YOLOv3: An Incremental Improvement
https://pjreddie.com/yolo/
本文是对 YOLO系列的进一步完善。
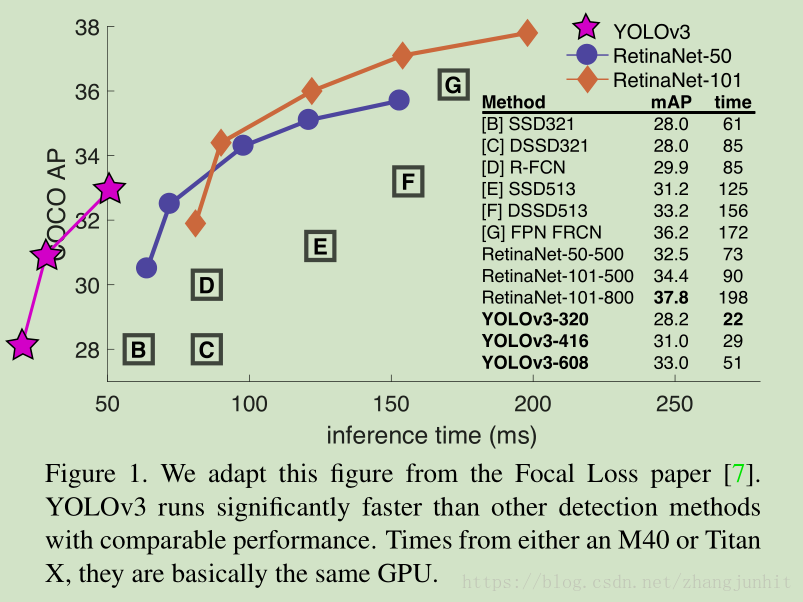
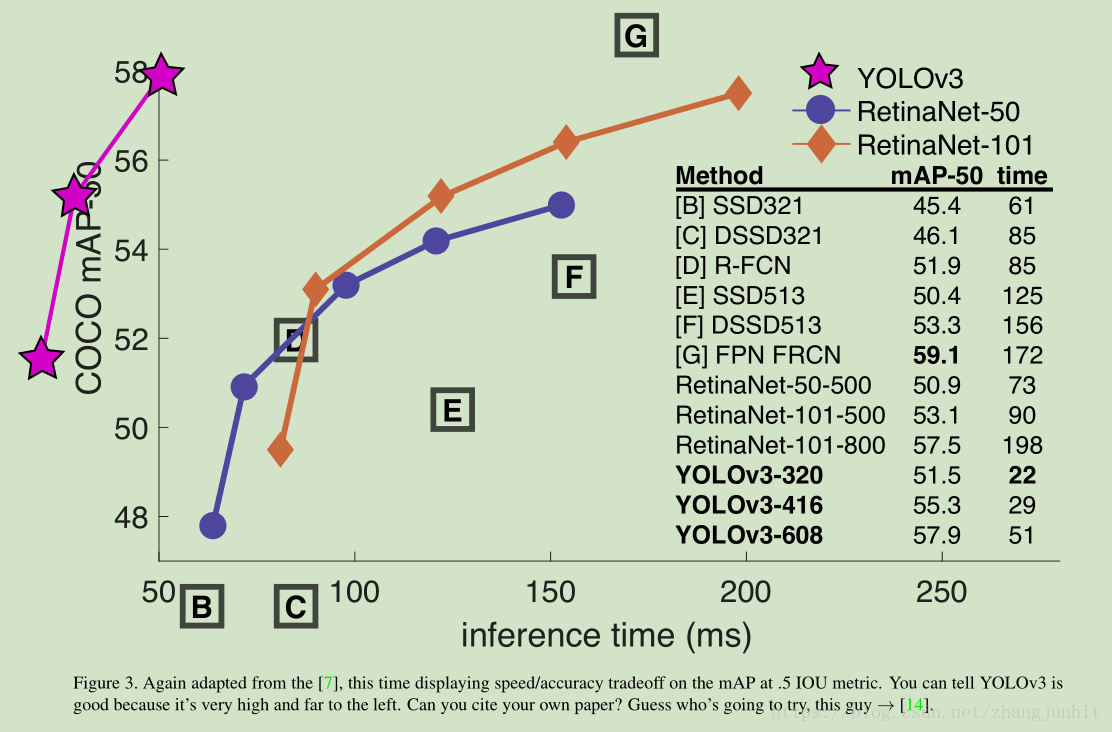
先上和其他检测算法的 COCO 对比结果
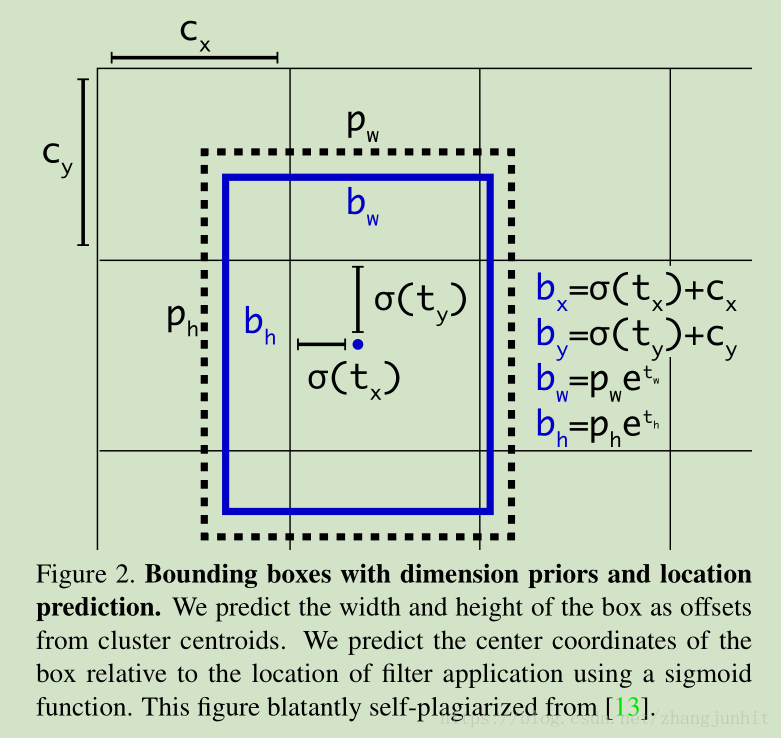
2.1. Bounding Box Prediction
和 YOLO v2 一样,这里我们采用了 dimension clusters as anchor boxes 来预测矩形框坐标,这一部分基本没有改变
2.2. Class Prediction
在进行类别预测时,我们没有采用 softmax 而是采用了 independent logistic classifiers, 主要是因为有时类别之间有重叠overlapping labels (i.e. Woman and Person), A multilabel approach better models the data.
2.3. Predictions Across Scales
多尺度特征图上进行检测,这里我们借鉴 FPN 在 3个不同尺寸特征图进行检测
我们仍然使用 k-means 聚类来选择 bounding box priors。 We just sort of chose 9 clusters and 3 scales arbitrarily and then divide up the clusters evenly across scales. On the COCO dataset the 9 clusters were: (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116 × 90),(156 × 198),(373 × 326).
2.4. Feature Extractor
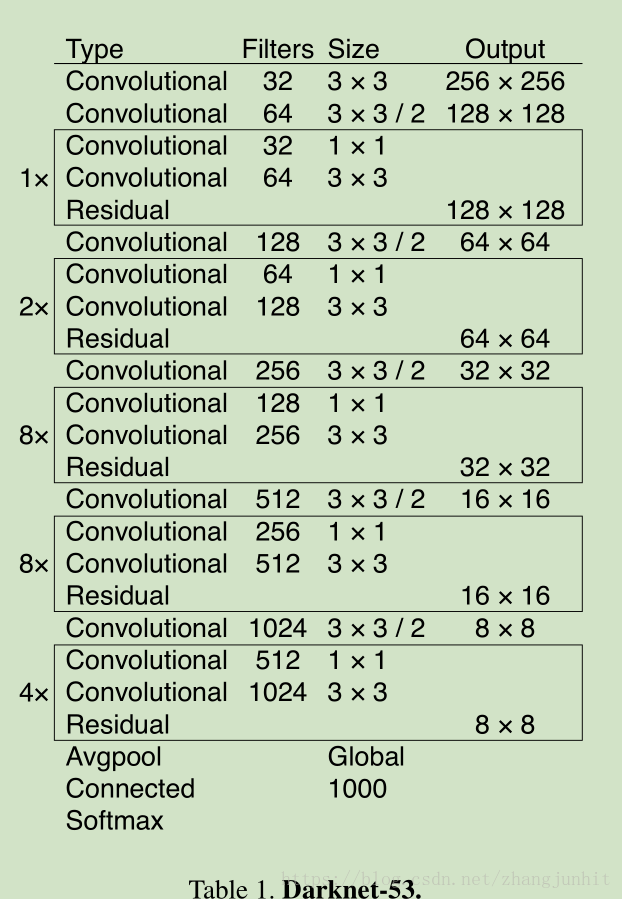
这里我们设计了一个新的网络 Darknet-53,计算量比 Darknet-19 要大,但是性能更强
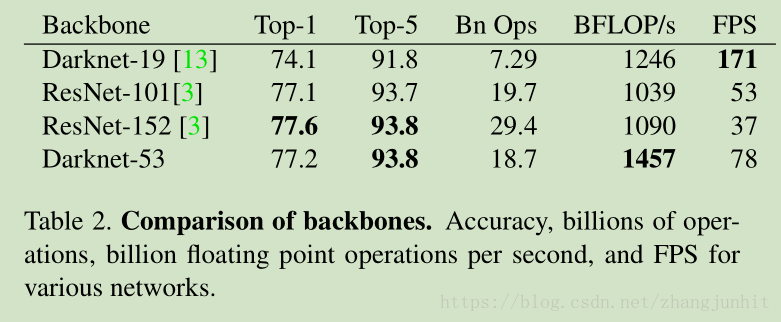
在 ImageNet 上不同网络结构的 精度和运算量 对比
2.5. Training
我们没有采用 hardnegativemining 或其他手段。采用了 multi-scale training, lots of data augmentation, batch normalization, all the standard stuff.
3 How We Do
In terms of COCOs weird average mean AP metric it is on par with the SSD variants but is 3× faster
4 Things We Tried That Didn’t Work
我们也尝试了一些思路,但是效果不是很好,这里也介绍了一下。
1)Anchor box x,y offset predictions
2)Linear x,y predictions instead of logistic
3)Focal loss
4)Dual IOU thresholds and truth assignment
总结一下主要改进的地方:
1)v3替换了v2的softmax loss 变成logistic loss,而且每个ground truth只匹配一个先验框。
2)v2作者用了5个anchor,v3用了9个anchor,提高了IOU
3)使用 多尺度特征图检测,这一步对小目标检测的提升最大
4)设计了 Darknet-53
虽然 Darknet-53 的计算量是 Darknet-19的两倍,但是 BFLOP/s (billion floating point operations per second) 却相差不太多