Redmon, Joseph, et al. “You Only Look Once: Unified, Real-Time Object Detection.” (2015):779-788.
概述
目标检测中的RCNN系列1算法遵循2-stage的流程:首先找出一系列(预先设定好的)候选区域,而后对这些候选区域进行分类以及位置修正。
YOLO则开启了1-stage的流派:直接用一个深度网络,回归出目标的位置和归类。
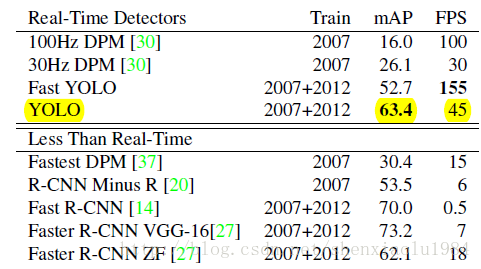
基础YOLO检测器的速度能够达到45 fps,更快的Fast YOLO则能够达到惊人的155 fps。
网络结构
YOLO将输入图像划分为
这种近似显然影响YOLO对于密集小物体的召回率,但胜在速度很快。
对于每个网格,预测以下变量:
- 【分类】该网格内目标属于每个类别的概率
p - 【定位】
B 个bounding box,描述目标的位置x,y 和尺寸w,h - 【定位】
B 个confidence,描述相应bounding box是目标的置信度C
对于较大,或者处于网格交界处的目标,可能需要由多个bounding box组合而成。这也是为bounding box预测置信度的原因。
每个bounding box可以专注于一种长宽比或者一类目标。
对于PASCAL VOC任务,类别数=20。设定

输入为448*448彩色图像,比RCNN系列增大一倍。
其中蓝色的卷积网络包含24或9个卷积层,基本遵循googLeNet2的设计,降采样为
两个绿色的全连层从特征图回归出每个网格的30个预测。
训练
标定与预测
如果目标的中心在一个网格内部,称为“目标在网格内”。
这里暗含假设:每个网格最多含有一个目标。论文中没有明确指出如何处理多个目标的情况,有待结合源码查看。
真实数据记为:
-
xi^,yi^ :网格i 中目标的左上角位置 -
wi^,hi^ :网格i 中目标的尺寸 -
Cij^ :网格i 的第j 个bounding box和目标的IOU -
pi^ :网格i 的1-hot编码分类概率
对于每一个网格
-
xij,yij :bounding box左上角位置 -
wij,hij :bounding box尺寸
-
Cij :bounding box属于目标的概率
以及一个分类结果(目标是哪一类):
-
pi :长度为类别数的向量
代价
代价包含如下三个方面3。
【定位代价】考察每个含有目标的网格中置信度最高的的bounding box:应该与目标位置近似。
其中,如果网格
在考察
举例
情况1:wij =100,wij^ =101
情况2:wij =1,wij^ =2
显然,情况1的误差应该产生较小代价
【检测代价】考察每个网格中置信度最高的预测结果:如果网格含有目标,应等于目标与bounding box的IOU;如果网格不含目标,应为0。
实际图片中,背景面积远远大于前景,负样本远多于正样本。需要用权重来平衡:
其中,如果网格
如果不处理不平衡样本问题,网络可能选择让置信度永远为0。
【分类代价】考察每个含有目标的网格
本文中,
流程
| 阶段 | 网络 | 数据集 | 训练时长/epoch | 学习率 |
|---|---|---|---|---|
| 预训练 | 20 conv+pooling+fc | ImageNet 1000类 224*224 | 一周 | |
| 阶段1 | 20 conv+4 conv+2 fc | PASCAL VOC 20类 448*448 | 若干 |
|
| 阶段2 | 20 conv+4 conv+2 fc | PASCAL VOC 20类 448*448 | 75 |
|
| 阶段3 | 20 conv+4 conv+2 fc | PASCAL VOC 20类 448*448 | 30 |
|
| 阶段4 | 20 conv+4 conv+2 fc | PASCAL VOC 20类 448*448 | 30 |
|
实验
性能
作为实时检测器,YOLO在PASCAL VOC上取得了不错的性能
错误分析
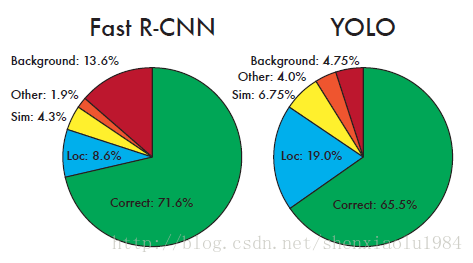
将YOLO与Fast-RCNN的分类结果进行比较,得到两个十分有启发性的结论:
| 错误 | 解释 | 比较 | 原因 |
|---|---|---|---|
| 虚警(红) | 将背景误判为目标 | YOLO更佳 | YOLO在训练时,将整张图像送入网络,上下文信息更丰富 |
| 定位(蓝) | 类别正确,位置偏差 | YOLO更差 | YOLO的候选框受网格限制 |
推广
另一个有趣的实验,是将真实照片(PASCAL-VOC)上训练的检测器,在绘画作品(Picasso,People-Art)上进行测试。得益于“整张图片训练”带来的高层次理解,YOLO的表现非常出色。
- 可参看这三篇博客:RCNN, Fast-RCNN, Faster-RCNN ↩
- Szegedy, Christian, et al. “Going deeper with convolutions.” Computer Vision and Pattern Recognition IEEE, 2015:1-9. ↩
- 论文关于代价部分所言不清。这里主要根据这个stackexchange上的讨论。 ↩