论文地址:https://arxiv.org/pdf/1707.03718.pdf
发表时间:2017年
该文对模型的推理速度进行探讨,号称在不显著增加参数数量的情况下进行训练,在Cityscape数据集上的可观的结果。
CSDN上已经有人对该论文进行过详细翻译,这里博主不再进行重复工作,只进行宏观概述。看完该论文,感觉是听君一席话,如xxxxx。论文详细翻译地址:LinkNet论文翻译
1、LinkNet的网络结构
网络结构如下所示,是一个简单的u型网络,平平无奇。与unet相比就是只是将通道concat更改为add操作,该操作可以一定程度上减少解码过程中的计算量和参数量。网络的编码器从一个初始块开始,该初始块对输入图像进行卷积,其核大小为7×7,步幅为2,该块还在3×3的区域中执行空间最大池化,步幅为2。
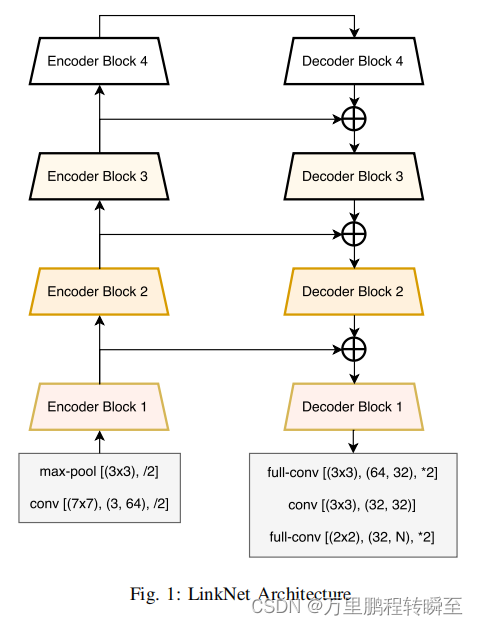
其编码器单个block的结构如下所示,其中3x3表示卷积核的大小,(m,n)表示block输入输出的通道,/2表示卷积核移动的步长
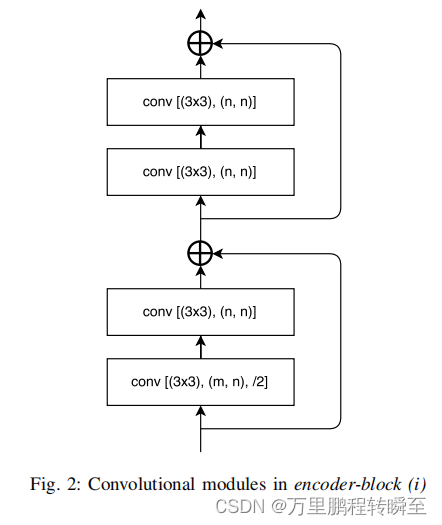
解码器单个block的结构如下所示,(m,n)表示block输入输出的通道,其特点是在一些layer中通道数进行了压缩,然后是在full-conv中进行的上采样。
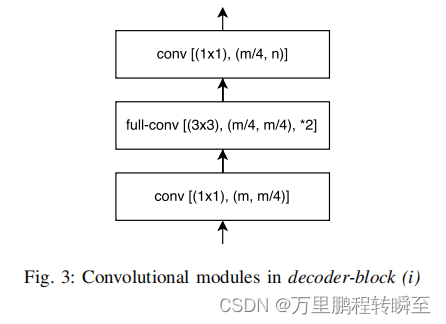
博主因为full-conv对linknet中解码器block比较感兴趣,因而阅读了segmentation_models_pytorch库中LinknetDecoder里面DecoderBlock的实现。核心代码如下所示,是用ConvTranspose2d实现的上采样。
class TransposeX2(nn.Sequential):
def __init__(self, in_channels, out_channels, use_batchnorm=True):
super().__init__()
layers = [
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1),
nn.ReLU(inplace=True)
]
if use_batchnorm:
layers.insert(1, nn.BatchNorm2d(out_channels))
super().__init__(*layers)
class DecoderBlock(nn.Module):
def __init__(self, in_channels, out_channels, use_batchnorm=True):
super().__init__()
self.block = nn.Sequential(
modules.Conv2dReLU(in_channels, in_channels // 4, kernel_size=1, use_batchnorm=use_batchnorm),
TransposeX2(in_channels // 4, in_channels // 4, use_batchnorm=use_batchnorm),
modules.Conv2dReLU(in_channels // 4, out_channels, kernel_size=1, use_batchnorm=use_batchnorm),
)
def forward(self, x, skip=None):
x = self.block(x)
if skip is not None:
x = x + skip
return x
class LinknetDecoder(nn.Module):
def __init__(
self,
encoder_channels,
prefinal_channels=32,
n_blocks=5,
use_batchnorm=True,
):
super().__init__()
encoder_channels = encoder_channels[1:] # remove first skip
encoder_channels = encoder_channels[::-1] # reverse channels to start from head of encoder
channels = list(encoder_channels) + [prefinal_channels]
self.blocks = nn.ModuleList([
DecoderBlock(channels[i], channels[i + 1], use_batchnorm=use_batchnorm)
for i in range(n_blocks)
])
def forward(self, *features):
features = features[1:] # remove first skip
features = features[::-1] # reverse channels to start from head of encoder
x = features[0]
skips = features[1:]
for i, decoder_block in enumerate(self.blocks):
skip = skips[i] if i < len(skips) else None
x = decoder_block(x, skip)
return x
2、LinkNet的实验效果
2.1 运行速度对比
与当时的网络对比,可见速度还是可以的
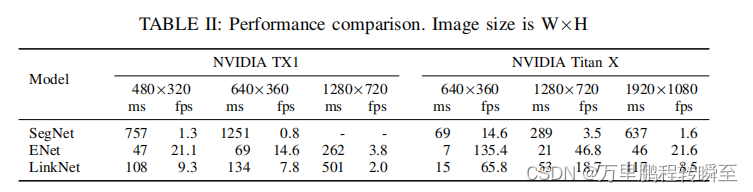
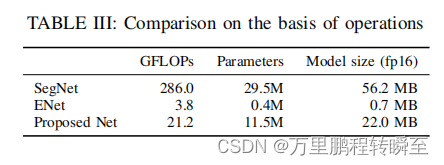
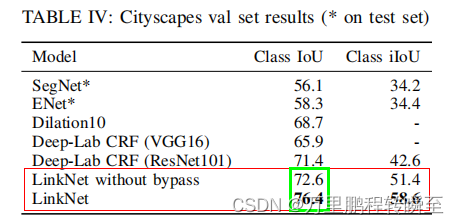
2.2 iou对比
与同时期的网络相比iou水平还是可以的
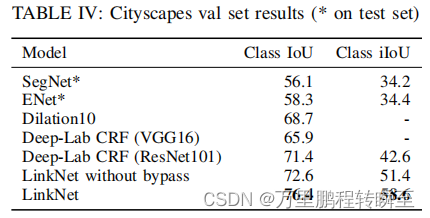
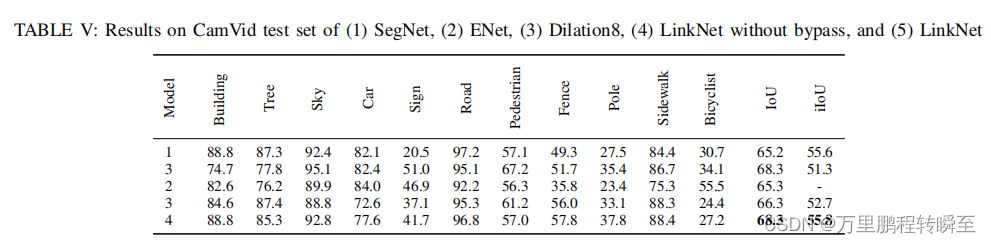
一些实验效果图如下所示
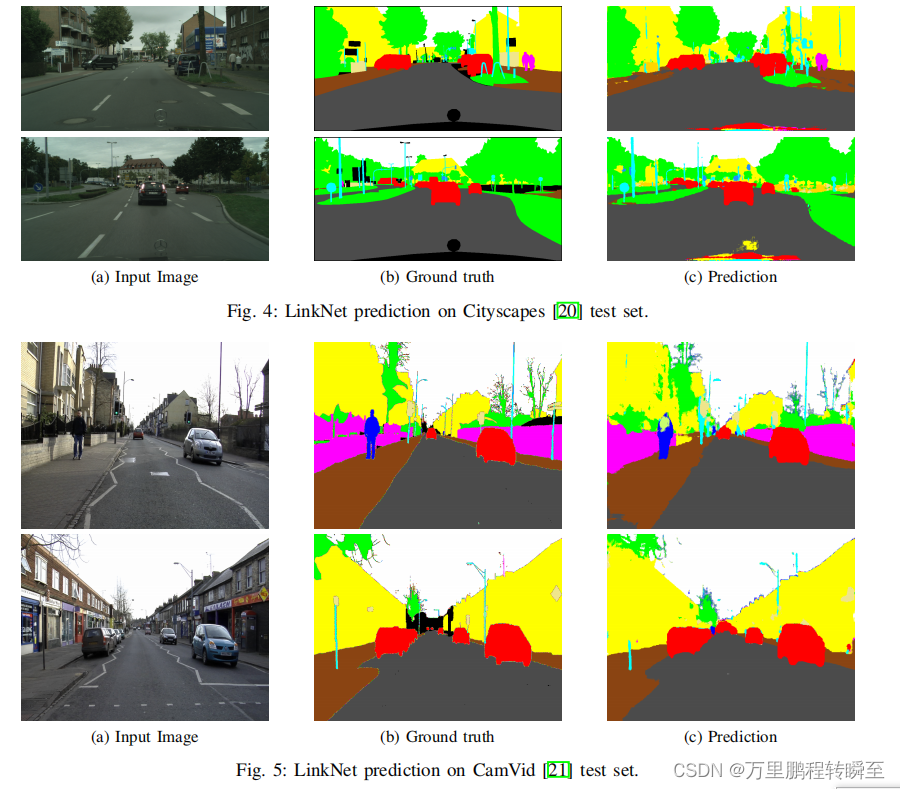
3、总结
个人感觉LinkNet的结构确实可以减少一定的运算量,但是这平平无奇的网络结构能取得较为惊艳的效果,博主认为还是作者的调参能力太强了。因为博主认为LinkNet能取得的效果,Unet一样也可以(两者的网络结构相似度太高了)。作者也在其论文中展示了,无bypass结构时的iou,使用bypass结构后增益极其明显。