变分自动编码器(VAE)是一种有方向的图形生成模型,已经取得了很好的效果,是目前生成模型的最先进方法之一。它假设数据是由一些随机过程,涉及一个未被注意的连续随机变量z假设生成的z是先验分布P_θ(z)和条件生成数据分布P_θ(X | z),其中X表示这些数据。z有时被称为数据X的隐藏表示。
像任何其他自动编码器架构一样,它有一个编码器和一个解码器。编码器部分试图学习q_φ(z | x),相当于学习数据的隐藏表示x或者x编码到隐藏的(概率编码器)表示。解码器部分试图学习P_θ(X | z)解码隐藏表示输入空间。图形化模型可以表示为下图。

对模型进行训练,使目标函数最小化
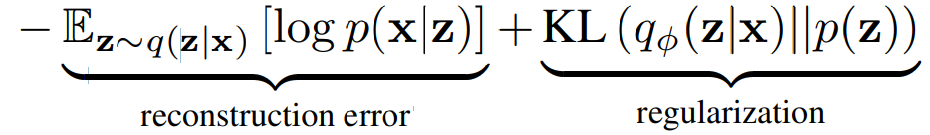
这种损失的第一项是重建错误或数据点的预期负对数可能性。期望是关于编码器的分布在表示通过采取一些样本。这个术语鼓励解码器在使用来自潜在分布的样本时学会重构数据。较大的错误表示解码器无法重构数据。
第二项是Kullback-Leibler编码器之间的分布q_φ(z | x)和p (z)。这个散度度量了在使用q表示z上的先验时损失了多少信息,并鼓励其值为高斯分布。
在生成过程中,来自N(0,1)的样本被简单地输入解码器。训练和生成过程可以表示为以下
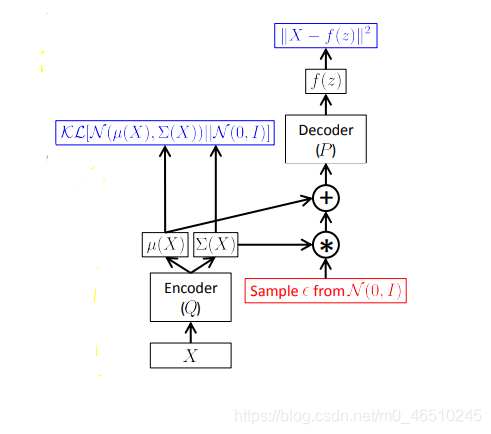
一种训练时变分自编码器实现为前馈神经网络,其中P(X|z)为高斯分布。红色表示不可微的采样操作。蓝色表示损失计算

测试时变分的“自动编码器”,它允许我们生成新的样本。“编码器”路径被简单地丢弃。
对VAE进行如此简要的描述,其原因在于,VAE并不是本文的主要关注对象,而是与本文的主要主题紧密相关的。
用VAE生成数据的一个问题是,我们对生成的数据类型没有任何控制。例如,如果我们用MNIST数据集训练VAE,并尝试通过向解码器输入Z ~ N(0,1)来生成图像,它也会产生不同的随机数字。如果我们训练好,图像会很好,但我们将无法控制它会产生什么数字。例如,你不能告诉VAE生成一个数字“2”的图像。
为此,我们需要对VAE的体系结构进行一些修改。假设给定一个输入Y(图像的标签),我们希望生成模型生成输出X(图像)。所以,VAE的过程将被修改为以下:鉴于观察y, z是来自先验分布P_θ(z | y)和输出分布P_θ产生的x (x | y, z)。请注意,对于简单的VAE,之前是P_θ(z)和输出是由P_θ(x | z)。

VAE中的可视化表示任务
这里编码器部分试图学习q_φ(z | x, y),相当于学习隐藏的代表数据或编码x到y条件。解码器部分试图隐藏表示学习P_θ(x | z, y)解码隐藏表示输入空间条件的y。图形化模型可以表示为如下图所示。

条件VAE (Conditional VAE)的神经网络结构可以表示为如下图。
X是像。Y是图像的标签,它可以用一个离散向量表示。

CVAE的一个keras实现:https://github.com/nnormandin/Conditional_VAE/blob/master/Conditional_VAE.ipynb
作者:Md Ashiqur Rahman