiv.org/pdf/1703.03400.pdf Code :https://github.com/cbfinn/maml Tips:ICML的一篇Meta-learning相关的paper,可参考李宏毅的公开课。 (阅读笔记)
A
:
\mathcal{A:}
A :
B
:
\mathcal{B:}
B :
C
:
\mathcal{C:}
C :
D
:
\mathcal{D:}
D :
A
:
\mathcal{A:}
A :
B
:
\mathcal{B:}
B :
C
:
\mathcal{C:}
C :
D
:
\mathcal{D:}
D :
每个模型就是找到
f
θ
f_{\theta}
f θ
x
t
x_t
x t
a
t
a_t
a t
T
i
\mathcal{T_i}
T i
T
i
:
{
H
;
q
i
;
L
T
i
}
\mathcal{T_i}:\{H; q_i; \mathcal{L_{\mathcal{T_i}}}\}
T i : { H ; q i ; L T i }
H
H
H
H
=
1
H=1
H = 1
H
H
H
q
i
q_i
q i
C
a
s
e
(
H
=
1
)
Case(H=1)
C a s e ( H = 1 )
q
(
x
1
)
q(x_1)
q ( x 1 )
C
a
s
e
(
H
>
1
)
Case(H>1)
C a s e ( H > 1 )
q
(
x
t
+
1
∣
x
t
,
a
t
)
q(x_{t+1}|x_t,a_t)
q ( x t + 1 ∣ x t , a t )
t
t
t
a
t
a_t
a t
L
T
i
\mathcal{L_{\mathcal{T_i}}}
L T i
x
t
x_t
x t
a
t
a_t
a t
x
1
x_1
x 1
a
1
a_1
a 1
有一个有很多不同任务的分布
p
(
T
)
p(\mathcal{T})
p ( T )
N
−
w
a
y
s
;
K
−
s
h
o
t
N-ways;K-shot
N − w a y s ; K − s h o t
T
i
\mathcal{T_i}
T i
如果整体训练的话,可能是整体的好,可能并不会单独的某个任务好。For example, a neural network might learn internal features that are broadly applicable to all tasks in
p
(
T
)
p(\mathcal{T})
p ( T )
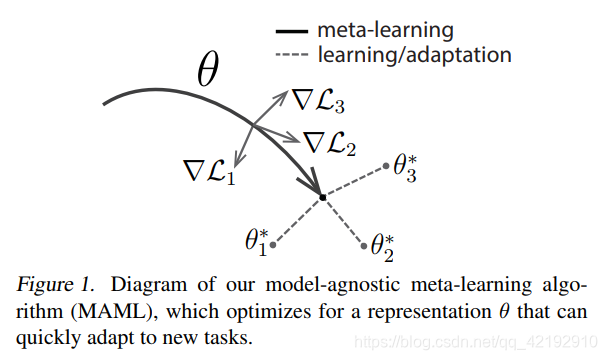
如下图所示,梯度的方向。其中
θ
\theta
θ
T
i
\mathcal{T_i}
T i
T
1
,
2
,
3
\mathcal{T}_{1,2,3}
T 1 , 2 , 3
▽
L
i
\bigtriangledown \mathcal{L_i}
▽ L i
θ
\theta
θ
θ
1
,
2
,
3
∗
\theta_{1,2,3}^*
θ 1 , 2 , 3 ∗
θ
i
∗
=
θ
−
α
▽
θ
L
T
i
(
f
θ
)
\theta_{i}^*=\theta-\alpha \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_\theta)
θ i ∗ = θ − α ▽ θ L T i ( f θ )
θ
i
∗
\theta_{i}^*
θ i ∗
i
i
i
T
i
\mathcal{T_i}
T i
θ
\theta
θ
θ
\theta
θ
f
θ
f_\theta
f θ
L
T
i
\mathcal{L_{\mathcal{T_i}}}
L T i
α
\alpha
α
θ
\theta
θ
p
(
T
)
p(\mathcal{T})
p ( T )
f
θ
f_\theta
f θ
f
θ
∗
f_\theta^*
f θ ∗
min
θ
∑
T
i
∼
p
(
T
)
L
T
i
(
f
θ
i
∗
)
=
∑
T
i
∼
p
(
T
)
L
T
i
(
f
θ
−
α
▽
θ
L
T
i
(
f
θ
)
)
θ
←
θ
−
β
▽
θ
∑
T
i
∼
p
(
T
)
L
T
i
(
f
θ
i
∗
)
\min_{\theta} \sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})=\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta-\alpha \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_\theta)})\\ \theta \leftarrow \theta- \beta \bigtriangledown_\theta\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})
θ min T i ∼ p ( T ) ∑ L T i ( f θ i ∗ ) = T i ∼ p ( T ) ∑ L T i ( f θ − α ▽ θ L T i ( f θ ) ) θ ← θ − β ▽ θ T i ∼ p ( T ) ∑ L T i ( f θ i ∗ ) First-order approximation:每一次优化都是对损失函数
L
T
i
\mathcal{L_{\mathcal{T_i}}}
L T i
θ
\theta
θ
θ
i
∗
\theta_i^*
θ i ∗
T
i
\mathcal{T_i}
T i
θ
\theta
θ
▽
θ
∑
T
i
∼
p
(
T
)
L
T
i
(
f
θ
i
∗
)
=
∑
T
i
∼
p
(
T
)
▽
θ
L
T
i
(
f
θ
i
∗
)
\bigtriangledown_\theta \sum_{\mathcal{T_i} \sim p(\mathcal{T})} \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})=\sum_{\mathcal{T_i} \sim p(\mathcal{T})} \bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}}(f_{\theta_i^*})
▽ θ T i ∼ p ( T ) ∑ L T i ( f θ i ∗ ) = T i ∼ p ( T ) ∑ ▽ θ L T i ( f θ i ∗ )
θ
\theta
θ
j
j
j
θ
k
∗
\theta_k^*
θ k ∗
θ
∗
\theta^*
θ ∗
i
i
i
k
k
k
▽
θ
L
T
i
=
∂
L
(
θ
∗
)
∂
θ
j
→
∑
k
∂
L
(
θ
∗
)
∂
θ
k
∗
×
∂
θ
k
∗
∂
θ
j
\bigtriangledown_\theta \mathcal{L_{\mathcal{T_i}}} = \frac{\partial \mathcal{L(\theta^*)}}{\partial \theta_j} \rightarrow \sum_{k} \frac{\partial \mathcal{L(\theta^*)}}{\partial \theta_k^*} \times \frac{\partial \theta_k^*}{\partial \theta_j}
▽ θ L T i = ∂ θ j ∂ L ( θ ∗ ) → k ∑ ∂ θ k ∗ ∂ L ( θ ∗ ) × ∂ θ j ∂ θ k ∗
θ
∗
\theta^*
θ ∗
θ
\theta
θ
∂
θ
k
∗
∂
θ
j
=
∂
(
θ
k
−
α
×
∂
L
(
θ
)
∂
θ
k
)
∂
θ
j
\frac{\partial \theta_k^*}{\partial \theta_j} = \frac{\partial (\theta_k-\alpha \times \frac{\partial \mathcal{L(\theta)}}{\partial \theta_k} )}{\partial \theta_j}
∂ θ j ∂ θ k ∗ = ∂ θ j ∂ ( θ k − α × ∂ θ k ∂ L ( θ ) )
k
k
k
j
j
j
∂
θ
k
∂
θ
j
\frac{\partial \theta_k}{\partial \theta_j}
∂ θ j ∂ θ k
−
α
×
∂
2
L
(
θ
)
∂
θ
j
∂
θ
k
-\alpha \times \frac{\partial^{2}\mathcal{L(\theta)}}{\partial \theta_j \partial \theta_k}
− α × ∂ θ j ∂ θ k ∂ 2 L ( θ )
k
k
k
j
j
j
1
−
α
×
∂
2
L
(
θ
)
∂
θ
j
∂
θ
k
1-\alpha \times \frac{\partial^{2}\mathcal{L(\theta)}}{\partial \theta_j \partial \theta_k}
1 − α × ∂ θ j ∂ θ k ∂ 2 L ( θ )
benchmark一般用的数据集是Omniglot和mini-ImageNet。更具体地 :MAML与迁移学习相关的pre-training是有区别的:
MAML是对很多组support/query set不同的task进行训练,所以模型在每一组任务的表现都会是同等条件下训练的最好结果,但是其得到的
ϕ
\phi
ϕ
θ
^
n
\hat{\theta}^n
θ ^ n
Pre-training是很多种不同的数据一同收敛到最优的地方,但不一定是每个具体某一类数据最优的地方,所以其处理的参数一直都是整体的参数
ϕ
\phi
ϕ
L
(
ϕ
)
=
∑
n
=
1
N
L
n
(
θ
^
n
)
L
(
ϕ
)
=
∑
n
=
1
N
L
n
(
ϕ
)
\mathcal{L(\phi)}=\sum_{n=1}^{N}L^n(\hat{\theta}^n) \\ \mathcal{L(\phi)}=\sum_{n=1}^{N}L^n(\phi)
L ( ϕ ) = n = 1 ∑ N L n ( θ ^ n ) L ( ϕ ) = n = 1 ∑ N L n ( ϕ )
https://danieltakeshi.github.io/2018/04/01/maml/