
论文地址:https://arxiv.org/pdf/1909.11065.pdf
发布年份:2021
本文研究了语义分割中的上下文聚合问题。由于一个像素的标签是该像素所属的对象的类别,我们提出了一种简单而有效的方法,即对象-上下文表示( object-contextual representations,OCR),通过利用相应的对象类的表示来描述一个像素。首先,我们在地面真实分割的监督下学习目标区域。其次,我们通过聚合位于对象区域中的像素的表示来计算对象区域表示。最后,我们计算每个像素与每个对象区域之间的关系,并使用对象-上下文表示来增强每个像素的表示,这是所有对象区域表示的加权聚合。我们通过经验证明了我们的方法在各种基准上实现了具有竞争力的性能:城市景观、ADE20K、LIP、帕斯卡-上下文和协同内容。我们提交的“HRNet+OCR+SegFix”在ECCV2020提交截止日期前获得了城市景观排行榜的第一名。代码在 https://git.io/openseg and https://git.io/HRNet.OCR 可见。
我们使用Transformer编码器-解码器框架来重新表述对象-上下文表示方案。前两步,对象区域学习和对象区域表示计算,被集成为解码器中的交叉注意模块:用于分类像素的线性投影,即生成对象区域,是类别查询,对象区域表示是交叉注意输出。最后一步是我们添加到编码器中的交叉注意模块,其中键和值是解码器的输出,查询是每个位置的表示。详情见第3.3节。
1 Introduction
语义分割是一个为图像的每个像素分配一个类标签的问题。它是计算机视觉中的一个基本课题,对自动驾驶等各种实际任务都至关重要。深度卷积网络自FCN[47]出现以来,一直是主要的解决方案。目前已经进行了各种研究,包括高分辨率表示学习[7,54]、本文感兴趣的上下文聚合[80,6]等。
一个位置的上下文通常是指一组位置,例如,周围的像素。早期的研究主要是关于语境的空间尺度,即空间范围。有代表性的作品,如ASPP[6]和PPM[80],利用了多尺度的上下文。最近,一些作品,如DANet[18],CFNet[77]和OCNet[72,71],考虑了一个位置与其上下文位置之间的关系,并以相似的权重聚合了上下文位置的表征。
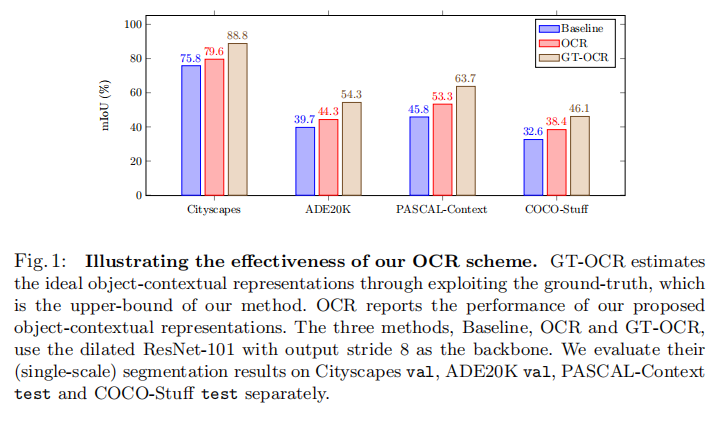
我们建议沿着探索位置和上下文之间的关系来研究上下文表示方案。其动机是,分配给一个像素的类标签是该像素所属的对象的类别。我们的目标是通过利用相应类的对象区域的表示来增加一个像素的表示。实证研究如图1所示,当给出GT对象区域时,这种表示增强方案显著提高了分割质量。
我们的方法包括三个主要步骤。首先,我们将上下文像素划分为一组软对象区域,每个区域对应于一个类,即从深度网络(如ResNet[25]或HRNet[54])计算出的粗软分割。这种划分是在ground-truth分割的监督下学习的。其次,我们通过聚合相应对象区域中像素的表示来估计每个对象区域的表示。最后,我们用对象上下文表示(OCR)来增强每个像素的表示。OCR是所有对象区域表示的加权聚合,根据像素和对象区域之间的关系计算权重。
所提出的OCR方法不同于传统的多尺度上下文方案。我们的OCR区分了相同对象类的上下文像素和不同对象类的上下文像素。多尺度的上下文方案,如ASPP[6]和PPM[80],只区分了具有不同空间位置的像素。图2提供了一个例子来说明我们的OCR上下文和多尺度上下文之间的差异。另一方面,我们的OCR方法也不同于以前的关系上下文方案[64,18,72,75,77]。我们的方法将上下文像素结构为对象区域,并利用像素和对象区域之间的关系。相比之下,之前的关系上下文方案只单独考虑上下文像素,并且只利用像素与上下文像素[18,72,77]之间的关系,或者只从像素中预测关系,而不考虑区域[75]。

我们在各种具有挑战性的语义分割基准上评估我们的方法。我们的方法优于多尺度上下文方案,如PSPNet、DeepLabv3,和最近的关系上下文方案,如DANet,而且效率也得到了提高。我们的方法在五个基准上取得了具有竞争力的性能:城市景观测试84.5%,ADE20Kval上45.66%,LIPval上56.65%,帕斯卡-上下文测试56.2%,COCOStuff测试40.5%。此外,我们将我们的方法扩展到-FPN[30],并验证我们的OCR在COCO-O光分割任务上的有效性,例如,–FPN+OCR在COCOval上达到44.2%。
2 Related Work
Multi-scale context. PSPNet[80]对金字塔池表示进行常规卷积,以捕获多尺度上下文。DeepLab系列[5,6]采用了具有不同稀释速率的平行扩张卷积(每个稀释速率捕获了不同尺度的上下文)。最近的工作[24,68,84,72]提出了各种扩展,例如,DenseASPP[68]密度扩展速率,以覆盖更大的尺度范围。其他一些研究[7,42,19]构建了编解码器结构,利用多分辨率特征作为多尺度上下文。

Relational context. DANet[18]、CFNet[77]和OCNet[72,71]通过聚合上下文像素的表示来增强每个像素的表示,其中上下文由所有像素组成。不同于全局上下文,这些工作考虑了基于自注意方案[64,61]的像素之间的关系(或相似性),并以相似性作为权重进行加权聚合。
双重注意及其相关工作[8,75,9,40,38,74,35,26]和ACFNet[75]将像素分组为一组区域,然后通过聚合区域表示并考虑使用像素表示预测的上下文关系来增加像素表示。
我们的方法是一种关系上下文方法,并与双重注意和ACFNet有关。区别在于区域的形成和像素-区域关系的计算。我们的方法学习的区域与监督的地面-真实分割。相比之下,以往除ACFNet之外的区域都是在没有监督的情况下形成的。另一方面,像素和区域之间的关系是通过同时考虑像素和区域表示来计算的,而以往研究中的区域的关系则仅仅是通过像素表示来计算的。
Coarse-to-fine segmentation. [17,20,34,59,28,33,85]开发了各种粗到细的分割方案,逐步细化分割图从粗到细。例如,[34]将粗分割映射视为一种额外的表示,并将其与原始图像或其他表示相结合,以计算一个精细的分割映射。
我们的方法在某种意义上也可以看作是一种从粗到细的方案。不同之处在于,我们使用粗糙的分割映射来生成上下文表示,而不是直接作为额外的表示使用。我们将我们的方法与补充材料中传统的从粗到细的方案进行了比较。
Region-wise segmentation. 目前有许多区域分割方法[1,2,23,22,65,50,2,60],它将像素组织成一组区域(通常是超像素),然后对每个区域进行分类,得到图像分割结果。我们的方法没有依赖对每个区域分类以进行分割,而是使用该区域学习更好的像素表示,从而得到更好的像素标签。
3 Approach
语义分割是一个为图像 I I I的每个像素 p i p_i pi分配一个标签 l i l_i li的问题,其中 l i l_i li是K个不同的类别标签
3.1 Background
Multi-scale context ASPP[5]模块通过执行多个具有不同膨胀速率[5,6,70]的并行膨胀卷积来捕获多尺度上下文信息:
y i d = ∑ p s = p i + d ∆ t K t d X s (1) y_i^d=\sum_{p_s=p_i+d∆_t}K_t^dX_s \tag{1} yid=ps=pi+d∆t∑KtdXs(1)
在 p s = p i + d ∆ t p_s=p_i+d∆_t ps=pi+d∆t中, p s p_s ps是膨胀率为d的膨胀卷积关于位置 p i p_i pi的第s个采样位置,例如 对于一个3x3的卷积:( { ∆ t = ( ∆ w , ∆ h ) ∣ ∆ w = − 1 , 0 , 1 , ∆ h = − 1 , 0 , 1 } \{∆_t=(∆_w,∆_h)|∆_w=-1,0,1, \ \ ∆_h=-1,0,1 \} {
∆t=(∆w,∆h)∣∆w=−1,0,1, ∆h=−1,0,1}) 。 x s x_s xs是在 p s p_s ps处的表示。 Y i d Y_i^d Yid是 p i p_i pi第d个膨胀卷积的输出表示。 K t d K^d_t Ktd是第d个膨胀卷积在t位置的核参数。输出的多尺度上下文表示是由并行扩展卷积输出的表示的连接。
基于膨胀卷积的多尺度上下文方案可以在不丢失分辨率的情况下捕获多尺度的上下文。PSPNet[80]中的金字塔池模块可以对不同尺度的表示进行规则卷积,也可以捕获多个尺度的上下文,但在大规模上下文中失去分辨率。
Relational context. 关系上下文方案[18,72,77]通过考虑以下关系来计算每个像素的上下文:
y i = p ( ∑ s ∈ I w i s δ ( x s ) ) (2) y_i=p(\sum_{s∈I}w_{is}δ(x_s)) \tag{2} yi=p(s∈I∑wisδ(xs))(2)
其中,I为图像中的像素集, w i s w_{is} wis是 w i w_{i} wi和 w s w_{s} ws之间的关系,只能从 x i x_i xi预测,也可以从 x i x_i xi和 x s x_s xs计算。 δ ( ⋅ ) δ(·) δ(⋅)和 ρ ( ⋅ ) ρ(·) ρ(⋅)是self-attention[61]中的两种不同的变换函数。全局上下文方案[46]是与 w i s = 1 ∣ I ∣ w_{is}=\frac{1}{|I|} wis=∣I∣1的关系上下文的一种特殊情况。
3.2 Formulation
像素 p i p_i pi的类标签 l i l_i li本质上是像素pi所在的对象的标签。基于此,我们提出了一种对象-上下文表示方法,通过利用相应的对象表示来描述每个像素。
所提出对象上下文表示方案(1)为图像I中的每一个像素都构造K个软目标区域,(2)聚合第k个区域中所有像素的表示为 f k f_k fk(3)通过聚合K个对象区域表示,并考虑其与所有对象区域的关系,来增加每个像素的表示:
y i = p ( ∑ k = 1 K w i k δ ( f k ) ) (3) y_i=p(\sum_{k=1}^Kw_{ik}δ(f_k)) \tag{3} yi=p(k=1∑Kwikδ(fk))(3)
其中, f k f_k fk为第k个对象区域的表示, w i k w_{ik} wik为第i个像素与第k个对象区域之间的关系。δ(·)和ρ(·)是转换函数。软对象区域: 我们将图像I划分为K个软对象区域{M1,M2,……,MK}。每个对象区域Mk对应于类k,并由一个二维映射(或粗分割映射)表示,其中每个条目表示对应的像素属于类k的程度。
我们从一个backbone(例如,ResNet或HRNet)的中间表示输出中计算K个对象区域。在训练过程中,我们利用交叉熵损失从地面真实分割中学习在监督下的目标区域生成器。
Object region representations. 我们将属于第k个对象区域的所有像素的度加权表示进行聚合,形成第k个对象区域表示:
f k = ∑ i ∈ I m ~ k i x i (4) \mathbf{f}_{k}=\sum_{i \in \mathcal{I}} \tilde{m}_{k i} \mathbf{x}_{i} \tag{4} fk=i∈I∑m~kixi(4)
这里, x i x_i xi表示像素 p i p_i pi。 m ~ k i \tilde{m}_{k i} m~ki是第k个对象区域的像素 p i p_i pi的归一化度。我们使用空间softmax来规范化每个对象区域 M k M_k Mk。
Object contextual representations. 我们计算每个像素和每个对象区域之间的关系如下:
w i k = e κ ( x i , f k ) ∑ j = 1 K e κ ( x i , f j ) (5) w_{i k}=\frac{e^{\kappa\left(\mathbf{x}_{i}, \mathbf{f}_{k}\right)}}{\sum_{j=1}^{K} e^{\kappa\left(\mathbf{x}_{i}, \mathbf{f}_{j}\right)}} \tag{5} wik=∑j=1Keκ(xi,fj)eκ(xi,fk)(5)
这里 κ ( x , f ) = ϕ ( x ) ⊤ ψ ( f ) \kappa(\mathbf{x}, \mathbf{f})=\phi(\mathbf{x})^{\top} \psi(\mathbf{f}) κ(x,f)=ϕ(x)⊤ψ(f) 是非归一化关系函数。 ϕ ( ⋅ ) \phi(\mathbf{·}) ϕ(⋅)和 ψ ( ⋅ ) \psi(\mathbf{·}) ψ(⋅)是两个由conv1x1->BN->ReLU实现的变化函数。这是受到自我注意[61]的启发,以获得更好的关系估计。
像素pi的对象上下文表示yi根据公式3计算。在这个方程中, δ ( ⋅ ) δ(·) δ(⋅)和 ρ ( ⋅ ) ρ(·) ρ(⋅)都是由conv1×1→BN→ReLU实现的转换函数,这遵循非局部网络[64]。
Augmented representations. 像素 p i p_i pi的最终表示被更新为两部分的聚合,第一部分为原始表示xi,第二部分为对象上下文表示 y i y_i yi:
z i = g ( [ x i ⊤ y i ⊤ ] ⊤ ) (6) \mathbf{z}_{i}=g\left(\left[\begin{array}{ll} \mathbf{x}_{i}^{\top} & \mathbf{y}_{i}^{\top} \end{array}\right]^{\top}\right) \tag{6} zi=g([xi⊤yi⊤]⊤)(6)
其中 g ( ⋅ ) g(·) g(⋅)是一个变换函数,用于融合原始表示和对象上下文表示,由conv1×1→BN→ReLU实现。我们的方法的整个pipeline如图3所示。
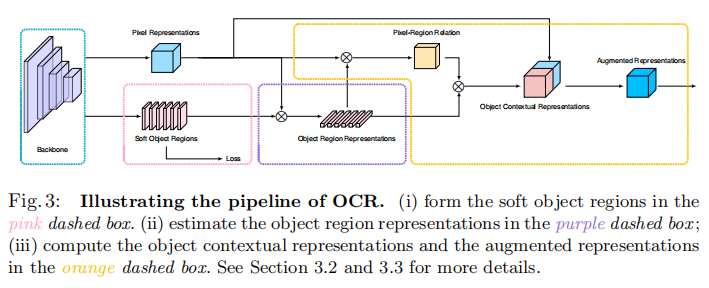
Comments:最近的一些研究,如双注意[8]和ACFNet[75],可以类似于公式3进行表述,但在某些方面与我们的方法不同。例如,双注意中形成的区域不对应到class,而ACFNet[75]中的关系仅使用对象区域表示从像素表示计算。
3.3 Segmentation Transformer: Rephrasing the OCR Method
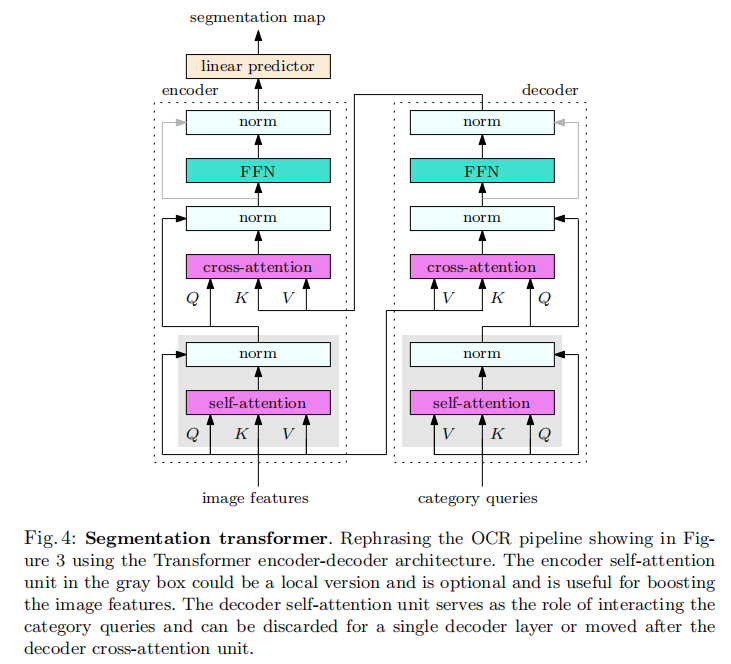
我们使用Transformer[62]重新定义了OCR pipeline,并在图4中说明了Transformer编码器-解码器架构。上述OCRpipeline包括三个步骤:软对象区域提取、对象区域表示计算和每个位置的对象-上下文表示计算,主要探索解码器和编码器交叉注意模块。
Attention 意力[62]使用比例点积计算。输入包含:一组查询集$N_q \ , \ \mathbf{Q} \in \mathbb{R}^{d \times N_{q}} ,一组关于 ,一组关于 ,一组关于N_{kv}$的key $\mathbf{K} \in \mathbb{R}^{d \times N_{kv}} ,和一组 ,和一组 ,和一组N_{kv}$的value, $\mathbf{V} \in \mathbb{R}^{d \times N_{kv}} 。注意权值 。注意权值 。注意权值a_{ij} 被计算为查询 被计算为查询 被计算为查询q_i 和键 和键 和键k_j$之间的点积的softmax归一化:
a i j = e 1 d q i ⊤ k j Z i where Z i = ∑ j = 1 N k v e 1 d q i ⊤ k j (7) a_{i j}=\frac{e^{\frac{1}{\sqrt{d}} \mathbf{q}_{i}^{\top} \mathbf{k}_{j}}}{Z_{i}} \text { where } Z_{i}=\sum_{j=1}^{N_{k v}} e^{\frac{1}{\sqrt{d}} \mathbf{q}_{i}^{\top} \mathbf{k}_{j}} \tag{7} aij=Zied1qi⊤kj where Zi=j=1∑Nkved1qi⊤kj(7)
每个查询 q i q_i qi的注意力输出是由注意力权重加权的值的聚合:
Attn ( q i , K , V ) = ∑ j = 1 N k v α i j v j (8) \operatorname{Attn}\left(\mathbf{q}_{i}, \mathbf{K}, \mathbf{V}\right)=\sum_{j=1}^{N_{k v}} \alpha_{i j} \mathbf{v}_{j} \tag{8} Attn(qi,K,V)=j=1∑Nkvαijvj(8)
Decoder cross-attention. 解码器交叉注意模块具有两个作用:软目标区域提取和目标区域表示计算。
键和值是图像特征(公式4中的 x i x_i xi)。这些查询是K个类别查询 ( q 1 、 q 2 、 … … , q K ) (q_1、q_2、……,q_K) (q1、q2、……,qK),每个查询对应一个类别。K个类别查询实际上上用于生成软对象区域 M 1 , M 2 , . . . , M K , M_1,M_2, . . . ,M_K, M1,M2,...,MK,,然后在空间上softmax归一化为公式4中的权值 m ~ \tilde{m} m~。计算 m ~ \tilde{m} m~与公式7中计算注意的权重 a i j a_{ij} aij的方式相同。公式4中的目标区域表示计算方式与公式8相同。
Encoder cross-attention. 编码器交叉注意模块(与后面的FFN)作为聚合对象区域表示的作用,如公式3所示。查询是每个位置的图像特征,键和值是解码器的输出。公式5计算权值的方式与公式7的注意计算方式相同,上下文聚合公式3与公式8相同,ρ(·)对应于FFN算子。
Connection to class embedding and class attention [14,58]. 类别查询接近于视觉Transformer(ViT)[14]中的类嵌入和图像Transformer(CaiT)[58]中的类注意嵌入。我们为每个类都有一个嵌入,而不是为所有类提供一个集成的嵌入。语义分割Transformer中的解码器cross-attention与CaiT中的类注意相似。
在类嵌入和图像特征上,编码器和解码器的体系结构在ViT上都接近于self-attention。如果两个cross-attention和两个self-attention同时进行(如图5所示),这就相当于一个单一的self-attention。在ImageNet训练前阶段学习类别查询的注意参数是很有趣的。
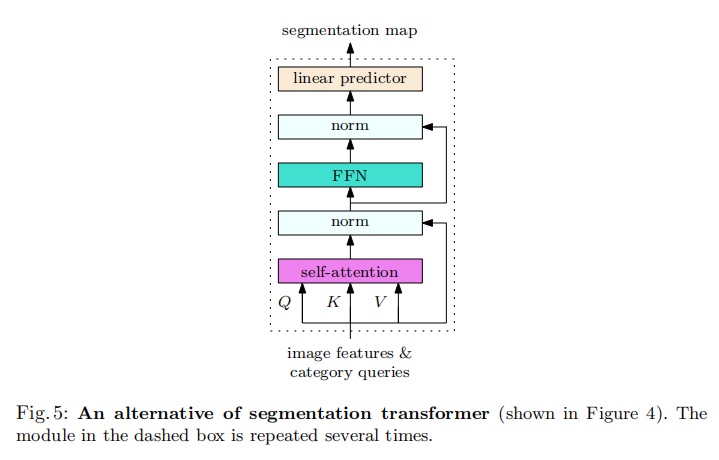
Connection to OCNet and interlaced self-attention [71]. OCNet[71]利用了self-attention(即,在图4中只包含编码器self-attention单元,而不包括编码器cross-attention单元和解码器)。self-attention单元由一个交错的self-attention单元加速,该单元由局部self-attention和全局self-attention组成,可以简化为在局部窗口上的集合特征上的self-attention。作为一种替代方案,图4中的类别查询可以被定期采样或自适应合并的图像特征所取代,而不是作为模型参数进行学习。
3.4 Architecture
Backbone. 我们使用扩张的ResNet-101[25](输出步幅8)或HRNetW48[54](输出步幅4)作为主干。对于扩展的ResNet-101,有两个表示形式输入到OCR模块。第一个表示来自Stage3用于预测粗分割(目标区域);另一个表示来自于Stage4,通过3×3卷积(512个输出通道),然后输入OCR模块。对于HRNet-W48,我们只使用最终的表示作为OCR模块的输入。
OCR module. 我们将上述方法的公式实现为OCR模块,如图3所示。我们使用一个线性函数(1×1卷积)来预测具有像素级交叉熵的监督的粗分割(软目标区域)损失。所有的变换函数,ψ(·)、φ(·)、δ(·)、ρ(·)和g(·),都被实现为 conv1×1→BN→ReLU,前三个输出256个通道,最后两个输出512个通道。我们使用线性函数从最终表示中预测最终分割,并在最终分割预测上应用像素级交叉熵损失。
3.5 Empirical Analysis
我们以扩张的ResNet-101作为Cityscapes val的基础,进行了实证分析实验。
Object region supervision. 我们研究了目标区域监督的影响,修改了我们的方法,通过消除对软对象区域(图3中粉色虚线框内)的监督(即损失),并在ResNet-101的Stage3添加了另一个辅助损失。我们保持所有其他设置相同,并在表1最左边的两列中报告结果。我们可以看到,对形成目标区域的监督是对性能至关重要的。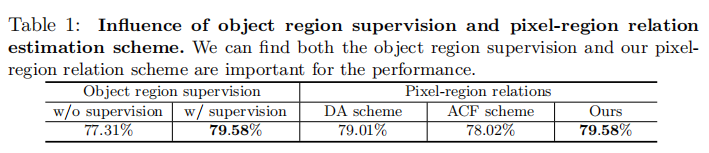
Pixel-region relations. 将我们的方法与其他两种不使用区域表示来估计像素-区域关系的机制进行了比较:(i)双注意[8]使用像素表示来预测关系;(ii)ACFNet[75]直接使用一个中间分割图来表示关系。我们使用DA方案和ACF方案来表示上述两种机制。我们自己实现了这两种方法,并且只使用扩展的ResNet-101作为主干,而没有使用多尺度上下文(ACFNet的结果通过使用ASPP[75]得到改进)
表1中的比较表明,我们的方法获得了优越的性能。原因是我们利用像素表示和区域表示来计算关系。区域表示能够在特定的图像中描述对象,因此对于特定的图像的关系比仅使用像素表示更准确。
Ground-truth OCR 我们研究分割性能使用基础真实分割形成对象区域和像素-区域关系,称为GT-OCR,以证明我们的动机。(i)使用GT形成对象区域:如果GT标签 l i ≡ k l_i≡k li≡k和 m k i = 0 m_{ki}=0 mki=0,则设置像素i的置信度属于第k对象区域的 m k i = 1 m_{ki}=1 mki=1。(ii)使用GT计算像素-区域关系:如果GT标签 l i ≡ k , w i k = 0 l_i≡k \ , \ w_{ik} = 0 li≡k , wik=0,则设置像素-区域关系。我们在图1中说明了GT-OCR在四种不同基准上的详细结果。
4 Experiments: Semantic Segmentation
4.1 Datasets
Cityscapes 城市景观数据集[11]是负责了解城市场景。总共有30个类,只有19个类用于解析计算。该数据集包含5K个高质量像素级精细注释图像和20K粗注释图像。精细注释的5K图像被分为2975/500/1525张图像,用于训练、验证和测试。
ADE20K. ADE20K数据集[82]用于ImageNet场景解析挑战2016。有150个类和不同的场景和1038个图像级标签。将数据集划分为20K/2K/3K图像进行训练、验证和测试。
LIP LIP数据集[21]用于2016年的LIP挑战,用于单个人类解析任务。大约有50K个图像,有20个类(19个语义人类部分类和1个背景类)。训练、验证和测试集分别由30K、10K、10K的图像组成。
PASCAL-Context. PASCAL-Context数据集[49]是一个具有挑战性的场景解析数据集,它包含59个语义类和1个背景类。训练集和测试集分别由4998张图像和5105张图像组成。
COCO-Stuff. COCO-Stuff数据集[3]是一个具有挑战性的场景解析数据集,它包含171个语义类。训练集和测试集分别由9K图像和1K图像组成。
4.2 Implementation Details
Training setting. 我们使用在ImageNet上预先训练的模型和OCR模块随机初始化骨干。我们使用因子 ( 1 − ( i t e r i t e r max ) 0.9 ) \left(1-\left(\frac{i t e r}{i t e r_{\max }}\right)^{0.9}\right) (1−(itermaxiter)0.9)执行多项式学习率策略,最终损失的权重为1,用于监督目标区域估计(或辅助损失)的损失的权重为0.4。我们使用InPlace-ABNsync[52]来跨多个gpu同步BN的平均值和标准偏差。对于数据增强,我们在水平上执行随机翻转,在[0.5,2]范围内执行随机缩放,在[−10,10]范围内执行随机亮度抖动。我们对于对比实验PPM, ASPP,也使用相同的设置,以确保公平。我们遵循之前的工作[6,76,80]来建立基准数据集的训练。
Cityscapes 我们将初始学习率设置为0.01,重量衰减设置为0.0005,crop大小默认设置为769×769,批处理大小默认设置为8。对于在val/test集上评估的实验,我们分别将train/train+val上的训练迭代设置为40+/100+。对于实验增强额外的数据:(i) w/coarse,,我们首先训练模型 train + val为100K迭代初始学习率为0.01,然后我们微调模型粗设置50K迭代和继续微调我们的模型train+val进行20K迭代,使用相同的初始学习率0.001。(2) w/coarse+Mapillary[50],我们首先预先在Mapillary train数据上训练模型进行500K迭代,批大小为16和初始学习率0.01(达到50.8%),然后我们在Cityscapes上微调模型,顺序为:train + val (100K iterations)
→ coarse (50K iterations) → train + val (20K iterations),我们设置初始学习率为0.001和批大小为8在上述三个微调阶段的Cityscapes数据中。
ADE20K 我们将初始学习率设置为0.02,权重衰减设置为0.0001,crop大小设置为520×520,批处理大小设置为16,如果没有指定,训练迭代设置为150K。
LIP 我们将初始学习率设置为0.007,权重衰减设置为0.0005,crop大小设置为473×473,批处理大小设置为32,如果没有指定,训练迭代次数设置为100K。
PASCAL-Context 我们将初始学习率设置为0.001,权重衰减设置为0.0001,crop大小设置为520×520,批量大小设置为16,如果没有指定,训练迭代次数设置为30K。
COCO-Stuff 我们将初始学习率设置为0.001,权重衰减设置为0.0001,crop大小设置为520×520,批量大小设置为16,如果没有指定,训练迭代次数设置为60K。
4.3 Comparison with Existing Context Schemes
我们使用扩展的ResNet-101作为骨干进行实验,并使用相同的训练/测试设置,以确保公平性。
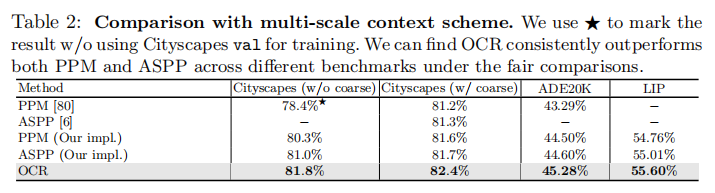
Multi-scale contexts. 我们在表2中的Cityscapes test、AME20K val和LIP val三个基准测试上,将OCR与PPM[80]和ASPP[6]等多尺度上下文方案进行了比较。我们复现的PPM/ASPP在[80,6]中的表现优于原始论文的精度。从表2中可以看出,我们的OCR在很大程度上优于两种多尺度上下文方案。例如,在四种比较中,OCR比PPM(ASPP)的绝对增益分别为1.5%(0.8%)、0.8%(0.7%)、0.78%(0.68%)、0.84%(0.5%)。据我们所知,考虑到基线(带有扩展的ResNet-101)已经很强,而且我们的OCR的复杂性要小得多,这些改进已经很重要了。
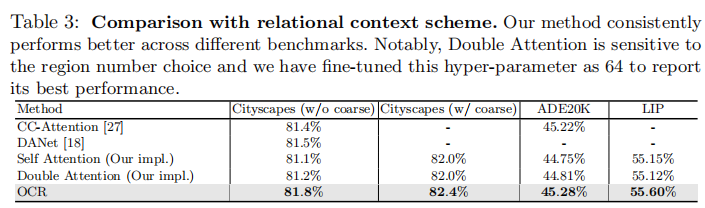
Relational contexts. 我们比较了我们的OCR与各种关系上下文方案,包括Self-Attention[61,64],Criss-Cross attention27,DANet[18]和 Double Attention[8]在相同的三个基准上,包括Cityscapes test, ADE20K val 和 LIP val。对于复现的Double Attention,我们微调了区域的数量(因为它对超参数的选择非常敏感),并且我们选择了性能最好的64个。更详细的分析和比较在补充材料中有所说明。从表3中的结果可以看出,在公平的比较下,我们的OCR优于这些关系上下文方案。值得注意的是,我们的OCR的复杂性比大多数其他方法都要小得多。
Complexity. 我们比较了OCR的效率与多尺度上下文方案和关系上下文方案的效率。我们测量了由上下文模块引入的增加的参数、GPU内存、计算复杂度(通过FLOPs的数量来衡量)和推理时间,而没有计算来自主干的复杂度。表4中的比较显示了所提出的OCR方案的优越性。
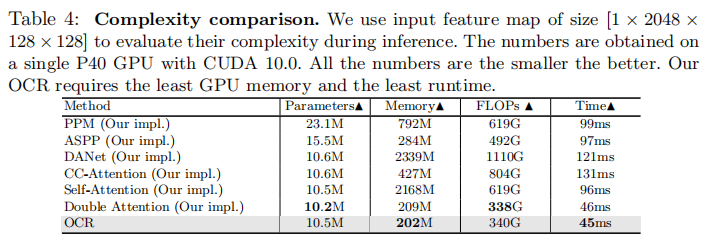
Parameters: 与多尺度上下文方案相比,大多数关系上下文方案需要更少的参数。例如,我们的OCR分别只需要PPM和ASPP的1/2和2/3的参数
Memory: 与其他方法(例如,DANet,PPM)相比,我们的OCR和Double Attention所需要的GPU内存要少得多。例如,我们的GPU内存消耗分别是PPM、DANet、CC-Attention和Self-Attention的内存消耗的1/4、1/10、1/2、1/10。
FLOPs: 我们的OCR只需要 PPM, ASPP, DANet, CC-Attention 和 Self-Attention的1/2, 7/10, 3/10, 2/5 和 1/2
Running time: OCR的运行时间非常小:只有PPM、ASPP、DANet、CC-Attention 和 Self-Attention的1/2、1/2、1/3、1/3和1/2。
一般来说,如果我们考虑性能、内存复杂性、FLOPs和运行时间之间的平衡,那么我们的OCR将是一个更好的选择。
4.4 Comparison with the State-of-the-Art
考虑到不同的方法在不同的基线上进行改进以达到最佳性能,我们根据其应用的基线将现有的工作分为两组:(i)简单基线:stride为8的扩张ResNet-101;(ii)高级基线:PSPNet,deepLabv3,多网格(MG),编解码器结构,通过步幅获得更高的分辨率输出,如WideResNet-38, Xception-71 and HRNet.
为了与两组进行公平的比较,我们采用简单的基线(stride为8的扩张ResNet-101)和高级基线(HRNet-W48,stride=4)进行OCR。值得注意的是,我们对HRNet-W48的改进(超过ResNet-101)的改进与其他基于高级基线方法的工作的收益相当。例如,在Cityscapes测试中,DGCNet[78]在多网格中获得0.7%,而OCR在更强的主干下获得0.6%。我们在表5中总结了所有的结果,并分别说明了每个基准测试上的比较细节如下。
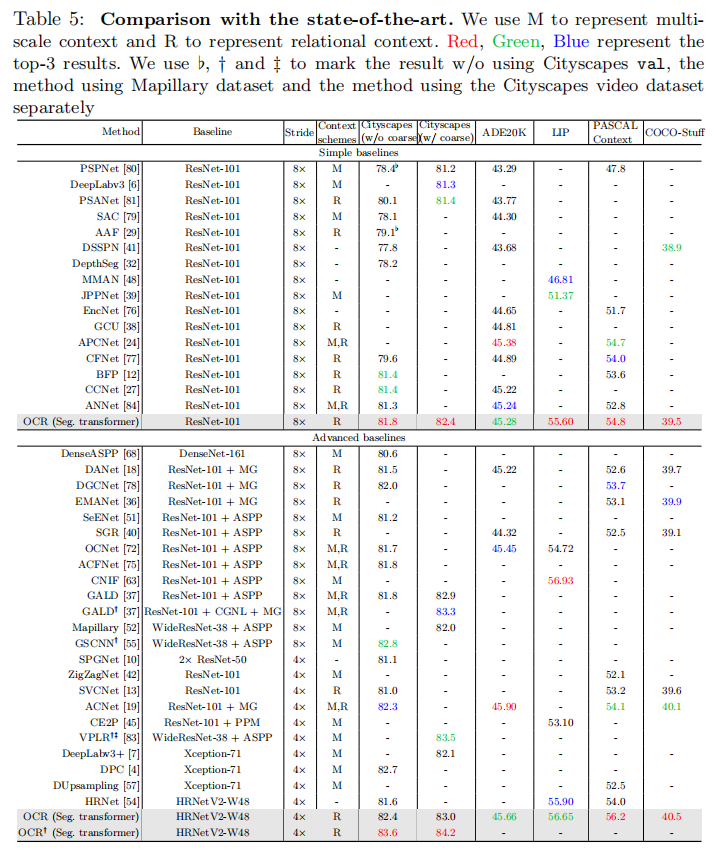
Cityscapes 与基于不使用粗糙数据的城市景观测试的简单基线的方法相比,我们的方法获得了81.8%的最佳性能,这已经可以与一些基于高级基线的方法相比较,如DANet、ACFNet。我们的方法通过利用粗注释的图像进行训练,获得了82.4%的更好的性能。
为了与基于高级基线的方法进行比较,我们在HRNet-W48上执行OCR,并在乳头数据集[50]上对我们的模型进行预训练。我们的方法在城市景观测试中达到了84.2%。我们进一步应用一种新的后处理方案SegFix[73]对边界质量进行细化,使↑提高了0.3%。我们最终提交的“HRNet+OCR+SegFix”达到了84.5%,在我们提交时在城市景观排行榜上排名第一。事实上,我们分别在HRNet-W48上执行PPM和ASPP,并通过经验发现,直接应用PPM或ASPP并不能提高性能,甚至降低性能,而我们的OCR可以持续提高性能。
值得注意的是,最近的工作[56]通过结合我们的“HRNet+OCR”和一种新的层次多尺度注意机制,在城市景观排行榜上设置了85.4%的最先进的表现。
ADE20K 从表5中可以看出,与之前的大多数基于简单基线和高级基线的方法相比,我们的OCR实现了具有竞争力的性能(45.28%和45.66%)。例如,ACFNet[24]同时利用多尺度上下文和关系上下文来实现更高的性能。最近的ACNet[19]通过结合更丰富的本地和全局上下文,实现了最好的性能。
LIP 基于简单的基线,我们的方法在LIP val上达到了55.60%的最佳性能。进一步应用更强的主干HRNetV2-W48,将性能提升到 56.65%。这将优于以前的方法。最近的工作CNIF[63]通过注入人体部位的层次结构知识,获得了最好的性能(56.93%)。我们的方法可能受益于这种层次结构知识。所有的结果都是仅基于翻转测试,而没有基于多尺度测试。
PASCAL-Context 我们在[54]之后评估了59个类别的表现。可以看出,我们的方法优于以前基于简单基线的最佳方法和以前基于高级基线的最佳方法。HRNet-W48+OCR方法的最佳性能为56.2%,显著优于第二名,如ACPNet(54.7%)和ACNet(54.1%)。
COCO-Stuff 可以看出,我们的方法取得了最好的性能,基于ResNet-101的39.5%,基于HRNetV2-48为40.5%。
Qualitative Results 由于页面有限,我们在补充材料中说明定性结果
5 Experiments: Panoptic Segmentation
为了验证该方法的泛化能力,我们将OCR方案应用于更具有挑战性的全景分割任务[31],该任务统一了实例分割任务和语义分割任务。
Dataset 我们选择COCO数据集[43]来研究我们的方法在全景分割上的有效性。我们遵循之前的工作[30],使用所有2017年的COCO图像,有80类和53个原始类注释。
Training Details. 我们遵循来自Detectron2[66]默认的“COCO全景分割基线(3倍学习率)设置。复现的全景FPN比论文[30]中的原始数字性能更高(Panoptic FPN w/ ResNet-50, PQ: 39.2% /Panoptic FPN w/ ResNet-101, PQ: 40.3%),我们选择更高的复现结果作为我们的基线。
在我们的实现中,我们使用来自语义分割头的原始预测(在Panoptic-FPN中)来计算软对象区域,然后我们使用OCR头来预测一个细化的语义分割图。我们将原始语义分割头和OCR头的损失权重设为0.25。所有其他的训练设置都保持相同,以便进行公平的比较。我们直接使用相同的OCR实现(用于语义分割任务),而没有任何调整。
Results 在表6中,我们可以看到OCR将Panoptic-FPN(ResNet-101)的PQ性能从43.0%提高到44.2%,其中主要的改进来自于在mIoU和PQSt测量的材料区域上的更好的分割质量。具体来说,我们的OCR分别将Panoptic-FPN(ResNet-101)的mIoU和PQSt提高了1.0%和2.3%。总的来说,与最近的各种方法[67,44,69]相比,“全景-FPN+OCR”的性能非常有竞争力。我们还报告了使用PPM和ASPP的Panoptic-FPN的结果,以说明我们的OCR的优势(在补充材料中)。

6 Conclusions
在这项工作中,我们提出了一种语义分割的对象-上下文表示方法。成功的主要原因是,一个像素的标签是该像素所在的对象的标签,并且通过用对应的对象区域表示来表征每个像素来加强像素表示。我们的经验表明,我们的方法对各种基准测试带来了一致的改进。