论文地址:https://arxiv.org/pdf/2007.04269.pdf
发布年份:2020
我们提出了一种模型无关的后处理方案,以提高由任何现有的分割模型生成的分割结果的边界质量。基于经验观察的标签预测更可靠,我们建议用内部像素的预测来取代原本不可靠的边界像素预测。我们的方法只通过两个步骤来处理输入的图像:(i)定位边界像素,(ii)为每个边界像素识别相应的内部像素。我们通过学习一个从边界像素到一个内部像素的方向来建立对应关系。我们的方法不需要分割模型的先验信息,并达到了几乎实时的速度。我们通过经验验证,我们的SegFix持续减少了由Cityscapes、ADE20K和GTA5上的各种最先进的模型生成的分割结果的边界误差。代码在 https://github.com/openseg-group/openseg.pytorch 中可见。
1 Introduction
语义分割的任务被定义为预测图像中每个像素的语义类别。基于开创性的全卷积网络[43],以往的研究取得了巨大的成功,在各种具有挑战性的语义分割基准[7,15,64]上提高了性能。现有的工作主要是通过(i)提高特征映射[12,13,51]的分辨率,(ii)构建更可靠的上下文信息[61,59,22,26,60]和(iii)利用边界信息[5,9,41,52]。在这些工作中,我们遵循第三个方向开展工作,着力于通过一种简单但有效的模型无关的边界细化机制,改进了位于细化边界内的像素的分割结果。
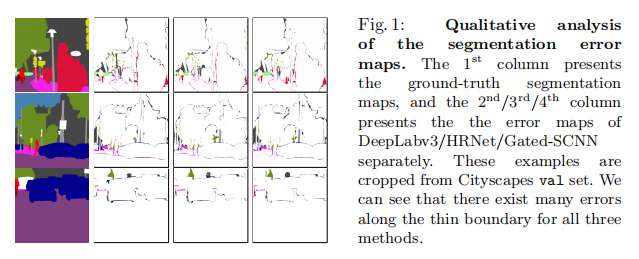
我们的工作主要是由于观察到大多数现有的最先进的分割模型不能很好地处理沿边界的误差预测。我们在图1中使用DeepLabv3[12]、Gatt-SCNN[52]和HRNet[51]来说明一些分割错误映射的例子。更具体地说,我们在图2中说明了错误像素数与到对象边界的距离的统计数据。我们可以观察到,对于所有三种方法,误差像素的数量随着距离边界距离的增大而显著减少。换句话说,对内部像素的预测更可靠。

我们提出了一种新的模型无关的后处理机制,通过替换边界像素的标签与相应的内部像素的标签来减少分割结果。我们通过两步处理输入图像(不探索分割结果)来估计像素对应。第一步的目标是沿着对象的边界来定位像素。我们遵循轮廓检测方法[4,2,20],并简单地使用卷积网络来预测指示边界像素的二进制mask。在第二步中,我们学习一个从边界像素到一个内部像素的方向,并通过从边界像素沿着该方向移动一定的距离来识别相应的内部像素。特别是,我们的SegFix可以在高分辨率的输入下达到几乎实时的速度。
我们的SegFix是一种通用方案,它在没有任何先验信息的情况下,跨多个基准测试持续提高各种分割模型的性能。我们评估了SegFix在多个语义分割基准上的有效性,包括Cityscapes、ADE20K和GTA5。我们还将SegFix扩展到Cityscapes上的实例分割任务。根据Cityscapes排行榜,“HRNet+OCR+SegFix”和“PolyTransform+SegFix”分别达到了84.5%和41.2%,根据ECCV 2020提交截止日期,它们分别在语义和实例分割轨道上排名第一和第二。
2 Related Work
Distance/Direction Map for Segmentation: 最近的一些工作[3,24,53]执行了距离转换来计算距离映射的实例分割任务。例如,[3,24]提出了训练模型来预测每个裁剪实例中的截断距离图。另一项工作[16,6,10,48]提出在多任务机制中使用距离映射或方向映射来规范语义或实例分割预测。与上述工作相比,关键的区别在于我们的方法不进行任何分割预测,而是只从图像中预测方向图,然后对现有方法的分割结果进行细化。
Level Set for Segmentation: 在深度学习时代之前,之前的许多工作[47,8,29]都使用了水平集方法来解决语义分割问题。最流行的水平集公式是有符号的距离函数,所有的零值都对应于预测的边界位置。最近的工作[1,14,53,31]将传统的水平集方案扩展到深度网络,用于正则化预测分割映射的边界。我们不是直接用水平集函数来表示边界,而是用边界图和方向图隐式地编码边界像素的相对距离信息。
DenseCRF for Segmentation: 之前的工作[11,55,63,38]使用DenseCRF[34]改进了他们的分割结果。我们的方法也是一种通用的后处理方案,同时使用起来更简单、更高效。我们的经验表明,我们的方法不仅优于性能,而且是与DenseCRF的补充。
Refinement for Segmentation: 广泛的研究表明,[21,23,27,35,36]提出了各种机制来细化分割图从粗糙到精细。与大多数现有的依赖于分割模型的细化方法不同,据我们所知,我们的方法是第一个与模型无关的分割细化机制,可以用于在没有任何先验信息的情况下重新细化任何方法的分割结果。
Boundary for Segmentation: 之前的一些工作[1,56,42,57]主要集中于定位语义边界。[5,52,17,41,40,30,18,19]也提出利用边界信息来改进分割效果。例如,BNF[5]引入了一个全局能量模型来考虑基于边界预测的成对像素亲和度。Gated-SCNN[52]利用双分支机制和规则器了分割预测和边界预测之间的对偶性。
这些方法[5,17,52,30]高度依赖于分割模型,需要仔细的再训练或微调。与它们不同的是,SegFix既不执行分割预测,也不执行特征传播,而是我们直接使用偏移映射来细化分割映射。换句话说,我们只需要训练一个统一的SegFix模型,而不需要进一步微调不同的分割模型(跨多个不同的数据集)。我们还通过经验验证了我们的方法与上述方法的互补性,例如,Gated-SCNN[52]和边界感知特征传播(Boundary-Aware Feature Propagation)[17]。
Guided Up-sampling Network: 最近的工作[44,45]执行了一个分割引导偏移方案来解决由双线性上采样引起的边界误差。主要的区别是,它们不对偏移图应用任何显式的监督,需要对不同的模型进行再训练,而我们对偏移图应用显式的语义感知监督,我们的偏移图可以直接应用于各种方法,而不需要任何再训练。我们也通过经验验证了我们的方法的优点。
Semantically Thinned Edge Alignment Learning (STEAL): 之前的研究STEAL[1]是最相似的工作,因为它也预测了边界图和方向图(同时)来细化边界分割结果。为了证明STEAL和我们的SegFix之间的主要区别,我们总结了以下几个关键点:(i)STEAL预测K个独立的边界图(与K个类别相关),而SegFix只预测一个单一的边界图,而没有区分不同的类别。(ii)STEAL先预测边界图,然后在边界图上应用一个固定的卷积来估计方向图,而SegFix使用两个平行的分支独立预测。(iii)STEAL在方向分支上使用均方损失,而SegFix使用交叉熵损失(在离散方向上)。此外,我们在消融研究中通过经验比较了STEAL和我们的SegFix。
3 Approach
3.1 Framework
SegFix的整体流程如图3所示。我们首先训练一个模型来挑选边界像素(带有边界映射),并仅从图像中估计它们相应的内部像素(具有从方向映射中得到的偏移量)。我们在训练过程中不直接执行分割。我们应用该模型从图像中生成偏移图,并使用偏移图得到相应的像素,这些像素大多应该是更自信的内部像素,从而细化任何分割模型的分割结果。我们主要描述了用于语义分割的SegFix方案,并在附录中说明了实例分割的细节。
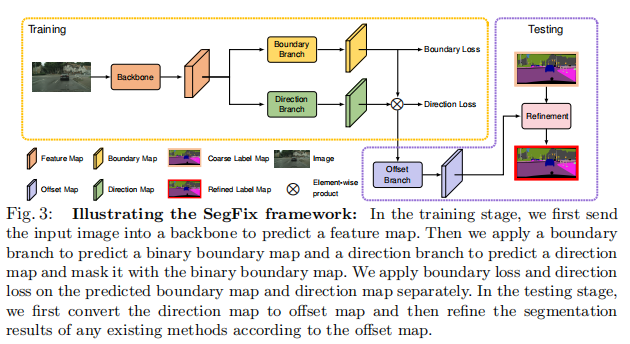
Training stage. 给定一个输入图像的形状H×W×3,我们首先使用骨干网络提取特征地图X,然后传递X给平行边界分支1预测binary map B(1为边界像素和0为内部像素),和方向分支2预测方向映射D与每个元素存储的方向指向边界像素内部像素。然后,方向映射D被二进制映射B屏蔽,以产生偏移分支的输入。
在模型训练中,我们分别使用二元交叉熵损失作为B上的边界损失,而使用类别交叉熵损失作为D上的方向损失。测试阶段。基于预测的边界图B和方向图D,我们应用偏移分支生成偏移图∆Q。任何语义分割模型的粗标签映射L输出将被细化为:
L ~ p i = L p i + Δ q i (1) \tilde{\mathbf{L}}_{\mathbf{p}_{i}}=\mathbf{L}_{\mathrm{p}_{i}+\Delta \mathbf{q}_{i}} \tag{1} L~pi=Lpi+Δqi(1)
其中 L ~ \tilde{\mathbf{L}} L~是重定向图, p i p_i pi表示边界像素i的坐标, Δ q i \Delta \mathbf{q}_{i} Δqi 是生成的指向一个内部像素的偏移向量,这确实是$\Delta \mathbf{Q} $ 的一个元素。$ \mathbf{p}{i}+\Delta \mathbf{q}{i}$是被识别的内部像素的位置。
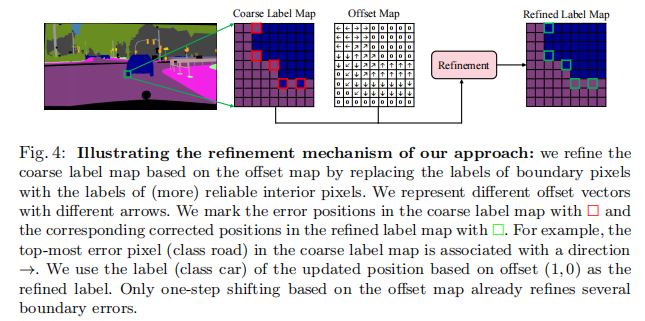
考虑到当边界很厚时可能存在一些“假的”内部像素【我们使用“假的”内部像素来表示在边界较厚时仍然位于边界上的像素(在偏移量之后)。值得注意的是,如果一个像素在预测的边界图B中的值为0/1,则我们将其识别为内部像素/边界像素。】,我们提出了以下两种不同的方案:(i)通过一个因子重新缩放所有的偏移量,如示例2。(ii)迭代应用(“假”的内部像素的偏移),直到找到一个内部像素。为了简单起见,我们在默认情况下选择(i),因为它们的性能非常接近。
在测试阶段,我们只需要在测试集上生成一次偏移图,并且可以应用相同的偏移图来细化任何现有分割模型的分割结果,而不需要任何先验信息。一般来说,我们的方法是适用于任何现有的分割模型。
3.2 Network Architecture
Backbone. 我们采用最近提出的高分辨率网络(HRNet)[51]作为骨干,因为它在维护高分辨率特征图方面的优势,并且我们需要应用全分辨率边界图和方向图来重新细化全分辨率粗标签图。为了进一步提高输出特征图的分辨率,我们通过添加一个额外的分支来保持更高的输出分辨率来修改原始的HRNet,即2×,称为HRNet-2×。我们直接在分辨率最高的输出特征图上执行边界分支和方向分支。分辨率为 H s × W s × D \frac{H}{s}×\frac{W}{s}×D sH×sW×D,其中s=4用于HRNet,s=2用于HRNet-2×。我们通过经验验证,我们的方法持续改进了第4.2节中主干选择的所有变化的粗分割结果,例如,HRNet-W18和HRNet-W32。
Boundary branch/loss. 我们将边界分支实现为Conv1×1→BN→ReLU,有256个输出通道。然后,我们应用线性分类器(Conv1×1)和上采样进行预测,生成大小为H×W×1的最终边界图B。B中的每个元素都记录了该像素属于该边界的概率。我们使用二元交叉熵损失作为边界损失。
Direction branch/loss. 与之前的方法[1,3]对对连续方向[0◦,360◦]进行回归不同,我们的方法通过将整个方向范围均匀划分为m分区(或类别)作为我们的GT(默认为m=8)来直接预测离散方向。事实上,我们根据经验发现,我们的离散分类方案优于回归方案,例如,在角域[3]的均方损失,通过最终的分割性能改进来衡量。我们将在第3.3节中详细说明离散方向图的更多细节。
我们将方向分支实现为Conv1×1→BN→ReLU,有256个输出通道。我们进一步应用线性分类器(Conv1×1),并对分类器预测进行上采样,生成大小为H×W×m的最终方向图D。我们通过乘以(二值化的)边界映射B来掩蔽方向映射D,以确保我们只通过边界分支在被识别为边界的像素上应用方向损失。我们使用标准的类别交叉熵损失来监督这个分支的离散方向。
Offset branch. 偏移分支用于将预测的方向图D转换为大小为H×W×2的偏移图∆Q。我们在图5(a).中说明了映射机制。例如,当m=4时,“垂直”方向类别(对应于范围内的值[0◦,90◦])将被映射到偏移量(1,1)。最后,我们通过使用网格样本方案[28]移动粗标签映射来生成细化的标签映射。这个过程如图4所示。
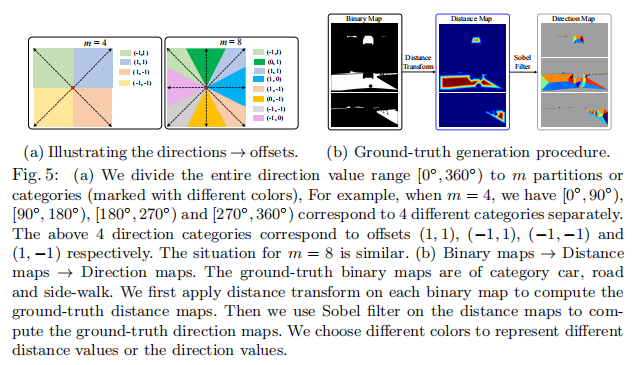
3.3 Ground-truth generation and analysis
可能存在许多不同的机制来生成边界图和方向图的GT(ground-truth)。在本研究中,我们主要利用传统的距离变换[32]来为语义分割任务和实例分割任务生成GT。我们从GT分割标签开始生成GT距离图,然后是边界图和方向图。图5(b)说明了整个过程。
Distance map. 对于每个像素,我们的距离映射记录其与属于其他对象类别的像素的最小(欧氏)距离。我们将说明如何计算距离图。
首先,我们将地面真值标签分解为K个与不同语义类别相关联的二进制映射,如汽车、道路、人行道等。第k个二进制映射记录属于第k个语义类别的像素为1,否则为0。其次,我们对每个二进制映射分别执行距离变换[32]7来计算距离映射。第k个距离映射的元素编码从属于第k个类别的像素到属于其他类别的最近的像素的距离。这个距离可以被视为到物体边界的距离。我们通过聚合所有的K个距离图来计算一个融合的距离图。
请注意,我们的距离图中的值(总是正的)不同于传统的有符号距离,后者分别代表具有正/负距离的内部/外部像素。
Boundary map. 由于融合的距离图表示到对象边界的距离,我们可以通过将所有距离值小于阈值γ的像素设置为边界8来构造GT边界图。我们根据经验选择了较小的γ值,例如,γ=5,因为我们主要专注于薄边界的细化。
Direction map. 我们对K个距离映射分别执行Sobel滤波器(核大小为9×9),分别计算相应的K个方向映射。基于Sobel滤波器的方向在范围内[0◦,360◦],每个方向都指向距离对象边界最远的内部像素(在邻域内)。我们将整个方向范围划分为m个类别(或分区),然后将每个像素的方向分配给相应的类别。我们在图5(a)中说明了两种分区,默认情况下选择m=8分区。我们应用均匀分配的方向图作为训练的基本真相。此外,我们还在图5(b).中可视化了一些方向图示例子。
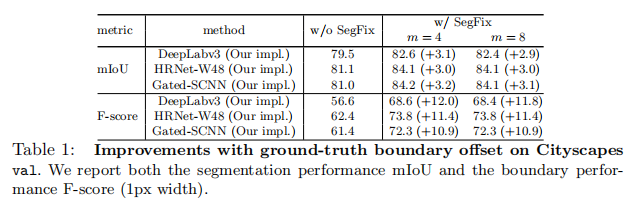
Empirical Analysis. 我们将生成的GT应用于三种最先进的方法的分割结果,包括DeepLabv3[12],HRNet[51]和Gatd-SCNN[52]来研究我们的方法的潜力。具体来说,我们首先投影GT方向图来得到偏移图,然后根据我们生成的GT偏移图在Cityscapes val上细化分割结果。表1总结了相关结果。我们可以看到,我们的方法显著提高了整体的mIoU和边界的f-score。例如,我们的方法(m=8)将Gated-SCNN的mIoU提高了3.1%。我们可以通过自适应地重新缩放不同像素的偏移量来获得更高的性能,而这并不是本工作的重点。
Discussion. 保证我们的方法的有效性的关键条件是,内部像素的分割预测是更可靠的经验。给定准确的边界图和方向图,我们总是可以提高分割的分割性能。换句话说,我们的方法的分割性能上限也取决于内部像素的预测精度。
4 Experiments: Semantic Segmentation
4.1 Datasets & Implementation Details
Cityscapes 是一个真实世界的数据集[15],由2,975/500/1,525张图像组成,分辨率为2048×1024,分别用于训练/验证/测试。该数据集包含19/8个语义类别,用于语义/实例分割任务。
ADE20K 是一个非常具有挑战性的基准测试[64],它分别包含了大约20,000/2,000张图像,用于训练/验证。该数据集包含150个细粒度的语义类别。
GTA5是一个合成数据集[49],由12,402/6,347/6,155张图像组成,分辨率为1914×1052,分别用于训练/验证/测试。该数据集包含19个与Cityscapes兼容的语义类别。
Implementation details. 我们在Cityscapes和GTA5基准测试上执行相同的训练和测试设置,如下所示。我们将初始学习率设置为0.04,权重衰减设置为0.0005,crop大小设置为512×512,批处理大小设置为16,并进行80K迭代训练。对于ADE 20K基准测试,我们将初始学习设置为0.02,所有其他设置都与Cityscapes上保持相同。我们使用“poly”学习率策略,设置power=0.9。对于数据增强,我们应用随机水平翻转、随机裁剪和在[−10,10]的范围内进行随机亮度抖动。此外,我们都在多个gpu上应用syncBN[50]来稳定训练。我们简单地将边界损失和方向损失的损失权重设为1.0。
值得注意的是,我们的方法不需要额外的训练或微调任何语义分割模型。我们只需要预先预测所有测试图像的边界掩模和方向图,并对任何现有方法的分割结果进行相应的细化。
Evaluation metrics. 我们使用两种不同的指标,包括:mask f-score和top-1方向精度来评估我们的方法在训练阶段的表现。对预测的二值边界图进行掩码F-score处理,对预测的方向图进行方向精度处理。特别是,我们只测量由边界分支识别为边界的区域内的方向精度。
为了验证我们的语义分割方法的有效性,我们遵循最近的Gated-SCNN[52],并执行了两个定量措施,包括:类级mIoU来测量区域的整体分割性能;边界f分数来测量距离较小松弛的预测掩模的边界质量。在我们的实验中,我们分别使用阈值0.0003、0.0006和0.0009对应1、2和3像素。我们主要报告了大多数消融实验的0.0003阈值为0.0003的性能。
4.2 Ablation Experiments
我们进行了一组消融来分析SegFix中各种因素的影响。如果没有说明,我们报告了对分割基线DeepLabv3(mIoU/F-score为79.5%/56.6%)的改进。
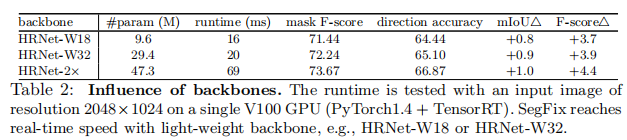
Backbone 我们研究了基于三种不同且复杂性不断增加的主干的SegFix的性能,即HRNet-W18、HRNet-W32和HRNet-2×。我们对所有三个骨干应用相同的训练/测试设置。根据表2中的比较,我们的SegFix在不同的骨干选择下始终提高了分割性能和边界质量。如果没有指定,我们在接下来的实验中选择HRNet-2×表现最好。此外,我们还在表2中报告了它们的运行时间。
Boundary branch. 我们验证了SegFix对边界分支内超参数γ的选择具有鲁棒性,并给出了一些定性结果。
-
boundary width: 表3显示了基于不同宽度的边界的性能改进。我们选择不同的γ值来控制边界宽度,其中γ值越小,边界就越薄。我们还报告了使用γ=∞的性能,这意味着所有的像素都被识别为边界。我们发现他们的改进很接近,所以我们默认选择了γ=5。

-
qualitative results: 图6显示了我们的边界分支的定性结果。我们发现预测的边界是高质量的。此外,我们还计算了从现有方法的分割图中计算出的边界之间的f-score,如gated-SCNN和HRNet从我们的边界分支中预测出的边界。f-score约为70%,这(在某种程度上)意味着它们的边界映射可以很好地对齐,并确保更准确的方向预测可以带来更大的性能收益。

Direction branch. 我们分析了方向数m的影响,然后给出了一些我们的预测方向的定性结果。
- direction number: 我们选择不同的方向编号来执行不同的方向分区,并控制用于细化粗标签映射的生成的偏移映射。我们用m=4、m=8和m=16进行了实验。根据表3中右边3列的报告结果,我们发现不同的方向数都会导致显著的改进,如果没有指定,我们选择m=8,因为我们的SegFix对m的值不那么敏感。
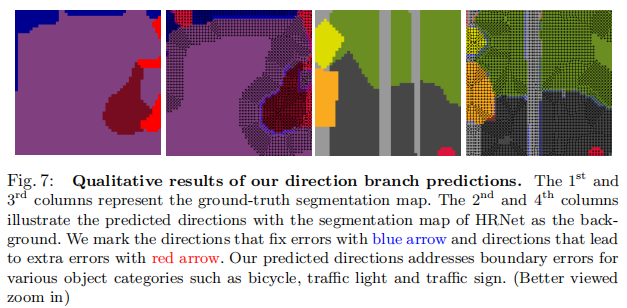
- qualitative results: 在图7中,我们展示了一些例子来说明我们预测的边界方向改善了误差。总的来说,改进后的像素(用蓝色箭头标记)主要分布在沿非常薄的边界上。
Comparison with GUM. 我们将SegFix与之前基于DeepLabv3为基线的、依赖于模型的引导上采样机制[44,45]进行了比较。我们在表4中报告了相关的结果。可以看出,我们的方法显著优于通过mIoU和f-score测量的GUM。我们通过将GUM与我们的方法相结合,从而获得了更高的性能,与基线相比,它在f-score上提高了5.0%。

Comparison with DenseCRF. 我们将我们的方法与基于DeepLabv3作为基线验证的DenseCRF[34]进行了比较。我们对DenseCRF的超参数进行了微调,并根据[11]进行了经验设置。从表5可以看出,我们的方法不仅优于DenseCRF,而且与DenseCRF是互补的。DenseCRF的mIoU改进有限的原因可能是,这可能是它给内部像素带来了更多的额外错误。

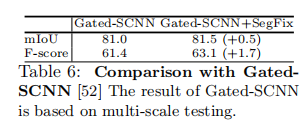
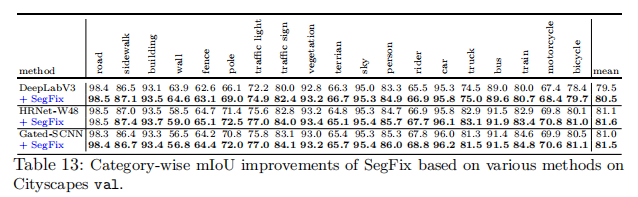
Application to Gated-SCNN. 考虑到Gate-SCNN[52]引入了多个组件来提高性能,很难在很大程度上将我们的方法与Gate-SCNN进行比较。为了在一定程度上验证我们的方法的有效性,我们首先将Cityscapes验证集上的开源Gated-SCNN(多尺度测试)分割结果作为粗糙的分割图,然后应用SegFix偏移图来细化结果。我们报告了表6中的结果,并且SegFix将边界F分数提高了1.7%,这表明SegFix与强基线是互补的,而强基线也侧重于提高分割边界质量。此外,我们还在表8中报告了由mIoU和边界f-score测量的详细的类别改进。
Comparison with STEAL. 由于STEAL[1]的训练代码不是开源的,我们只能简单应用他们发布的预训练模型来预测K个语义边界映射,并将其转换为二值边界映射。我们通过经验发现,我们的SegFix的边界质量(35.54%)与精心设计的STEAL边界质量(35.86%)相当,这表明我们的方法几乎达到了最先进的边界检测性能。为了验证SegFix是否能从STEAL预测的更准确的边界图中获益,我们还训练了一个SegFix模型来只预测方向图,同时使用(固定的)预先计算的STEAL边界图来预测方向图。根据DeepLabv3的粗糙结果,我们发现结果变得略差(80.5%→80.32%)。
4.3 Application to State-of-the-art
我们预先生成边界图和方向图,并将它们应用于各种最先进的方法的分割结果,而不需要额外的训练或微调。
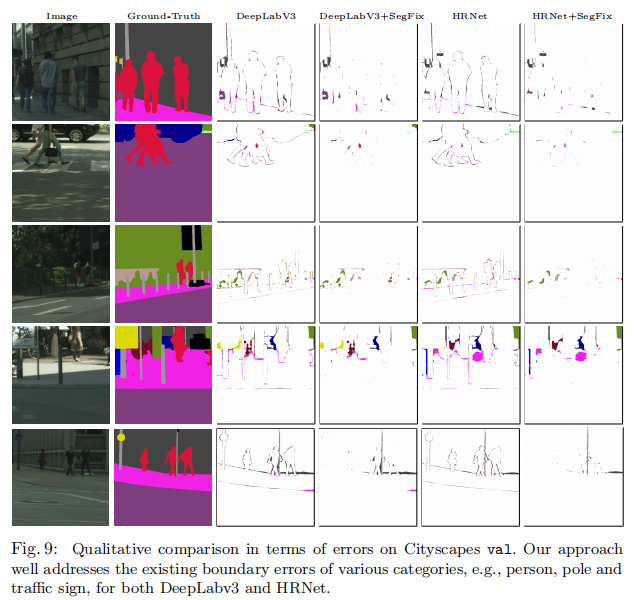
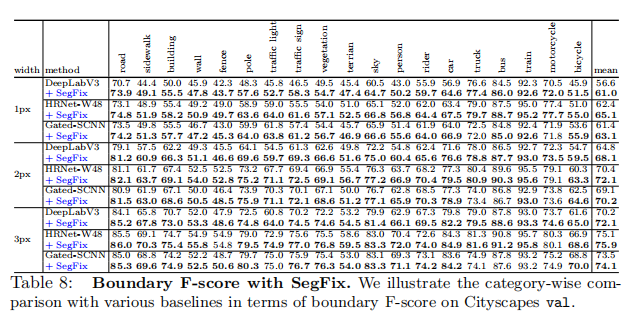
Cityscapes val: 我们首先将我们的方法应用于各种最先进的方法(在Cityscapes市场上),包括DeepLabv3、Gatet-SCNN和HRNet。我们在表8中报告了类别方面的性能改进。可以看出,我们的方法显著提高了所有评估方法边界的分割质量。图8提供了一些基于DeepLabv3和HRNet的我们的方法沿着薄边界进行改进的定性示例。

Cityscapes test: 我们进一步将我们的方法应用于几种最先进的方法,包括PSANet[62]、DANet[22],BFP[17],HRNet[51]、Gated-SCNN[52],VPLR[65]和HRNet+OCR[58]。我们直接应用相同的模型,只用2975个训练图像进行训练,没有任何其他技巧,例如,在验证集或Mapillary Vistas进行训练[46],在线硬示例挖掘。
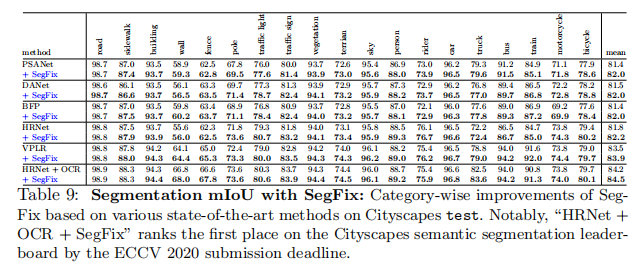
值得注意的是,最先进的方法已经应用了各种先进的技术,如多尺度测试,多网格,执行边界监督或利用额外的训练数据,如Mapillary Vistas或Cityscapes video,以改善其结果。在表9中,我们的模型不可知的边界细化方案一致地改进了所有的评估方法。例如,在我们的SegFix中,“HRNet+OCR”在Cityscapes测试中达到了84.5%。考虑到基线已经非常强了,我们的SegFix的改进实际上已经非常重要了,并且排名最高的方法之间的性能差距仅在0.1%∼的0.3%左右。我们相信,许多其他的高级方法也可能受益于我们的方法。
4.4 Experiments on ADE20K & GTA5
我们在另外两个具有挑战性的语义分割基准测试上评估了我们的SegFix方案,包括ADE20K和GTA5。在这两个数据集上,我们都选择DeepLabV3作为baseline。如表7所示,我们的方法在两个基准测试上也实现了沿边界的显著的性能改进,例如,DeepLabv3的边界f-score分别在ADE20K val/GTA5测试上增加了2.9%/11.5%。

4.5 Unified SegFix Model
我们建议在Cityscapes和ADE20K上训练一个单一统一的SegFix模型,我们报告了对DeepLabv3的改进如下:使用一个单一统一的SegFix模型,Cityscapes的性能提高为0.9%/3.8%,通过mIoU/f-score测量的ADE20K的性能提高为0.5%/2.7%。我们可以看到,这些改进可以与在每个数据集上独立训练的SegFix差不多。更多的实验细节在附录中有所说明。
一般来说,我们只需要训练一个统一的SegFix模型来提高不同分割模型在不同的数据集,因此SegFix更容易训练(节省大量的能源消耗)相比以前的方法[5,52,17,41,40,30]需要重新训练现有的分割模型独立的每个数据集。
4.6 Comparison with Model Ensemble
为了研究我们的SegFix是否主要受益于模型集成,我们进行了一组实验,将我们的方法与在公平设置下的标准模型集成(即集成了两个具有相同紧凑度的分割模型)进行了比较,并将结果报告在表11中。具体来说,当处理分辨率为1024×2048的单个图像时,DeepLabv3+SegFix/DeepLabv3+HRNet-W18的总计算成本分别为2054/2060 GFLOPs。我们可以看到,SegFix的性能优于模型集成,例如,DeepLabv3+SegFix比模型集成方法DeepLabv3+获得1.9%(f-分数),这表明我们的SegFix能够修复模型集成无法解决的边界误差。此外,我们的方法的另一个优点在于,我们可以跨多个数据集使用单一统一的SegFix模型,而模型集成需要在不同的数据集上独立训练多个不同的分割模型。

5 Experiments: Instance Segmentation
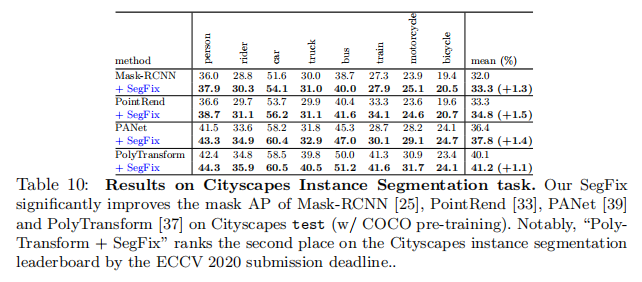
在表10中,我们说明了SegFix在Cityscapes实例分割任务上的结果。我们可以发现,SegFix持续地提高了mAP分数,超过了Mask-RCNN[25],PANet[39],PointRend[33]和多重变换[37]。例如,在SegFix方案中,PANet在Cityscapes测试集上增加了1.4%的分数。我们也将我们的SegFix应用于最近的点数和多元变换。我们的SegFix分别将PointRend和多重变换的性能分别提高了1.5%和1.1%,这进一步验证了我们的方法的有效性。
我们使用Dectectron2和PANet的开源模型生成Mask-RCNN、PointRend和PANet的预测结果。此外,我们还直接使用了PolyTransform的分割结果。更多关于SegFix关于Cityscapes实例分割任务的训练/测试细节在附录中说明。我们相信,SegFix可以直接用于改进其他各种最先进的实例分割方法,而不需要任何先前的要求。
值得注意的是,实例分割任务(+1.1%∼1.5%)的改进比语义分割任务的改进(+0.3%∼0.5%)更显著。我们猜其中的主要原因是实例分割评估(在Cityscapes上)只考虑了8个对象类别,而没有包括这些内容类别。东西类别的性能对边界误差不那么敏感,因为它们的面积(通常)大于对象类别的面积。根据表9中的类别分类结果,我们还可以发现,对几个物体类别的改进,如人、骑手和卡车,比物体类别,如道路、建筑更显著。
6 Conclusion
在本文中,我们提出了一种新的模型无关的方法来细化由未知分割模型预测的分割映射。我们发现,对内部像素的预测更可靠。我们建议用相应的内部像素的预测来代替边界像素的预测。这些对应关系只能从输入的图像中学习出来。该方法的主要优点是SegFix在各种强分割模型上都可以很好地推广。实验结果表明,该方法对语义分割和实例分割任务都是有效的。我们希望我们的SegFix方案可以成为一个强大的基线,以更准确的分割结果沿边界。
7 Appendix
首先,我们需要说明,如果没有指定我们所有的语义分割消融实验,我们都选择DeepLabv3作为基线。在7.1节中,我们说明边界像素在不同类别上的比例的统计数据,因为它们的尺度变化很大。在第7.2节中,我们报告了我们对Cityscapesval的类别mIoU改进。在第7.3节中,我们使用统一的SegFix方案提供了我们实验的更多细节。在7.4节中,我们将介绍关于Cityscapes实例分割任务的更多细节。最后,在第7.5节中,我们说明了我们的方法的更多定性结果。
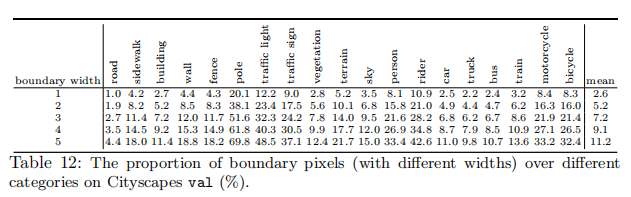
7.1 Statistics of Boundary Pixels
我们在表12中收集了不同类别中边界像素的比例的一些统计数据。我们可以发现,边界像素在极点、交通灯和交通标志三种(小尺度)类别中占很大的比例。事实上,性能改进(以mIoU衡量)也主要来自这三个类别。例如,在表13中,我们的SegFix分别将这三个类别的DeepLabv3的miou提高了3.1%、2.7%和2.4%。
7.2 Category-wise mIoU Improvements
我们对基于DeepLabv3[11]、Gatt-SCNN[52]和HRNet[51]的Cityscapes分割结果执行SegFix。我们在表13中报告了类别方面的mIoU改进,我们可以看到,我们的方法显著提高了对象类别的性能,包括杆点、交通灯和交通标志。关键原因可能是属于这些类别的对象往往规模较小,从准确的边界中获益更多。
7.3 Details of Unified SegFix Experiments
在我们的实现中,我们为SegFix使用相同的主干HRNet-2×,我们说明如下训练策略:我们将批大小设置为16,通过从Cityscapes中采样8个图像和从ADE20K中采样8个图像来构建每个mini-batch。我们选择初始学习率为0.02,所有其他训练设置保持不变。相同的学习速率策略,crop大小为512(对于来自两个数据集的图像)和相同的增强策略。如本文所示,统一的SegFix的性能可与分别在每个数据集上进行训练的SegFix的性能相比较。一般来说,提出的统一SegFix是一种通用方案,可以很好地解决跨多个基准的边界误差。
7.4 Details of Experiments on Instance Segmentation
我们基于开源的Detectron2[54]生成了Mask-RCNN/PointRend的实例分割结果,并直接从作者那里得到了PANet[39]和PolyTransform[37]的结果,因为我们的方法不需要训练任何分割模型。
为了预测实例分割的合适偏移图,我们从实例掩模开始,重新计算GT距离图、边界图和方向图。具体来说,对于实例像素,我们首先根据每个实例映射估计一个距离映射,然后将所有基于实例的距离映射合并为最终的距离映射。我们按照与语义分割方式相同的方式生成它们的方向图和边界图。在测试阶段,我们将预测的偏移映射分别应用于每个预测的实例映射。根据对城市景观实例分割任务的实验结果,我们可以看到SegFix在城市景观测试中不断地提高了各种方法的性能。我们还相信,最近的最先进的方法可能会受益于我们的SegFix。
7.5 More Qualitative Results
我们用图9中的方法说明了更多关于改进(关于语义分割任务)的定性例子。我们可以看到,我们的方法很好地解决了沿着薄边界的误差。由于我们主要关注于薄边界的细化,我们的内部区域仍然存在一些错误,我们的方法无法解决。