文章目录
1. 相关资源
- 原文地址: Gated-SCNN : Gated Shape CNNs for Semantic Segmentation [2019] [ICCV]
- 源码地址: https://nv-tlabs.github.io/GSCNN/
2. 问题描述
论文中提到,语义分割主要遇到的问题是低分辨率和语义信息不足等。许多研究者也提出了融合不同层的语义信息,以及利用多尺度分辨率的上采样模块等,来缓解这些问题。
语义分割在细小的目标分割上还存在一些问题。这个问题可以从网络结构的内在出发,单一网络的结构融合了非常多的不同类型的信息:颜色、形状以及纹理信息。这些信息被融合在一起处理,可能会导致对识别重要的信息不够的突出。
3. 创新点
提出了一种用于语义分割的Two-Stream结构CNN(GS-CNN)。GS-CNN主要加入了一个单独的分支用来学习边缘信息,称之为形状流。这一结构改进使得分割模型能够更好的预测对象的边缘信息,显著的提升了小物体和细物体的分割效果。
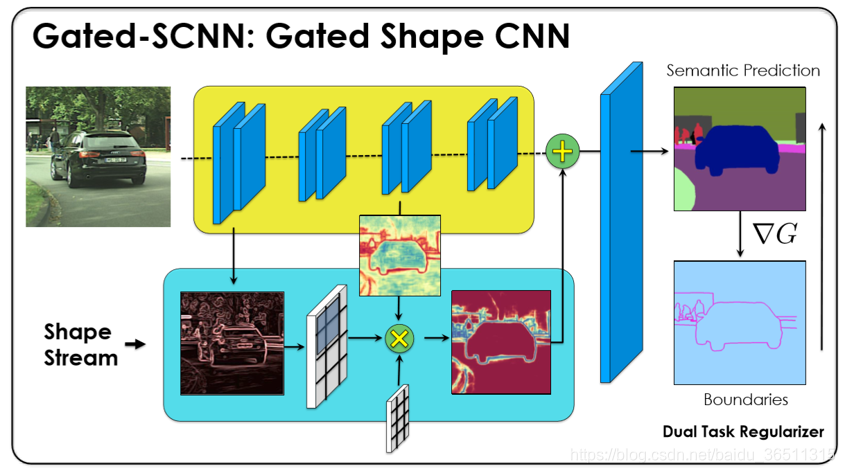
4. 整体架构
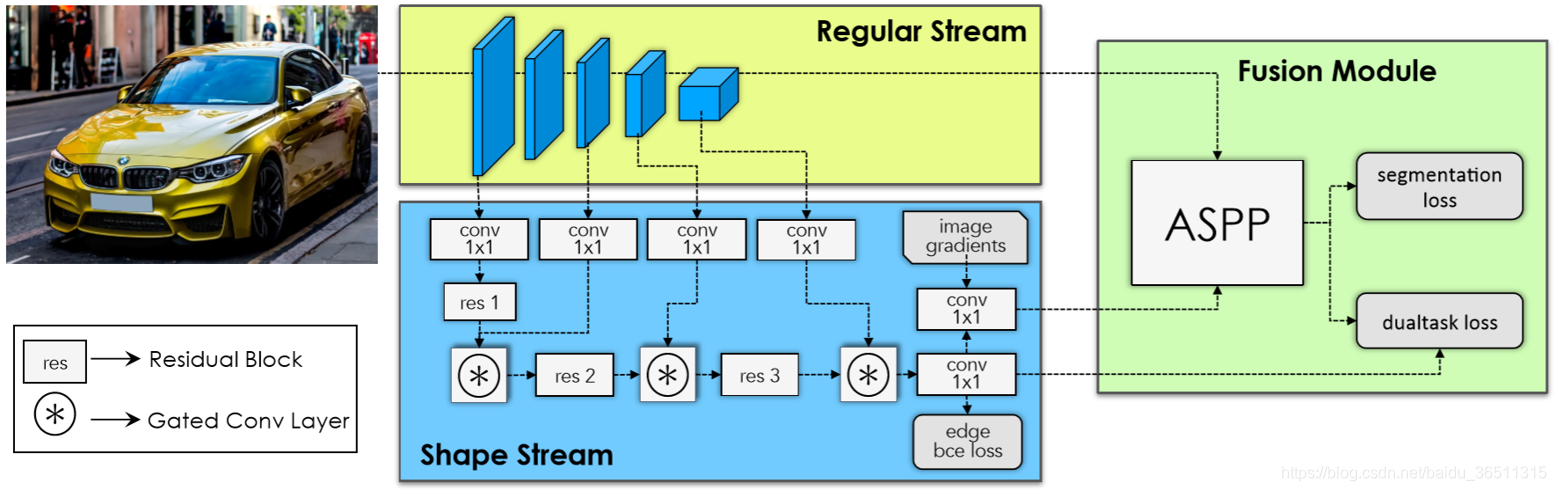
为了方便后续叙述,按照文章和源码对图片进行了一些标注。
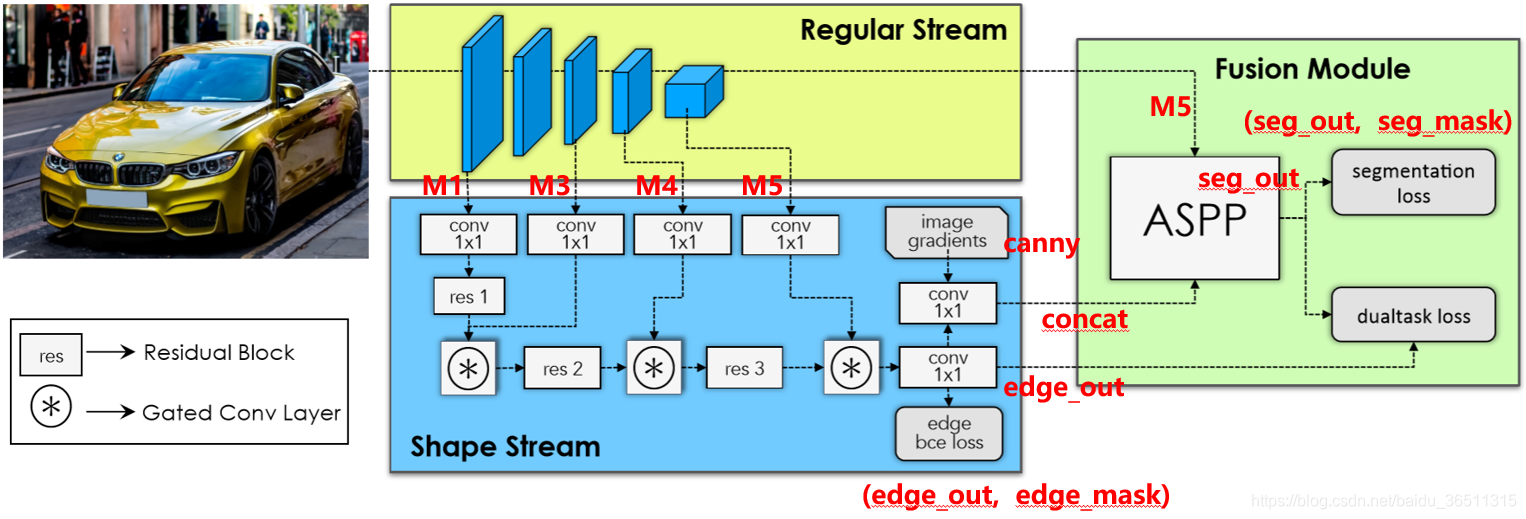
网络结构总体上分为三个部分:常规流(Regular Stream)、形状流(Shape Stream)、融合模块(Fusion Module)。
- 常规流:可选用VGG或者ResNet作为backbone。
- 形状流:两路输入,M1作为一路输入,后续M3、M4、M5陆续作为二路输入。门控卷积层GCL用来生成权重图。图中的
image gradients表示用canny算子提取的图像边缘信息,edge bce loss用来监督边缘信息的提取,强迫形状流只学习边缘信息。最后把提取的边缘信息进行融合并汇入融合模块。 - 融合模块:总共融合四路信息。
4.1 Gated Convolutional Layer
文章对这部分的介绍只有两个公式和一些简单说明,笔者根据论文描述和源代码绘制了GCL层的完整结构图如下:

从GCL的结构可以看出,它其实就是Attention机制 + 残差结构的组合。
4.1.1 GCL的可视化效果
作者对GCL层提取的特征进行了可视化,可以看到,提取的几乎是边缘信息,效果还是很明显的。

4.2 Fusion Module
同样,结合源码绘制了融合模块的结构图,如下:
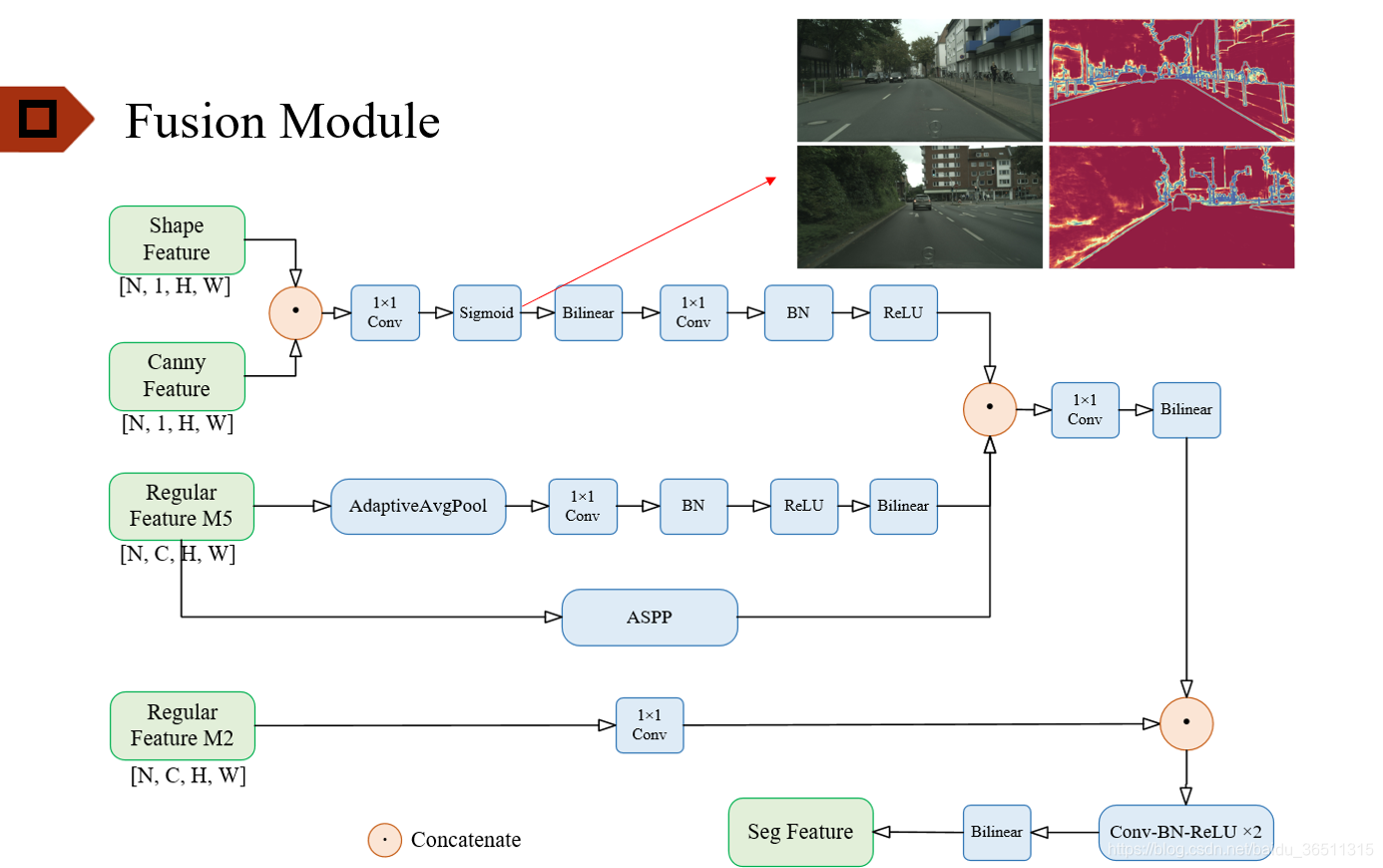
可以看出,作者对网络结构进行了精心的设计。
5. 损失函数
下图列出了作者在文中所提到的所有损失函数。

本文的损失函数总共由4部分组成,其中又分为2个小部分,Joint Multi-Task Learning 和 DualTaskRegularizer。
Joint Multi-Task Learning:边界损失和语义分割损失。边界损失用来监督网络对边缘信息的学习,通过反向传播更新常规流和形状流中的参数;语义分割损失用来监督网络最终的分割结果,通过反向传播更新整个网络中(包括融合模块)的参数。Dual Task Regularizer:正则化。这一部分还是用来监督网络多边缘信息的学习,不过代码实现部分比较繁琐,比较有针对性,对这一小部分还没有完全理解。
6. 实验结果
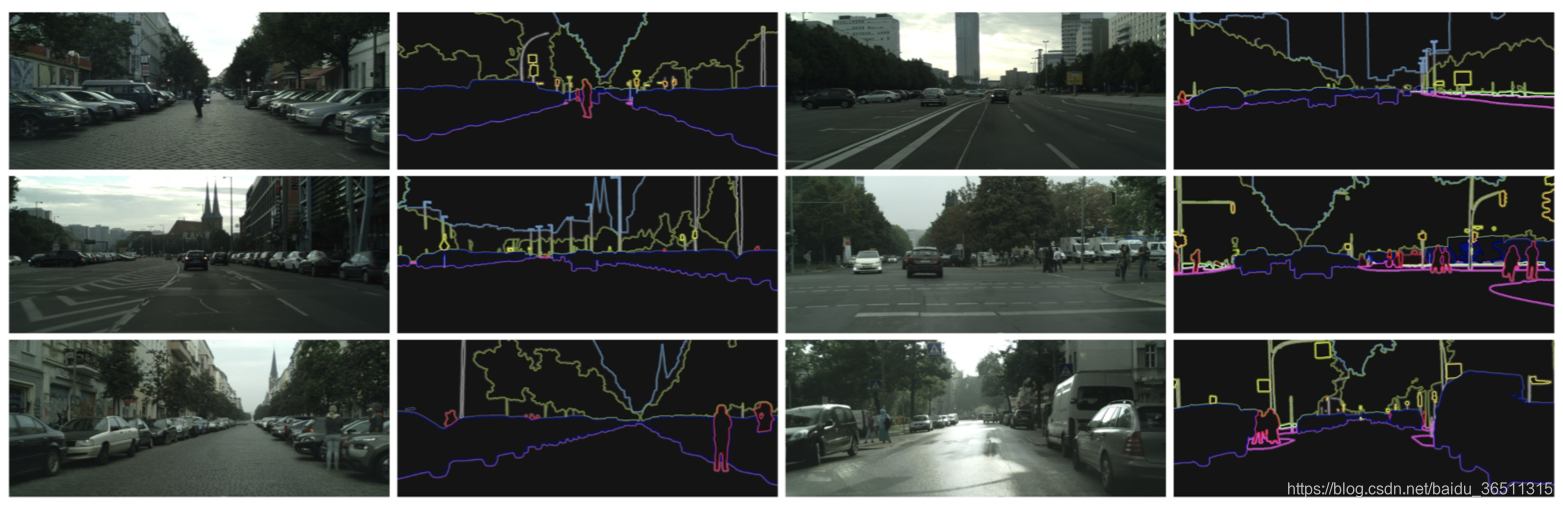

7. 对比实验结果


从表中数据可以看到网络对细小物体的分割效果有显著提升,尤其是杆,信号标志、信号灯、摩托车。

