论文标题:Cooperative Perception for 3D Object Detection in Driving Scenarios Using Infrastructure Sensors
发表期刊/会议:IEEE Transactions on Intelligent Transportation Systems(2020)
开源代码:https://github.com/eduardohenriquearnold/coop-3dod-infra
数据集:https://wrap.warwick.ac.uk/159053/5/dataset.tar.xz (CARLA生成)
问题:遮挡、有限的视野和稀疏的传感器数据问题无法通过单车的多模态传感来有效地解决。协同感知使得车辆可以从不同的位置观察环境,增加感知范围,提高点云的密度,从而减少感知噪声的不利影响。在V2V协同感知中,移动车辆的定位误差会导致融合后的点云出现对齐错误,这可能导致假阳性和漏检。
1 系统模型和融合方案
在提出的系统模型中,利用路边设施传感器网络,传感器是固定位姿的;因此,各个传感器的空间对齐校准是准确。假设在没有通信延迟和数据丢失,且每个传感器的位姿(GPS定位和方向)都是准确的。
1.1 System Model
协同感知系统模型:
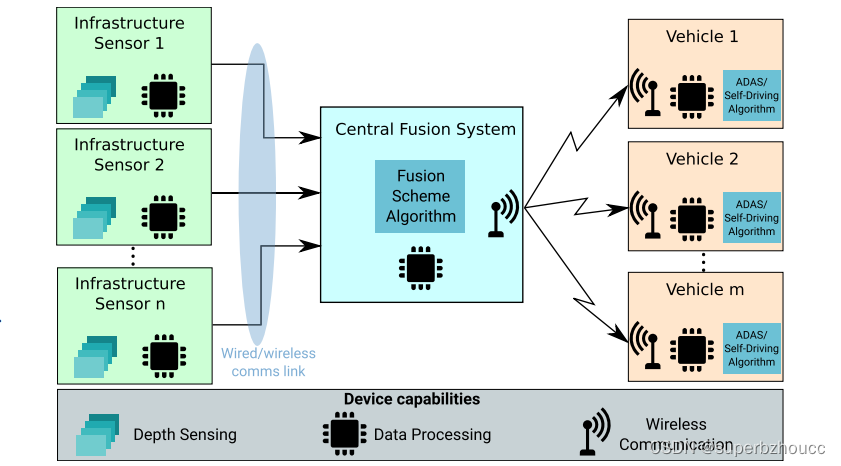
1)多个路边设施将传感器感知信息传输到中央融合系统;
2)中央融合系统将多个路边设施感知的信息进行融合,并产生目标检测结果,然后与附近所有车辆共享。
3)每个车辆根据自车传感器信息和由中央融合系统广播的信息来感知交通环境,并做出适当的决策。
中央融合系统负责融合各个路边设施传感器的数据和定期向附近的车辆广播协同感知信息,其作用只是协助自动驾驶车辆或司机做出适当的控制决策,以安全驾驶。
1.2 数据预处理
提出的目标检测模型采用点云数据,如LiDAR或深度照相机提供的数据。虽然,LiDAR可以产生点云作为标准输出,但由深度相机产生的深度图像可以被处理以产生点云。
1)每个LiDAR传感器都基于自身的位姿信息通过旋转平移,将点云从自身传感器坐标系映射到全局坐标系中。
2)将在给定的全局检测区域之外的点和高于4米的点删除,因为这些点不携带相关有用的信息。
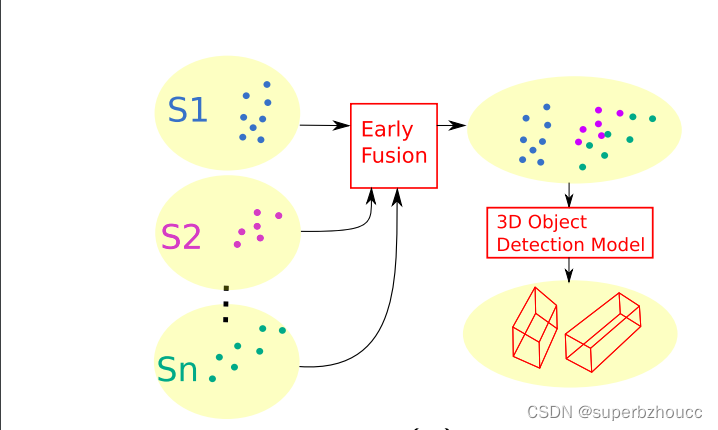
1.3 早期融合方案
1)每个传感器的点云转换到全球坐标系下后,被传送到中央融合系统,将这些点云帧聚合拼成一个全局的点云,然后传给3D目标检测模型。
2)中央融合系统中的目标检测模型输出检测物体的3D边界框,然后将其广播给附近的车辆。
1.4 后期融合方案
融合每个传感器节点在本地获得的3D目标检测模型的输出(三维边界框)。
1)在每个路边设施上对其传感器点云进行预处理,使用自身的目标检测模型输出检测物体的3D边界框和边界框的置信度分数(表示边界框内存在物体的置信度)。
2)每个路边设施将自身的目标检测结果传输到中央融合系统进行融合。采用非最大抑制(NMS)算法来消除重叠的边界框,通过交叉联合(IOU)指标来衡量边界框的重叠情况,如果多个边界框之间的重合度超过了指定的阈值,那么就删除置信度低的边界框。
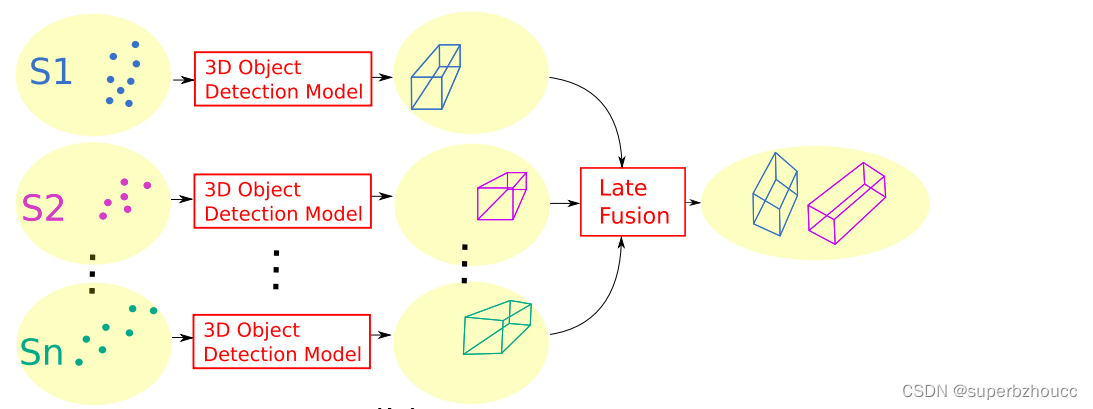
3)检测结果融合和后处理完成之后,最终的检测结果就会广播给附近的所有车辆,以协助车辆做出更安全的控制决策。
1.5 早期与晚期混合融合方案
由于早期融合将原始传感器数据汇总,可以增加检测到物体的可能性,但增加了通信成本。混合融合方案将早期融合和晚期融合结合起来,通过减少原始数据量的传输来降低通信成本。
早期与晚期混合融合:靠近LiDAR传感器的物体的点云密度较高,更有可能使用单个传感器数据来检测到。因此,在靠近传感器的区域分享检测结果信息(晚期融合),在能见度低的地方分享原始数据信息(早期融合)。传感器附近的点不需要被传输到中央融合系统,这可以减少通信带宽。
每个传感器的附近区域定义为水平面投影半径为R的圆形区域,半径R调节早期融合和晚期融合之间的权衡,随着R的减小,被分享给中央融合系统的原始数据越多。
1.在每个传感器节点中采用后期融合方案,并将检测到的物体边界框共享给中央融合系统。
2. 每个传感器节点选取其点云中附近区域之外的点与中央融合系统共享。
3. 中央融合系统对接收到的点云使用早期融合,并将检测到的边界框与来自每个路边设施传感器的后期融合结果融合。
1.6 3D目标检测模型
所有融合方案采用的目标检测模型都是Voxelnet。该模型由三个主要功能块组成:一个特征学习网络、多个卷积中间层和一个区域建议网络(RPN)。
2 数据集
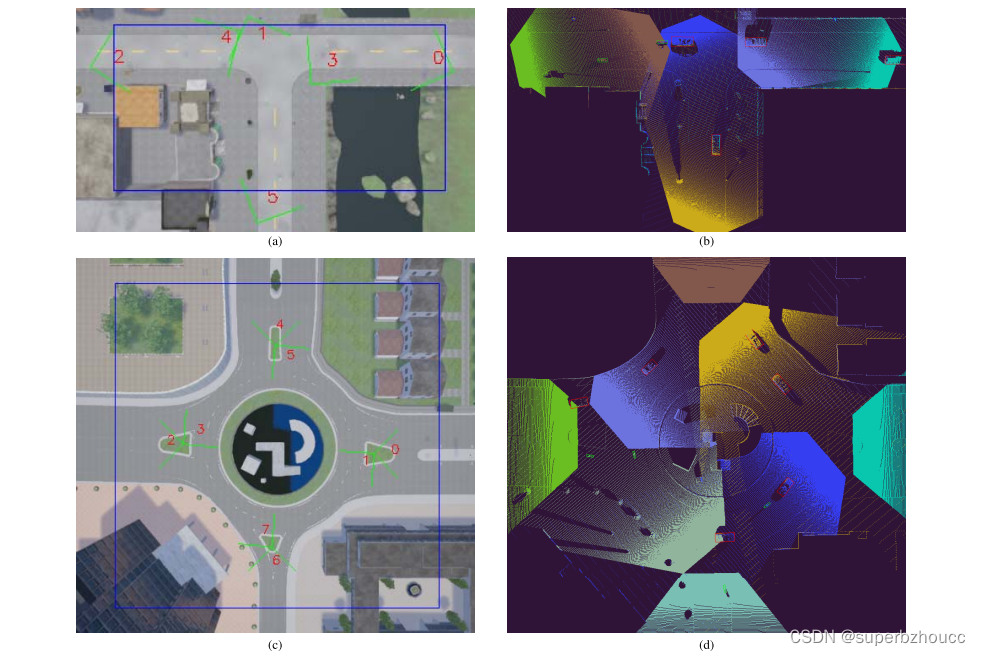
数据集采用CARLA仿真工具在T型路口和环岛场景中使用路边摄像头生成的,提供RGB和深度图像,分辨率为400 x 300像素,水平视场为90度。
1)T型路口使用了六个安装在5.2米高的柱子上的路边设施摄像机。其中三个摄像头指向来路,其余三个指向路口的相反方向。
2)环岛使用8个摄像头,安装在8米高的柱子上,放置在路口,其中4个面向环岛的来车道,另外4个面向环岛的外侧。
检测区域定义为80×40米的矩形(T型路口)和96米的正方形(以环岛为中心)。
四个子数据集:两个用于T型路口,分别包含4000个训练帧和1000个测试帧,两个用于环岛,具有相同数量的训练和测试帧。一个帧被定义为来自所有摄像机的深度和RGB图像的集合,每帧还包含一个检测物体列表,其包含了场景中所有物体的真实位置、方向、大小和类别。检测物体类别包含车辆、骑车人/摩托车人或行人。
在本文所提出的协同目标检测方法中只使用深度图像,每个像素表示从相机到物体表面点的矢量的投影(到相机的Z轴)的距离。每张深度图像都被用来重建一个点云,基于针孔相机模型将每个像素转换为相机坐标系中的一个三维点:
其中,(x,y,z)是深度图像中像素坐标(u,v)对应的三维点的坐标,Cu,Cv,f是相机的焦距中心和长度,d是坐标为(u,v)的像素的各自深度值。
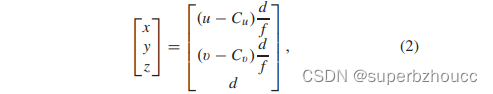
3 总结
- 相比于V2V共享车载信息并在本地融合数据,所提出的协同感知系统采用了一个中央系统,融合来自多个路边设施传感器的感知信息,可以通过共享资源来减少传感器本地处理成本。
- 通过选取远处的点云原始数据(稀疏)进行传输来减少传输数据量从而减少早期融合方式的通信带宽,附近区域采用后期融合方式,这种混合融合方案可以实现感知精度与通信成本之间的平衡。
局限:
1)没有考虑network delay and communication losses。
2)融合方案只涉及各个路边设施传感器数据的融合,基于路边设施传感器获得的结果具体是怎么协助车辆,自车传感器信息和由中央融合系统广播的信息是怎么融合的?
一些重叠的检测边界框有可能被结合起来,形成一个新的具有较高置信度的边界框,需要一个新的模型来实现边界框的融合过程。