Title:Understand Convolution for Semantic Segmentation
From:IEEE Winter Conference on Applications of Computer Vision (WACV 2018)
Note data:2019/06/16
Abstract:介绍两种操作卷积相关运算(密集上采样卷积,混合空洞卷积)以提高分割效果
Code :MXNet
目录
1 Abstract
论文提出两张卷积相关的方法来提高逐像素语义分割:
- 密集上采样(dense upsampling convolution,DUC)生成预测结果,这可以捕获在双线性上采样过程中丢失的细节信息
- 混合扩张卷积(hybrid dilated convolution,HDC)用于减少扩张卷积产生的gridding问题,扩大感受野聚合全局信息
论文在公共数据集上表现优异,达到了state-of-the-art结果!
2 Introduction
应用在语义分割上的CNN系统可分为三类:
- 全卷积网络(FCN):将最后的全连接层换为卷积层,接受任意大小的输入,减小模型大小;
- 使用CRF:将结构预测用于捕获图片内的本地与长距离依赖,用于细化分割;
- 使用扩张卷积(dilate convolution):增加特征图的分辨率的同时扩大感受野的大小,保持计算成本以及提高预测精度
论文中提出现今的一些模型提高分割准确率主要有以下两种方向:
- 使用更加好的提取特征的模型,如ResNet,VGG等作为预训练骨架,复杂的网络结构提取更多的高层语义信息,学习更有区分的特征用于分割;
- 使用CRF作为后端处理,将CRF优化到end2end中进行训练,使得边缘等额外信息合并到CRF内
本文从编码与解码阶段进行提升模型性能主要分为以下两个步骤:
- 解码阶段:在以往的一些工作中使用双线性插值上采样直接获得与输入同分辨率的输出,双线性插值没有学习能力并且会丢失细节信息。本文提出密集上采样卷积(DUC),取代简单的双线性插值,学习一组上采样滤波器用于放大低分辨率的特征;
- 编码阶段:使用扩展卷积扩大感受野,减少下采样(下采样丢失细节信息)。
本文指出空洞卷积存在"girdding"问题,即空洞卷积在卷积核两个采样像素之间插入0值,如果扩张率过大,卷积会过于稀疏,捕获信息能力差。 本文提出了混合扩展卷积架构(hybrid dilation convolution,HDC): 使用一组扩展率卷积串接一下构成block,可扩大感受野的同时减轻"gridding"弊端。
3 Related Work
论文从以下两个方面介绍了相关工作:
- 特征表示解码(Decoding of Feature Representation):因为池化操作中的下采样和stride Convolution导致了feature map分辨率的降低,从而损失语义信息。现在多种方案针对低分辨率特征图解码出准确信息,常常采用双线性上采样方式,与此同时,解卷积使用池化位置信息帮助解码(SegNet),也有使用堆叠的解卷积层恢复信息等;
- 扩张卷积(dilated Convolution):在卷积采样中插入0,用以扩张采样分辨率。Deeplab系列中费用ASPP聚合多尺度信息等。
4 Method
4.1 密集上采样卷积(DUC)
考虑到模型输入图片大小(H,W,C),整个模型在预测前的输出feature map大小为Fout=(h,w,c) ,其中 H/d=h,W/d=w,d称为下采样因子(downsampling factor)。
双线性插值存在的问题:如果模型的d=16,即输入到输出下采样了16倍。如果一个目标物的长或宽长度小于16个pixel,训练label map需要下采样到与模型输出维度相同,即下采样16倍时已经丢失了许多细节, 对应的模型预测结果双线性插值上采样是无法恢复这个信息 。
针对以上这个问题,论文提出了DUC的解决方法!将DUC将Fout的尺寸(h,w,c) 通道转为到(h,w,d2×L), L是分割类别数目。再reshape到label map大小(H,W,L) 。reshape操作代替了解卷积上采样,可直接对接label map。

从另一个角度想:DUC将整个label map(H,W,L) 分为d2个等大小的子图(subparts),每个子图和大小和Fout 输出的feature map大小相同。也就是说将label map切分为(h,w,d2×L) 。
DUC以原始分辨率像素级解码,并且能够自然的集成到FCN框架中,使得整个编码和解码能以end2end方式训练。
4.2 混合扩展卷积
![]()

- 对于左边:r=2,k=3 .k_d=3+(3-1)(2-1)=5,接收野为5×5
- 对于右边:r=3,k=3 k_d=3+(3-1)(3-1)=7,接收野为7×7
扩张卷积可增加features map的分辨率,故可替换FCN架构中的池化层。但是,扩张卷积存在一个理论上的问题,称之为"gridding":对于扩张卷积的一个像素点p,对其有贡献的是上一层以p为中心的 k_d×k_d的邻近区域,因为扩张卷积引入0值,在k_d×k_d的区域只计算k×k 个像素点,非0像素点之间间隔为r−1
1. 当high layer中r 变的越来越大,这会使得从输入中采样的数据越来越稀疏,不利于卷积学习,因为
- 局部的信息完全丢失
- 信息之间太远不相关
2.r×r 的区域从完全不同的“网格”集合内接收信息,这会损害本地信息的一致性。
论文提出HDC用于缓解gridding问题,考虑到一个N个size为K*K的扩张卷积,对应扩张率不同,HDC的目标就是让最后的接受野全覆盖整个区域。
论文给出使用不同扩张率的扩张卷积策略是锯齿波(sawtooth wave-like)变化形式:即取几层为一组,每个组的扩张率从低向高增加,每个组类似,即扩张率变换类似锯齿波。锯齿波能同时满足小物体大物体的分割要求(小rate提取本地信息,大rate提取长距离信息)。

例如:对于r=2的层,将3个层组成一组,对应的扩张率分别为1,2,3。这样顶层可以获取更宽阔的区域信息,这能在保持接收野大小不变的情况下提高信息利用率。
需要注意的是,一个组内的卷积不应该有一个固定的变换因子,即不要用大于1的公约数(例如2,4,8的公约数为2>1),否则依旧无法减小"girdding"效应。
HDC的另一个好处是可以使用任意的扩张率,很自然的扩大了接收野且不需要添加额外的模块,这对识别大型相关目标很关键。
5 Experiment
实验细节:
| 项目 | 属性 |
| 数据集 | Cityscapes,KITTI, PASCAL VOC2012 |
| 预训练 | ResNet-101 , ResNet-152 |
| 损失函数 | cross-entropy |
| 优化器 | SGD |
| 框架 | MXNet |
| 实现工具 | TITAN X |
实验结果如下:
Abation Studies:主要做以下方面的实验.
- 网络的下采样扩张率,用于控制内部的feature map的分辨率
- 是否使用ASPP模块,以及使用并行路径的数量
- 是否做数据增强,即将数据切分为12个子patches
- 一个预测像素投影的邻近区域大小(cell,cell) (cell,cell)(cell,cell).像素级的DUC应该使用cell=1 cell=1cell=1,但因为Gound Truth无法达到像素级,在实验中尝试cell=2 cell=2cell=2

降低下采样率会降低准确率。ASPP模块通常有助于改善性能。数据增强有助于提高准确率,使用cell=2有轻微的提升,同时有助于降低计算消耗。
Bigger Patch Size: 因为cell=2 会大幅度减少计算量消耗,故讨论patch size对性能的影响。将patch size提高到880×880 ,将原本的12倍cropping换成7倍的cropping,性能提升了1%;
Compared with Deconvolution: 使用上采样效率略低于DUC model;
Conditional Random Fields(CRF): 使用CRF提高了1%的性能。
HDC
以最佳的101 layer的ResNet-DUC为基础,添加HDC,实验探究了几种变体:
- 无扩张卷积(no dilation):对于所有包含扩张卷积,设置r=1
- 扩张卷积(dilation Conv ):对于所有包含扩张卷积,将2个block和为一组,设置第一个block的r=2,第二个block的r=1
- Dilation-RF:对于res4b包含了23个blocks,使用的r=2,设置3个block一组,r=1,2,3 .对于最后两个block,设置r=2 ;对于res5b ,包含3个block,使用r=4 ,设置为r=3,4,5
- Dilation-Bigger:对于res4b res4bres4b模块,设置4个block为一组,设置r=1,2,5,9.最后3个block设置为1,2,5 ;对于res5b模块,设置r=5,9,17



Deeper Networks: 同样尝试了将ResNet-101切换为ResNet-152,使用ResNet152先跑了10个epoch学习了BN层参数,再固定BN层,跑了20个epochs.结果如下:

ResNet152为基础层的有1%的提升。
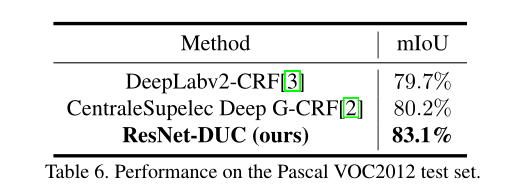
Test Set Results: 论文将ResNet101开始的7×7卷积拆分为3个3×3 的卷积,再不带CRF的情况下达到了80.1%mIoU.与其他先进模型相比如下:

KITTI数据集上表现:

VOC2012上表现:
6 Conclusion
模型使用DUC恢复上采样丢失的信息,使用HDC在解决"gridding"的影响的同时扩大感受野。实验证明我们的框架对各种语义分割任务的有效性。也给我们一种启示将有效模块进行融合或许可以得到最优的模型。
