正文
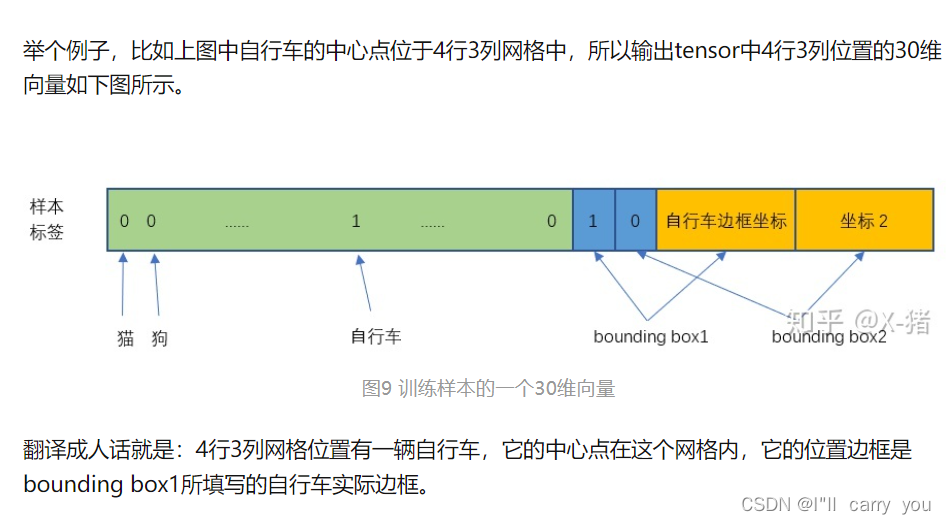
理解yolo这句话,如下,是对训练阶段 标注数据label说的,
来源于参考资料1
另外论文中经常提到responsible。比如:Our system divides the input image into an S*S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. 这个 responsible 有点让人疑惑,对预测"负责"是啥意思。其实没啥特别意思,就是一个Object只由一个grid来进行预测,不要多个grid都抢着预测同一个Object。更具体一点说,就是在设置训练样本的时候,样本中的每个Object归属到且仅归属到一个grid,即便有时Object跨越了几个grid,也仅指定其中一个。具体就是计算出该Object的bounding box的中心位置,这个中心位置落在哪个grid,该grid对应的输出向量中该对象的类别概率是1(该gird负责预测该对象),所有其它grid对该Object的预测概率设为0(不负责预测该对象)。还有:YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. 同样,虽然一个grid中会产生2个bounding box,但我们会选择其中一个作为预测结果,另一个会被忽略。下面构造训练样本的部分会看的更清楚。

理解 利用多尺度特征进行对象检测,
来源于参考资料3评论
感受野越大不是检测的物体越小吗
回答:这里的感受野是指一个像素所对应的在原图上的面积,感受野越大的话就是特征图越小,比如这里的 13 ∗ 13 13*13 13∗13感受野就比 26 ∗ 26 26*26 26∗26的大, 13 ∗ 13 13*13 13∗13所能检测到的物体信息看到是比 26 ∗ 26 26*26 26∗26的少的,所以小物体在 13 ∗ 13 13*13 13∗13的特征图上更容易被忽视,这样来说,感受野越大的话检测的物体应该越大。
来源于参考资料3评论
您好,问一个比较基础的问题。就是对于4+1+80这个向的解释,我可以理解。但是在实际网络训练中,是怎样保证这个向量的前四个值预测的就是坐标呢,中间那个值预测的就是,是否包含目标,后八十个预测的就是每一类的概率呢?
回答:网络的输出就是这样排序的,网络自然就趋向于这样收敛呗