标签:V2V;Point cloud based 3D object detection;Intermediate Fusion;Lossy Communication;Packets Loss;
论文标题:Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication
发表会议/期刊:
数据集:OPV2V
问题:现有的基于中期融合策略的V2V协同感知算法都假设了理想的V2V通信,但是,在现实交通场景中,V2V通信很容易受到许多外界因素的影响造成数据包丢失。共享的数据也可能在传输过程中受到其他信号的干扰或被attackers修改,导致数据的损失。Lossy Communication在现实世界中很常见,不完整或不准确的共享信息降低了协同感知性能。
1 LC-aware特征融合方法
由于本文主要解决数据传输过程中的Lossy Communication问题,假设V2V系统中没有通信延迟或定位错误。
提出了一种intermediate LC-aware 特征融合方法,其中,设计了一个LC-aware Repair Network (LCRN) 来修复由Lossy Communication引起的不完整共享特征,还提出了一个V2V Attention Module(V2VAM)来加强Ego和其他车辆之间的interaction。
LC-aware特征融合框架
选择其中一个CAV作为Ego车辆,在其周围构建一个空间节点图,每个节点表示通信范围内的CAV,每条边代表一对节点之间的定向V2V通信通道。
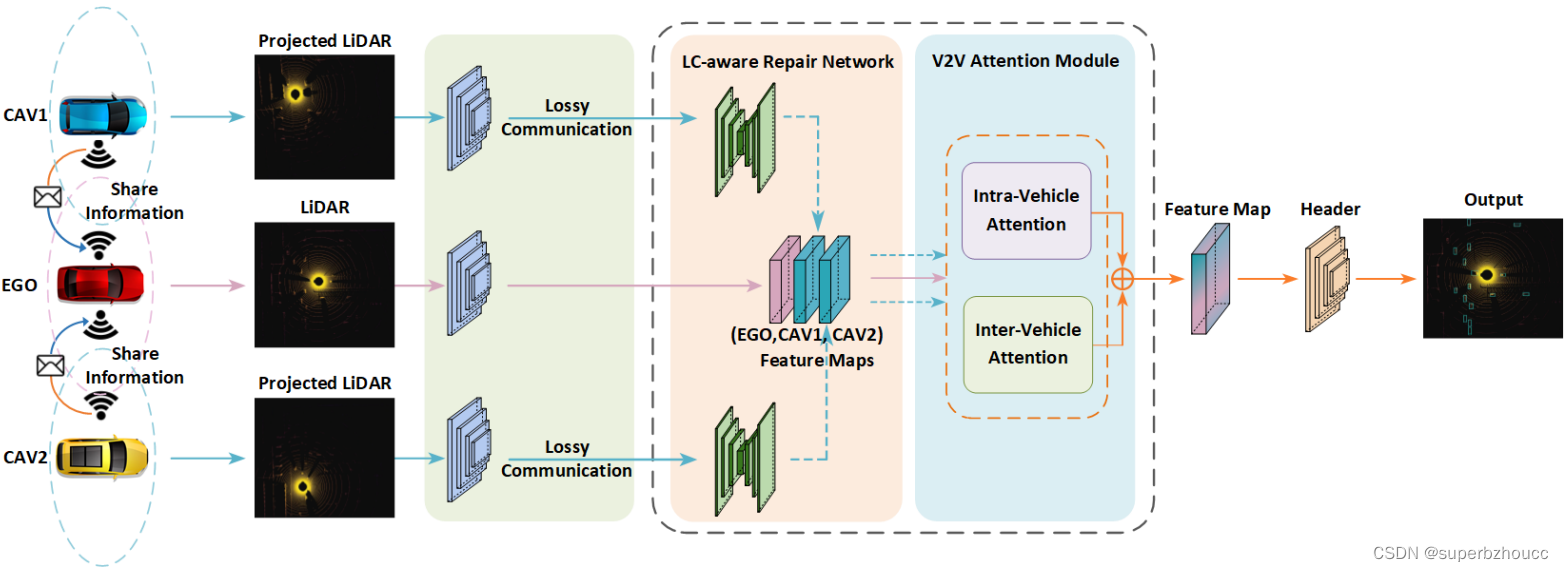
1)V2V元数据共享:在收到 Ego 车辆的相对pose后,所以其他车辆将自身车载传感器捕获的LiDAR点云投射到 Ego车辆的坐标系中;
2)LiDAR特征提取:每个CAV使用anchor-based PointPillar从点云中提取特征;
3)特征共享:每个CAV将提取到的特征图通过V2V通信传送给Ego车辆;
4)LC-aware修复网络和V2V注意模块:由于Lossy Communication,特征图的传输通常会受到不可避免的破坏。因此,Ego首先需要使用所提出的LC-Aware修复网络对从周围其他CAVs接收到的中间特征进行修复;然后采用所提出的V2V attention模块进行intra-vehicle以及inter-vehicle特征融合。
5)分类和回归头:最终融合的特征图输入给检测头进行边界框回归和分类。
1.1 LC-aware 修复网络
作者受图像去噪的启发,所提出的LC-aware修复网络通过生成一个 per-tensor filter kernel来align并recover输入的受损特征,最终产生一个完整的输出特征。
LC-aware修复网络的框架( an encoder-decoder architecture with skip connections)
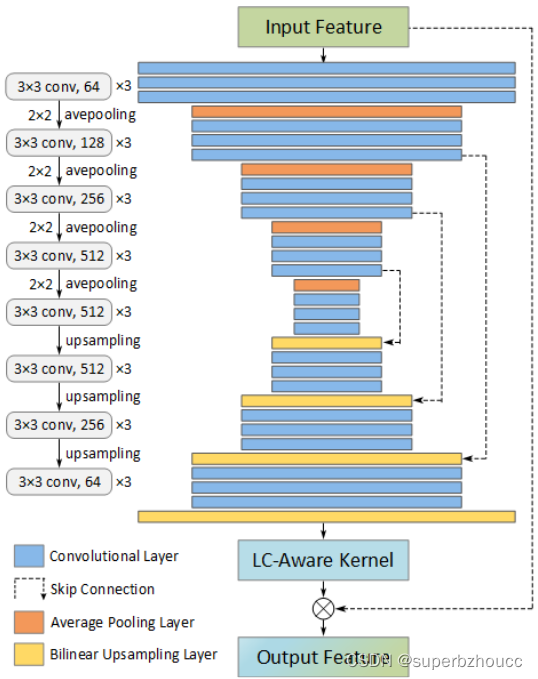
1)输入特征 S ∈ R c × h × w S∈\mathbb{R}^{c×h×w} S∈Rc×h×w经过一个encoder-decoder的CNN结构,为通道维度上的每个tensor生成合适的kernel(per-tensor kernel: K t ∈ R k × k K^t∈\mathbb{R}^{k×k} Kt∈Rk×k;tensor-wise kernel : K ∈ R ( k × k ) × h × w K∈\mathbb{R}^{(k×k)×h×w} K∈R(k×k)×h×w):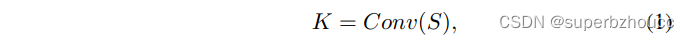
2)可以通过乘法将 K t K^t Kt应用于输入特征 S S S的每个tensor t t t 的 k × k k×k k×k邻域,即利用 K K K对 S S S进行the tensor-wise filtering,产生修复后的完整特征 S ^ ∈ R c × h × w \hat{S}∈\mathbb{R}^{c×h×w} S^∈Rc×h×w:
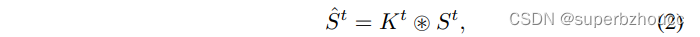
LC-aware修复loss函数为在遭受通信损失之前的原始特征 S ^ g \hat{S}^g S^g与修复后的特征 S ^ \hat{S} S^之间的 L1距离:
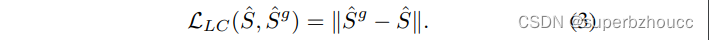
1.2 V2V Attention 模块(V2VAM)
Self-attention机制的关键思想是将一个位置的响应计算为所有位置的特征的加权和,其中特征之间的相关性取决于特征本身。
在特征修复后,为了利用来自附近多个CAV的中间特征来提高基于V2V通信的感知性能,设计了一种Intra-Vehicle和Inter-Vehicl注意力融合方法,以加强Ego和其他CAV之间的相关性学习。在提出的V2VAM中,采用criss-cross注意力模块以更有效地从full-feature dependencies中捕捉上下文信息。
V2V attention 模块结构
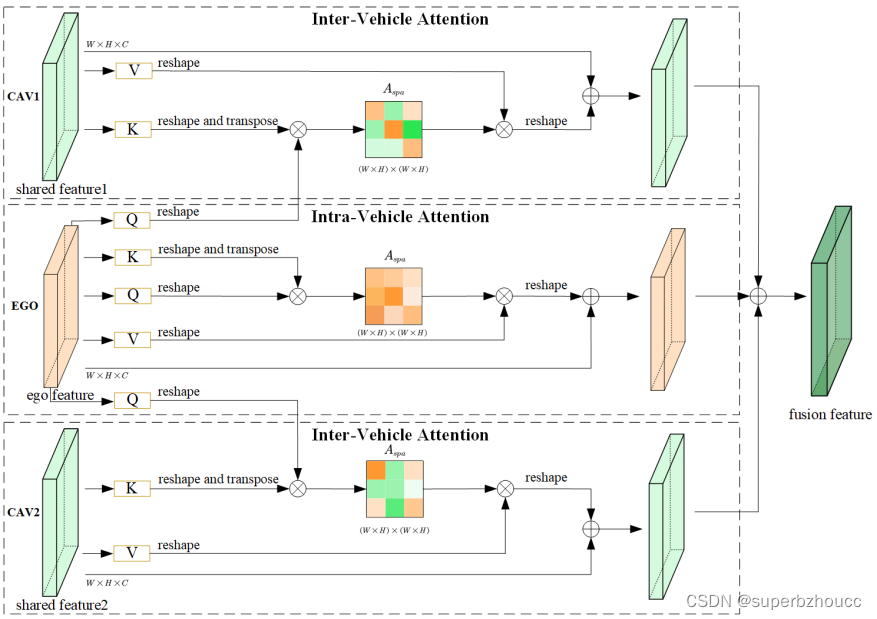
1.2.1 Intra-Vehicle Attention
Ego车辆自身捕获的特征图 H e ∈ R C × H × W H^e∈\mathbb{R}^{C×H×W} He∈RC×H×W没有经过有损通信传输,因此是完整数据。为了使Ego车辆的来自任何位置的特征都能被全局感知,在Intra-Vehicle注意力模块中,
- 特征图 H e H^e He经过三个1×1卷积层分别产生三个特征向量 { Q e , K e , V e } ∈ R C × H × W \{Q_e, K_e ,V_e\}∈\mathbb{R}^{C×H×W} { Qe,Ke,Ve}∈RC×H×W 。
- 基于缩放点积注意力(scaled dot-product attention),计算 Q e Q_e Qe和 K e K_e Ke的点积,并且利用缩放系数(特征向量的维度)和softmax函数来计算获得 V e V_e Ve的权重。Ego车辆的输出特征图为:

其中 d k e d^e_k dke是 K e K_e Ke的维度。
1.2.2 Uncertainty-Aware Inter-Vehicle Attention
其他车辆分享给Ego的特征图 H s ∈ R C × H × W H^s∈\mathbb{R}^{C×H×W} Hs∈RC×H×W经由LC-aware修复网络修复后,在某种程度上仍然存在噪声。为了进一步加强鲁棒性,提出了Uncertainty-Aware Inter-Vehicle注意力融合方法。
- 接收到的共享特征经过两个1×1的卷积层分别产生两个特征向量 { K s , V s } ∈ R C × H × W \{K_s ,V_s\}∈\mathbb{R}^{C×H×W} { Ks,Vs}∈RC×H×W ,而另一个特征向量 Q e Q_e Qe基于Ego捕获的特征图计算获得。
- 与Intra-Vehicle Attention一样,Uncertainty-Aware的inter-vehicle attention为:
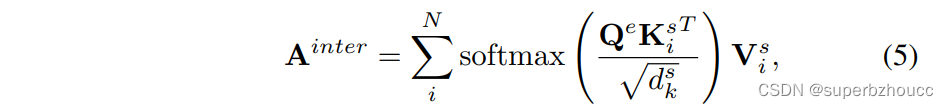
其中 d k d_k dk是 K i s K^s_i Kis的维度, N N N是相邻CAV的数量。 A i n t e r A^{inter} Ainter表示考虑到Ego车辆与其他车辆交互的输出特征图的总和。
V2VAM的最终融合特征输出为: A o u t = A i n t r a + A i n t e r A^{out}=A^{intra}+A^{inter} Aout=Aintra+Ainter。
对于3D目标检测,使用smooth L1 loss 进行边界框回归,使用focal loss 进行分类。 最终的损失函数为目标检测loss和LC-aware修复loss L L C \mathcal{L}_{LC} LLC的组合: L t o t a l = µ L d e t + λ L L C \mathcal{L}_{total} = µ\mathcal{L}_{det}+ λ\mathcal{L}_{LC} Ltotal=µLdet+λLLC,其中 μ μ μ和 λ λ λ是范围为 [ 0 , 1 ] [0, 1] [0,1]的平衡系数。
1.2.3 Efficient Implementation
由于,基于attention的算法在点云数据中计算复杂度较高。而criss-cross attention 模块聚合了水平和垂直方向的上下文信息,可以通过连续堆叠两个CC注意模块来收集所有像素的上下文信息,降低了复杂性。因此,采用两个连续的 criss-cross attention 模块来实现所提出的V2V attention。
2 实验
使用仿真数据集OPV2V来验证所提出的方法。
-
在两种情况下评估模型的目标检测性能:
1)理想通信,所有的数据传输都是在完美的通信下进行的;
2)有损通信,除了Ego车辆特征,所有来自其他CAV的中间特征都受到有损通信的影响。为了模拟有损通信,首先,根据随机概率p∈[0, 1]随机选择共享的中间特征;然后,使用由原始中间特征范围内的均匀分布产生噪声 来替换被选择的特征。 -
在训练阶段,采用两种方案来观察不同的训练数据对V2V 3D目标检测模型的影响:
1)仅使用基于理想通信的数据进行训练;
2)使用基于模拟有损通信的数据进行训练。
所有训练好的模型都在V2V CARLA Towns和Culver City测试集上,在理想通信和有损通信的情况下进行评估。
3 总结
提出了一种基于中间协作的V2V协同目标检测方法,
- LC-aware修复网络(LCRN),是一个带有跳过连接的编码器-解码器结构,旨在生成一个张量的内核,用于恢复从协作车辆收到的受损特征。缓解有损通信的副作用;
- V2V attention模块(V2VAM),融合修复后的特征,加强自我车辆和其他车辆之间的互动,包括自我车辆的车内注意力和不确定性感知的车辆间注意力。
通过车内注意力和不确定性意识的车际注意力,加强自我车辆和协作车辆之间的互动。
在OPV2V数据集上的实验表明,所提出的LC-aware特征融合方法对于有损V2V通信下的基于点云的3D目标检测是有效的。
可改进:采用在遭受通信损失之前的原始特征 S ^ g \hat{S}^g S^g作为ground truth来监督训练LC-aware修复网络,但是 S ^ g \hat{S}^g S^g是通过特征提取网络获得的可能具有很高的error的。或许可利用Knowledge Distillation方法进行训练,使用已经训练好的一个较复杂的模型来提取特征将其作为ground truth。