写在最前面:为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便。期间有参考了很多博客和文献,但是我写的仍然很粗糙,存在很多的疑问。
这篇文章是实例分割方向文献,先放上来自己最初的理解。当然其中参考了很多大佬的现有的理解,可能参考的东西太多,有疏漏。提示:排版对手机不友好。
原文地址:Fully Convolutional Instance-aware Semantic Segmentation
参考译文:实例分割初探,Fully Convolutional Instance-aware Semantic Segmentation论文解读
参考说明:论文阅读理解 - Fully Convolutional Instance-aware Semantic Segmentation
论文的背景
语义分割的目的是在一张图里分割聚类出不同物体的像素,其中每个像素被标记为其封闭对象的类,当前主流的框架主要是基于全卷积神经网络FCN[1]。区别于诸如AlexNet等物体识别框架对整个图进行预测,FCN对一张图进行了像素级别的预测,但是无法进行图像检测。
实例分割是语义分割的进一步工作,将区分识别每一个物体实例并对重叠区进行进一步的分析,对于统计图像中某物体的个数等相关任务有着至关重要的的作用。在语义分割的基础上,[2][3]在Dense Feature Map上整合得到Score Map,然后再进行分割,其实质在于语义分割和物体检测的殊途同归的结合。
本文由清华大学和微软研究院合作,提出了一种全新的架构FCIS,是第一个运用全卷积网络,实现端到端的实例分割解决方案。FCIS考虑到分割和分类之间的关系,为实例分割提供了一个高效、简单、准确的框架。
论文内容
1、论文结构
Section 1(Introduction):
对现阶段的语义分割和实例分割的研究情况的一个简单介绍,强调了FCN 的便捷性、高效性和权值共享等特点。针对现有的FCNs网络,提出了FCIS网络结构,并简要的阐述了该网络的优点。
Section 2 (Our Approach):
对FCIS网络中新提出的改进进行了说明,主要体现在了三个方面:位置敏感的参数化分数图、掩模预测和分类的联合以及端到端特性。
Section 3 (Related Work):
针对语义分割、物体分割建议、实例相关的语义分割和利用FCNs进行物体检测四个问题,进行了简要的说明。
Section 4 (Experience):
通过在PASCAL VOC[6]以及COCO[7]进行了对比试验,验证FCIS方法的效果。
Section 5 (Conclusion):
FCIS的贡献的总结。
2、当前实例分割方法的不足
实例分割的效果可以说是有以下三点的组合而成:
- 将物体从背景中分离(测试结果上只是没有画出目标框),即目标检测。
- 对检测到的物体进行逐像素提取,即图像分割。
- 对检测到的物体进行类别划分,即图像分类。
因此,实例分割是一个综合性的问题,融合了目标检测,图像分割与图像分类。实例分割的结果包含的信息相当丰富,代表作包括Mask R-CNN与本文介绍的FCIS,前者是Facebook团队贡献的,后者是是微软的团队贡献的。
A、基于FCN的方法

图1 DeepLab论文中分割效果图
从上图中可以看到,如果是实例分割,在白色框的内部某些像素会被分类成人,属于前景,而剩余的像素则是背景。同样地,在黄色框内,某些像素会被划分为摩托车,而其余的像素会被划分为背景。那么,在白色框与黄色框重复的区域,有些像素的语义就出现了歧义,如在白色框中是背景,在黄色框中是前景。传统的图像分割网络采用交叉熵,结合图像标签端到端训练。对于这个问题,由于卷积的平移不变性,一个像素点的语义类别是固定的,因此没有办法达到实例分割的效果。也因此,产生了实例分割的问题。
B、三步走方法

图2 三步走方法示意图
如上图所示,文章中提出了一般思路下的实例分割方法分为三步:
⑴ 对图像进行FCN处理,得到中间的共享特征图;
⑵ 对于得到的多张特征图,采用池化层将各个感受野 (ROI)变换到固定尺寸的per-ROI feature maps。
⑶ 在网络最后,采用一个或多个全连接层将per-ROI feature maps转换成per-ROI masks,这里的平移不变形是在全连接层实现的。
同时文章对于这中三步走的方法进行了缺点分析:
⑴ 在感受野进行池化的这一步,为了得到固定尺寸的图像对原始图像进行了尺寸上的拉伸和压缩,产生了量化上损失的空间信息。
⑵ 全连接层的参数太多,容易过拟合。
⑶ 最后处理时,每个感受野都要过一次全连接层,感受野之间不能进行参数共享,耗时多。
3、FCIS网络结构
针对上述的三个问题,FCIS提出的解决方法如下:
⑴ 针对缺点一,取消了感受野的池化层,对感受野进行了聚合,实质就是对感受野进行了复制粘贴;
⑵ 针对缺点二,取消了全连接层,换成了全卷积层和softmax层(分类器);
⑶ 针对缺点三,特征图像在分割和分类时得到共享。
A、位置敏感的Score Map
针对卷积层的平移不变性,参照[3],FCIS生成组特征图,每一组特征图,称为score map。

图3 Score map的示意图
每一组score map,对应输入图像的ROI,表示该ROI的不同位置的分数(score)。比如,左上角的一张score map,代表的就是输入图像中左上部分的ROI中的左上角部分(标志为1的小框内部)的score,其他的类推。score代表的含义是某个特定位置(小窗)的像素点属于ROI中的前景的分数。
通过上述方法,就可以解决卷积的平移不变性,使得在不同的感受野中的重叠部分可以被分类成不同区域(前景或背景)。
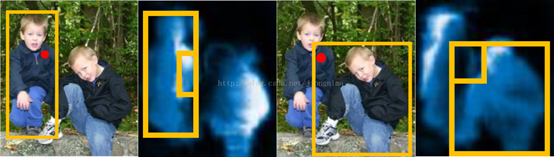
图4 不同感受野下不同的Score map
从上图中,可以看到,在不同的感受野内,红点处的score不同。这就是想要的表达形式:相同区域,不同感受野,不同语义的问题。
B、联合分类与预测
从上述的方法中可以看到,解决了卷积不变所带来的问题。但是像SDS[8],Hypercolumn[9]以及CFM[10]等方法,分类和分割的任务还是看作两个互不相关的子网络来处理,忽略了两个任务之间的关系,消耗了的时间和空间。
针对此问题,FCIS提出了Inside/Outside Map两种Score Map。

图5 分割和分类共同考虑的Inside/Outside Map
从图中可以看出,对位置敏感的inside/outside score maps在整个网络中是共享的,即图中的每一行的18组特征图是相同的。针对图像分割任务和图像分类任务,FCIS做了这样的处理:
- 对于每个感受野区域,将inside score maps和outside score maps中的小块特征图复制出来,拼接成为了ROI inside map和ROI outside map。
- 针对图像分割任务,直接对上述两类ROI map通过softmax分类器分类,得到ROI中的目标前景区域(Mask)。
- 针对图像分类任务,将两类ROI map中的score逐像素取最大值,得到一个map,然后再通过一个softmax分类器,得到该ROI区域对应的图像类别。
在完成图像分类的同时,还顺便验证了ROI区域检测是否合理,具体做法是求取最大值得到的map的所有值的平均数,如果该平均数大于某个阈值,则该ROI检测是合理的。
针对输入图像上的每一个像素点,有三种情况:
- 第一种情况是inside score高,outside score低;则该像素点位于ROI中的目标部分。
- 第二种情况是inside score低,outside score高,则该像素点位于ROI中的背景部分。
- 第三种情况是inside score和outside score都很低,那么该像素点不在任何一个ROI里面。
因此,我们在上一段中描述的,针对ROI inside map和ROI outside map中逐像素点取最大值得到的图像:如果求平均后分数还是很低,那么,我们可以断定这个检测区域是不合理的。如果求平均后分数超过了某个阈值,我们就通过softmax分类器求ROI的图像类别,再通过softmax分类器求前景与背景。
C、端到端

图6 FCIS的整体结构
从上图中可以看到,FCIS的整体流程为:
- 图像输入进来,经过卷积层提取初步特征;
- 利用提取的特征,一边经过RPN(Region Proposal Network)网络提取ROI,一边再经过一些卷积层生成
个特征图。2代表inside和outside两类;
代表图像类别一共
类,再加上背景(未知的)类;
表每一类score map中各有
个(上图的例子中
- 在经过assembling之后(其实就是复制粘贴),对于每一个ROI,
),得到
个特征图。
- 紧接着进行并行操作,第一条线:对于每一类的ROI inside map和ROI outside map逐像素取最大值,得到了
个特征图,对这
论文中还提到,对于输入图像,采用RPN方法得到最高score的300个ROIs;并经过 B-box回归分支,得到新的 300个ROIs。采用交并比阈值0.3的非最大值抑制方法来去除重合度较高的ROIs,将剩余的ROIs根据最高的分类scores来进行分类。
在训练的过程中,首先是使用了孔洞卷积(atrous convolution),并且使用SGD优化器端到端训练。
D、损失函数
对于训练过程,对于每一个ROI,损失函数由三部分组成,如下表述:
- 在
- 对于positive ROI,有一个前景与背景的分类损失(softmax loss)。
- 对于positive ROI,有一个回归框回归的损失。positive ROI指的是,这个ROI与Ground Truth上面与其最近的目标包围框重叠区域占比在0.5以上。
对于RPN阶段,主要有两大部分的损失:
- 分类损失(softmax loss),区分提出的ROI到底是前景还是背景。
- 回归框回归损失,目的是在粗糙程度上提出最合理的ROI。
4、FCIS的实验结果
A、在PASCAL VOC上的对比实验
如下表所示,通过FCIS与当前的一些基于全卷积的网络的方法对比可知,FCIS提高了准确率。并且通过设置,对比将两个Score Map分离和结合的效果可以看到,解决了平移不变性和联合分类和分割之后的准确率得到了效果的提升。
表1 PASCAL VOC的实验结果

B、在COCO上的实验
表2 COCO数据集实验

通过上表可以看到,FCIS在精度和效率方面均高于MNS。
论文的优点
⑴ 引入inside/outside score maps架构,使得图像分割与图像分类完全可以共享特征图。
⑵ 完全抛弃了全连接层,使得网络更加轻量,并且从集成的score map到最后的结果,没有可训练参数存在,存在的只是分类器;
⑶ 继续使用RPN生成ROI;
论文的缺点
⑴ 训练过程中使用了8块GPU(K40)联合训练,每一块GPU只能运行一个mini batch,由此来看,训练成本比较高。
论文前提知识:FCN(参考1和参考2)
全卷积网络的整体网络架构图如下图所示:

图7 FCN的整体网络结构
A、上半部分:特征提取
虚线上的部分为全卷积网络(蓝色代表卷积层,绿色代表最大池化层)。对于不同尺寸的输入图像,各层数据的尺寸相应变化,深度不变。这部分由深度学习分类问题中经典网络AlexNet[4]修改而来。只不过,把最后两个全连接层改成了卷积层。论文[1]中,达到最高精度的分类网络是VGG16[5],但提供的模型基于AlexNet。
B、下半部分:逐像素预测(此处存疑)
虚线下半部分中,分别从卷积网络的不同阶段,以卷积层(蓝色)预测深度为21的分类结果(20个目标,1个背景)。例:第一个预测模块中,输入,卷积模板尺寸
,输出
。相当于对每个像素施加一个全连接层,从4096维特征,预测21类结果。
C、训练阶段
1、第一阶段:
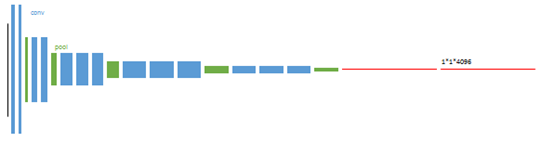
图8 第一个训练阶段
以经典的分类网络为初始化,最后两级是全连接层(红色),参数弃去不用。
2、第二阶段:

图9 第二个训练阶段
从特征小图()预测分割小图(
),之后直接升采样为大图。反卷积(橙色)的步长为32,这个网络称为FCN-32s。这一阶段使用单GPU训练约需3天。
3、第三阶段

图10 第三个训练阶段
升采样分为两次完成(橙色)。在第二次升采样前,把第4个池化层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。第二次反卷积步长为16,这个网络称为FCN-16s。这一阶段使用单GPU训练约需1天。
4、第四阶段

图11 第四个训练阶段
升采样分为三次完成(橙色),进一步融合了第3个池化层的预测结果。第三次反卷积步长为8,记为FCN-8s。这一阶段使用单GPU训练约需1天。
较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果。

图12 上采样的效果对比图
产生的问题
A、由卷积得到的特征图在进行全连接的时候是具体怎么操作的(与深度学习理论知识的中全连接层的关系)?(全连接参考)
首先,深度学习中理论知识对全连接层的定义如图:

图13 深度学习中的全连接层
可以看到相邻的两个层所有的神经元相互连接。那么简便来说,从后面一层来讲,该层每一个神经元(或者说数值)都与前一层所有的神经元(或者说数值)有关(相连)。经过多层卷积层(以及池化层)之后,得到是一张张二维的特征图,不像上图中的结点。所以需要将二维的数据(考虑到通道以及实际操作中应该是更高维)进行拉伸,得到一维的数据(保证数据的节点个数不变),然后再经过全连接层。所以可想而知,全连接层的参数是很多的。
全连接层对于数据的特征进行了融合,可以做到目标的检测作用,但是忽略了空间信息。如下图所示,假如已经得到了训练的模型,可以根据猫的不同的特征进行判断当前的目标是不是一个猫。经过全连接层的特征融合,可以看到不同位置,例如猫的头、尾巴、脚以及身体等特征被激活(图中红色的节点)。
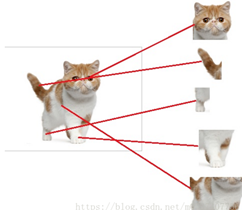

图14 全连接层的作用原理
同样的可以对猫头的识别进行拆分成多个特征的融合,例如猫的眼睛、嘴巴、耳朵以及毛发等,在足够多的特征被激活的情况下,判断当前是不是一个猫头,而这些特征全部来源于前面的卷积层和下采样层得到的。
卷积块中的卷积的基本单元是局部视野,用它类比我们的眼睛的话,就是将外界信息翻译成神经信号的工具,它能将接收的输入中的各个特征提取出来。全连接层则可以类比我们的神经网络(或者说类比我们的大脑),它能够利用卷积块得到的信号(特征)来做出相应的决策。概括地说、卷积神经网络视卷积块为“眼”而视全连接层为“脑”,眼脑结合则决策自成。
B、全连接层换成全卷积层?
根据上面的说法,可以倒着去看,一维的向量中每一个点都要与每个二维特征图相连。例如在经过卷积层(以及ReLU)之后得到一个输出。那么怎么最后的
的数据是怎么来的呢?

图15 数据向
的转化
再假设最后一个卷积层的输出为,连接此卷积层的全连接层为
。全连接层实际就是卷积核大小为上层特征大小的卷积运算,卷积后的结果为一个节点,就对应全连接层的一个点。如果将这个全连接层转化为卷积层:
-
- 共有4096组滤波器;
- 每组滤波器含有512个卷积核;
- 每个卷积核的大小为
;
- 输出为
;
1、参数个数
通过上图可以看到,每一个全连接层都可以用等价的全卷积来代替,同时可以看到假如卷积核一定程度上是共享的,那么参数的个数将极大地减少。
2、空间结构
全连接层做到的就是一个特征的融合,忽略了图像特征的空间位置特征,对分割十分不利。如下图所示:

图16 卷积的平移不变性
在FCN网络中,通过三次上采样和卷积核,可以对原始的空间信息一定程度的还原。

图17 FCN的上采样原理图
但是得到的结果还上还不够精确,一些细节无法恢复。于是将第四层的输出和第三层的输出也依次反卷积,分别需要16倍和8倍上采样,结果过也更精细一些了。这种做法的好处是兼顾了local和global信息。
C、为什么说全连接层换成全卷积层可以提升效率?
网上的例子均来自于CS231n课堂的例子,看着有点眉目的文章链接。但是这里还是有点问题,假如说一个网络的结构固定了,那么它的全连接层的参数矩阵确定,对于非的图片无法使用。但是在
的图片经过前面几层卷积和池化,得到了一个
。那么假如说给了一个任意尺寸的图片,经过卷积和池化之后,得到的特征图的尺寸还是不固定的,那么全连接层的卷积核不就是不确定的吗?在一个确定的网络结构中,这个卷积核是可变的吗?假如这个是可变的,那么全连接层的参数矩阵为什么不可以变?
D、为什么传统的卷积网络的输入图像是固定尺寸的?(下面说法的链接,但是觉得哪里有点问题,为什么神经网络结构得确定?)
对于原始的卷积神经网络结构,一幅输入图片在经过卷积和池化层层时,这些层是不关心图片大小的。比如对于一个卷积层,,它并不关心输入图像多大,对于任意一个大小的输入特征图,进行滑窗卷积,输出
大小的特征图即可。池化层同理。但是在进入全连接层时,特征图(假设大小为
)要拉成一条向量,而向量中每个元素(共
个)作为一个结点都要与下一个层的所有结点(假设4096个)全连接,这里的权值个数是
。而我们知道神经网络结构一旦确定,它的权值个数都是固定的,所以这个
不能变化,
是
的
,所以层层向回看,每个
都要固定,那每个
都要固定,因此输入图片大小要固定。
E、FCN上采样后对每个像素进行了分类?(未解决)
全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别,即从图像级别的分类进一步延伸到像素级别的分类。(怎么做到的)
目前觉得这篇文章有点道理,但是还是觉得哪里不太对劲。
F、Invariance vs. Equivariance?
网上普遍将Translation Invariance(平移不变性)和Translation Equivariance(平移等效性)视为一个问题。但是在这个网址中说到,Invariance 说明的是卷积的响应对物体的位置不敏感,即物体在不同的位置都可以得到相同的响应,如下图所示:

图18 Translation Invariance示意图
而Equivariance说明的是在一个系统下,响应的机制是一样的,但是在不同的位置下响应还是不同的。这儿有个解释,越说越有点不懂。
- an Operator is equivariant with respect to a Transformation when the effect of the Transformation is detectable in the Operator Output.
- an Operator is invariant with respect to a Transformation when the effect of the Transformation is not detectable in the Operator Output.
F、Why and how are convolutional neural networks translation-invariant??
因为卷积的性质,参考这个链接
参考文献
- Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation[J]. computer vision and pattern recognition, 2015: 3431-3440.
- Dai J, He K, Sun J, et al. Instance-Aware Semantic Segmentation via Multi-task Network Cascades[J]. computer vision and pattern recognition, 2016: 3150-3158.
- Dai J, He K, Li Y, et al. Instance-Sensitive Fully Convolutional Networks[J]. european conference on computer vision, 2016: 534-549.
- Krizhevsky A, Sutskever I, Hinton G E, et al. ImageNet Classification with Deep Convolutional Neural Networks[C]. neural information processing systems, 2012: 1097-1105.
- Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
- Everingham M, Van Gool L, Williams C K, et al. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
- Lin T, Maire M, Belongie S J, et al. Microsoft COCO: Common Objects in Context[J]. european conference on computer vision, 2014: 740-755.
- Hariharan B, Arbelaez P, Girshick R B, et al. Simultaneous Detection and Segmentation[J]. european conference on computer vision, 2014: 297-312.
- Hariharan B, Arbelaez P, Girshick R B, et al. Hypercolumns for object segmentation and fine-grained localization[J]. computer vision and pattern recognition, 2015: 447-456.
- Dai J, He K, Sun J, et al. Convolutional feature masking for joint object and stuff segmentation[J]. computer vision and pattern recognition, 2015: 3992-4000.
附录
附录一:
表3 术语对照表
| 英语表达 |
中文翻译 |
| Translation Equivariance |
变换等效性 |
| Atrous Convolution |
孔洞卷积 |
| Stochastic gradient descent(SGD) |
随机梯度下降 |