目录介绍:
https://blog.csdn.net/qq_33485434/article/details/80907040 yolo参数介绍
https://pjreddie.com/darknet/yolo/ 官方介绍
根目录:keras-yolo3(随意建立)
下层目录:
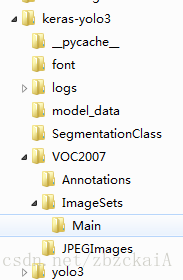
logs用于存放训练后的模型,model_data用于存放标签类别数据,Segmentationclass用于生成测试生成的图片,VOC2007用于存放训练数据,JPEGimages用于存放原始图片,Annotations 用于存放生成的xml数据(链接:https://pan.baidu.com/s/1EhVeWBiS8YKBD0552g3DLg
提取码:4zhe),ImageSets用于存放生成的训练文件目录:
注:keras-yolo3中本来没有voc2007文件,方便起见加进去的,keras-yolo3 git 路径[email protected]:qqwweee/keras-yolo3.git
操作步骤:
一.把要训练的图片都复制到JPEGImages里面
二.利用网盘下载的文件labelmodel 对照片进行手动打标签生成xml文件
三.利用下面的代码生成训练测试的图片标签并保存在traintest等文件
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()四.修改voc_annotation.py文件,把class中的class 修改为你需要的分类标签,classes= ['bee','laby..']
五.修改参数文件yolo3.cfg
IDE里直接打开cfg文件,ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方,睁开你的卡姿兰大眼睛,3个yolo!!
每个地方都要改3处,filters:3*(5+len(classes));
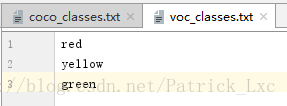
classes: len(classes) = 3,这里以红、黄、蓝三个颜色为例
random:原来是1,显存小改为0
六.yolo3.cfg转换weight文件
这个文件是用于转换官网下载的.weights文件用的。训练自己的网络并不需要去管他。详见readme
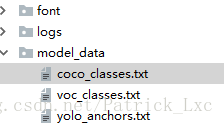
https://pjreddie.com/media/files/yolov3.weights第七步:修改model_data下的文件,放入你的类别,coco,voc这两个文件都需要修改。
像这样:
第八步:修改代码,准备训练。代码以yolo3模型为目标,tiny_yolo不考虑。
1、会加载预先对coco数据集已经训练完成的yolo3权重文件,

2、冻结了开始到最后倒数第N层(源代码为N=-2),、

,所以,可以冻结的少一点让他模型可以多训练一点属于自身的东西(没有测试过还是利用给的从开始到倒数第N层)直接运行,loss达到10几的时候效果就可以了
九.预测图片。修改了yolo_video.py下的预测图片的函数,将检测的图片都储存在了outdir里,转化为yolo_img.py脚本如下,预测的时候要用cmd命令行运行,因为argparse如果不适用默认参数配置,不能jupyter中执行,报错为unrecognized arguments
process finished with exit code 2
'''
def detect_img(yolo):
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = yolo.detect_image(image)
r_image.show()
yolo.close_session()
'''
import glob
def detect_img(yolo):
path = "D:\VOCdevkit\VOC2007\JPEGImages\*.jpg"
outdir = "D:\\VOCdevkit\VOC2007\SegmentationClass"
for jpgfile in glob.glob(path):
img = Image.open(jpgfile)
img = yolo.detect_image(img)
img.save(os.path.join(outdir, os.path.basename(jpgfile)))
yolo.close_session()
import sys
import argparse
from yolo import YOLO, detect_video
from PIL import Image
import glob
import os
os.chdir('E:\work\VOC2007\keras-yolo3')
def detect_img(yolo):
path = "./241.jpg"
outdir = "./SegmentationClass"
for jpgfile in glob.glob(path):
img = Image.open(jpgfile)
img = yolo.detect_image(img)
img.save(os.path.join(outdir, os.path.basename(jpgfile)))
yolo.close_session()
FLAGS = None
parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS)
##parser.parse_args()
'''
Command line options
'''
parser.add_argument(
'--model', type=str,
help='path to model weight file, default ' + YOLO.get_defaults("model_path")
)
parser.add_argument(
'--anchors', type=str,
help='path to anchor definitions, default ' + YOLO.get_defaults("anchors_path")
)
parser.add_argument(
'--classes', type=str,
help='path to class definitions, default ' + YOLO.get_defaults("classes_path")
)
parser.add_argument(
'--gpu_num', type=int,
help='Number of GPU to use, default ' + str(YOLO.get_defaults("gpu_num"))
)
parser.add_argument(
'--image', default=False, action="store_true",
help='Image detection mode, will ignore all positional arguments'
)
'''
Command line positional arguments -- for video detection mode
'''
parser.add_argument(
"--input", nargs='?', type=str, required=False, default='./path2your_video',
help="Video input path"
)
parser.add_argument(
"--output", nargs='?', type=str, default="",
help="[Optional] Video output path"
)
FLAGS = parser.parse_args()
print(FLAGS)
detect_img(YOLO(**vars(FLAGS)))