前言
本文提出了一种元学习算法,它与模型无关并且通用性很强,可以直接应用到各种由梯度下降训练的模型上,并且适用于很多学习问题,包括分类,回归和强化学习。本文提出的算法的关键思想是训练模型的初始化参数,这样当模型在处理来自一个新任务的少量数据时,通过一次或几次梯度更新后,模型就能在新任务中表现出较好的性能。本文的元学习算法有以下特点:
- 不同于以往的元学习方法需要学习更新函数或更新规则,本文的方法既不增加学习的参数的数量,也不会对模型结构进行约束(比如使用RNN网络或Siamese Network),它可以很容易地与全连接网络、卷积网络或循环网络结合起来;
- 本文的元学习算法还可以使用各种损失函数,包括可微的有监督损失和不可微的强化学习目标。
关于"训练模型的参数,使得经过一次或几次梯度更新,模型就可以在一个新任务上获得较好的结果"这个过程,本文从两个角度对其进行解释:
- 从特征学习的角度,这个过程可以看作是构建一个广泛适用于许多任务的内部表示。如果对许多任务来说这种内部表示都是合适的,那么简单地对参数进行微调就能获得好的结果。实际上,本文的算法对模型进行了优化,使其易于快速微调;
- 从动态系统的角度,这个过程可以看作是使新任务的损失函数对参数的敏感性最大化:当敏感性较高时,参数的一个很小的局部改变就可能导致损失的大幅改变。
元学习问题的定义
few-shot元学习的目标是训练一个模型,使其仅使用较少的数据和迭代过程就能快速适应一个新任务。为了实现这个目标,模型在元学习阶段在一系列任务上进行训练,而实际上,元学习问题确实是将整个任务视为训练样本。
首先考虑一个模型 ,给定一个输入 ,能够产生一个输出 ,在元学习过程中,模型被训练为能够适应于大量或无限数量的任务。下面引入关于学习任务的一个通用概念:通常来说,每个任务 ,其中 是损失函数, 是原始输入的分布, 是过渡分布, 是episode的长度。在有监督的学习问题中, 。通过在时刻 选择一个输出 ,该模型能够生成长度为 的样本。关于损失 ,它提供了特定于任务的反馈,反馈的形式可能是误分类损失或马尔可夫决策过程中的成本函数。
在本文的元学习场景中,考虑一个任务分布 ,并且希望模型能够适应这种分布。考虑 -shot学习任务,在元训练(meta-training)过程中,从 中抽取新任务 ,从 中抽取 个样本,用这 个样本和从 处得到的反馈信息训练模型, 是 的损失,然后从 中选择新样本进行测试,当然新样本还是从 剩下的样本中抽取的。通过考虑来自 的新样本的测试误差随参数的变化情况,对模型 做出改进。实际上,将任务 的测试误差作为元学习过程中的训练误差。
在元训练结束后,进行元测试(meta-testing),从 中抽取新的任务,通过学习 个样本后的模型的性能来衡量元性能(meta-performance)。元学习过程包括元训练和元测试,用于元测试的任务是在元训练期间进行的。
与模型无关的元学习算法
本文提出了一种通过元学习来学习任何标准模型的参数,使得模型能够快速适应新任务。之所以提出这种方法,是因为作者发现一些内部表示比其它表示更具有迁移性。比如,一个神经网络可能会学习到广泛适用于 中所有任务的内部特征,而不仅仅只适用于一个单个任务。
那么怎么才能出现这种通用表示呢? 本文提出了这样一种方法:由于模型在处理新任务时会使用基于梯度的学习规则进行微调,因此目标就是要学习这样一个模型,在没有过拟合的情况下,使用基于梯度的学习规则能够快速处理从
中抽取的新任务。实际上,就是要找到对任务的改变敏感的模型参数,当该损失的梯度方向改变时,参数的微小变化将对从
中抽取的任何任务的损失函数产生巨大的变化,如下图所示:
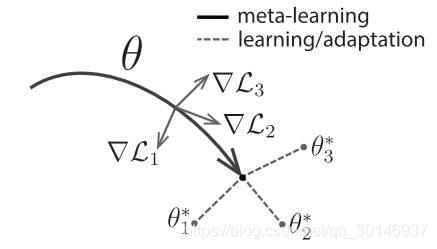
考虑一个由参数化函数
表示的模型,其中
是参数,当学习新任务
时,模型的参数
变为
。更新后的参数向量
是在任务
中经过一步或多步梯度下降更新得到的。一步梯度更新表示为:
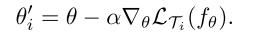
其中步长
可以是一个超参数。
通过优化从
中采样的任务
相对于
的性能,来训练模型的参数,也就是元优化(meta-optimization)。元目标(meta-objective)如下:

注意元优化是在模型参数
上执行的,而元目标是使用更新的模型参数
计算的。实际上,本文提出的方法的目标就是优化模型参数,使得模型在一个新任务上经过一步或多步梯度更新后就可以达到较好的性能。
任务间的元优化是通过SGD实现的,模型参数
更新如下:
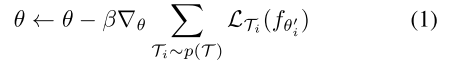
其中
是元步长(meta step size)
MAML的元梯度(meta-gradient)更新涉及到从一个梯度到另一个梯度。在计算上,这需要通过 进行一个额外的向后传播过程,来计算海森向量积。本文的实验也比较了不采用向后传播而使用一阶近似的方法。
完整的算法如下图:

MAML在分类和回归上的应用
few-shot分类任务,就是已经在其它带标记的样本上训练了一个模型,然后给出一个新类,该类只有少量标记样本,该模型需要对其它图像进行分类,判断其它图像是否属于该新类;few-shot回归任务,就是通过对具有相似统计特性的函数进行训练后,对于另一个连续值函数,要能够仅从该函数的几个采样点预测该函数的输出。
回归任务使用的是均方差损失:
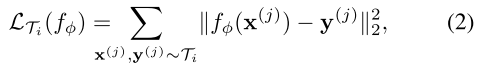
其中
,
是从
中采样的样本对儿,
是输入,
是
对应的目标值。
离散分类任务使用的是交叉熵损失:
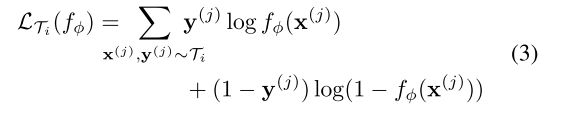
给定一个任务分布
,以上这些损失函数可以直接应用到元学习中,算法如下:

