原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。

一个小故事
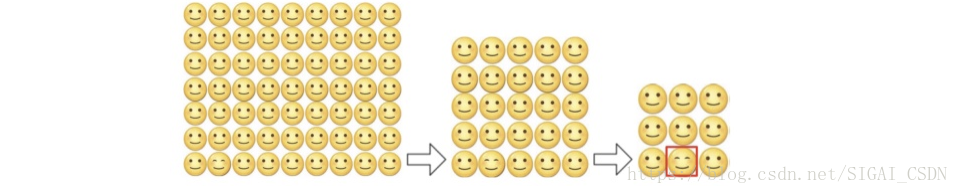
先假设一个场景,幼儿园老师给小朋友们出了一个题目,看谁能最快的找出笑的最美的那张脸?各位SIGAIer也可以试验下,和小朋友们比比测试下自己的辨识能力。

其中有A、B、C三个小朋友很快找出了那张笑的最开心的脸,紧接着其它小朋友也陆陆续续或快或慢的找到了。
这时候老师请了前三个最快找到的小朋友讲授经验:
-
获得第三名的C小朋友说,我的方法很简答,从左到右从上到下快速扫描,一个一个表情去判断就能找出那个笑的最开心的表情。

-
获得第二名的B的小盆友说,我会先确定几个重点区域,如红框所示区域(视觉一眼看过去上有差异),然后在对那个区域进行细致判断,确定那个笑的最开心的脸。

-
轮到获得第一名的A的小盆友了说了,大家都想知道它为什么那么快?A小朋友卖了个关子,我既不会一个一个笑脸去一次判断,也不会根据区域去判断。我会快速对全图进行一层层过滤,在脑海中形成一张小图总共3x3张笑脸,很容易就找到最后那张笑的最开心的脸。听过之后其它小朋友一脸疑惑……
上面的例子可能举得有些牵强,下面会结合检测的几种经典的方法一一带入:
C小朋友代表了基于扫描窗口的方法,比如很多基于HOG+SVM,VJ的方法,很勤奋但是太耿直;B小朋友稍微聪明了点,会根据经验把可以区域挑选出来在进行判别,类似使用了SelectiveSearch[1]、EdgeBoxes[2]、Bing[3]等proposal的方法,大大缩小了搜索的空间;B和C小朋友虽然都顺利达成了目标但是直接在原始图片中进行分析始终是太耗费精力,而A小朋友的套路则要高明的多,他将图片一层层在自己的脑海中进行融合缩小,最后在一张浓缩的小图上快速定位了目标,我们今天要介绍的YOLO[4](You Only Look Once)和第一名A小朋友的思路有异曲同工之妙。
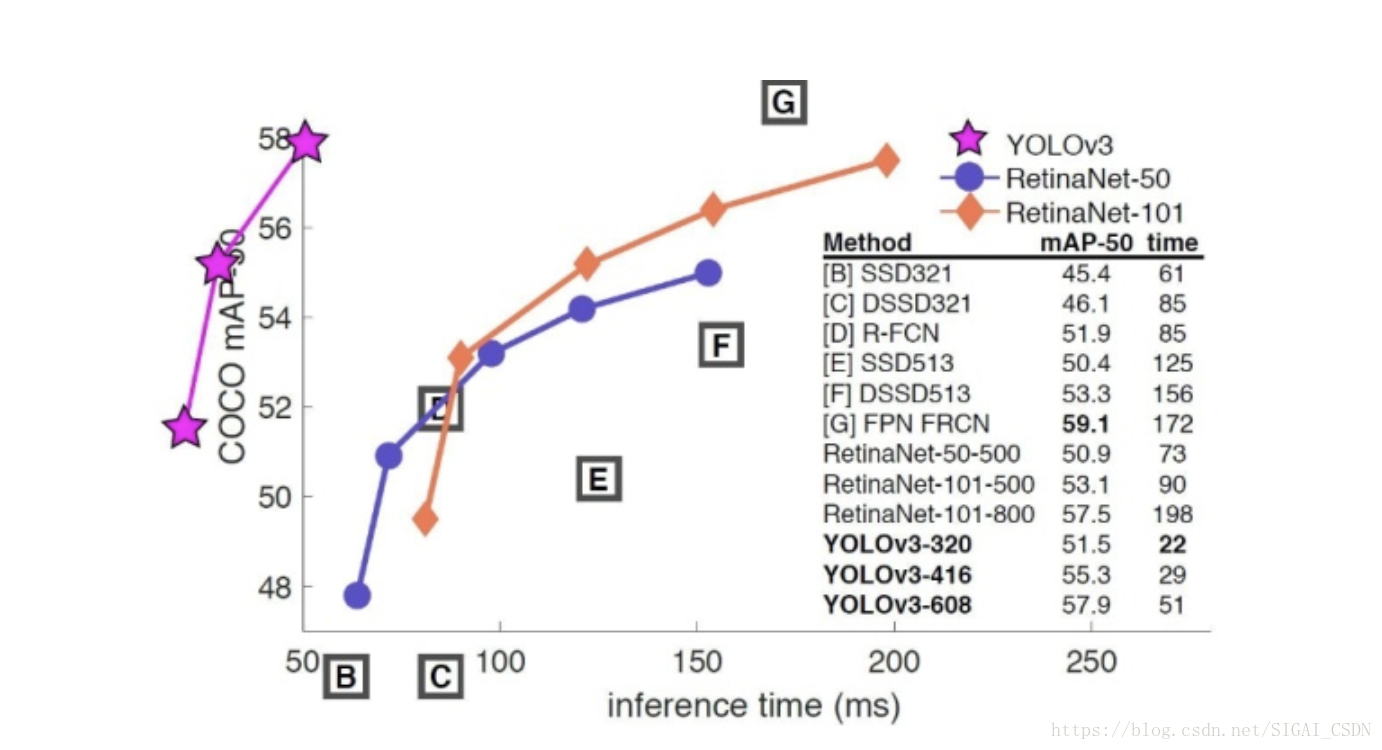
YOLO作为基于深度学习的第一个one-stage的方法做快可以在TitanX GPU上做到45帧每秒的检测速度,轻量版的可以做到155帧每秒,快到没朋友有没有?相比于R-CNN[5]精确度也有非常大的提升53.5 VS 63.4 mAP,真是做到了多快好省!
下面我尽可能讲清楚YOLO系列算法的Insight,水平有限,请各位多多拍砖!
YOLO的动机
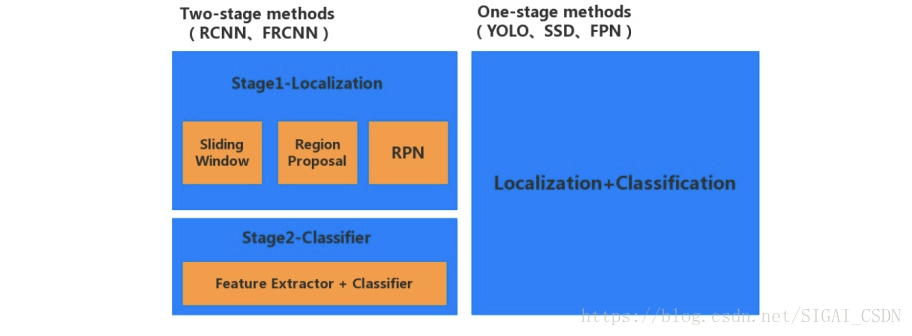
YOLO的作者认为,之前的检测策略比较慢而且难以优化,比如R-CNN为首的候选框+预测位置、分类的这种策略。R-CNN首先产生一些潜在的region proposal,然后用分类器对每一个region进行分类并修正优化物体的边界,最后铜鼓NMS合并消除重复检测框,这个过程被业界称为two-stage。YOLO作为one-stage的鼻祖,将目标检测看作为单一的回归问题,直接由图像像素优化得到物体边界位置和分类。
YOLOv1的实现细节
YOLOv1网络结构
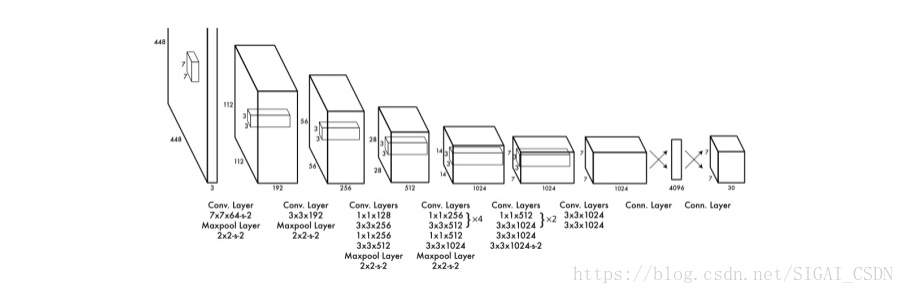
模型灵感来自于GoogLeNet[6],用1x1 和3x3 卷积核代替inception modules. 激活函数用的是Leaky ReLU : f(x)=max(x,0.1x),在x小于0的时候,用了0.1x,避免使用ReLU
的时候有些单元永远得不到激活(Dead ReLU Problem),在不增加计算法复杂度的前提下提升了模型的拟合能力。
YOLOv1由24 层卷积层接2层全连接组成。用ImageNet数据集做预训练(图片尺寸224×224),做检测模型优化时对输入图片尺寸放大了两倍(图片尺寸448×448)。通过改变训练数据的饱和度,曝光度,色调,抖动进行数据增强。
模型输出部分:
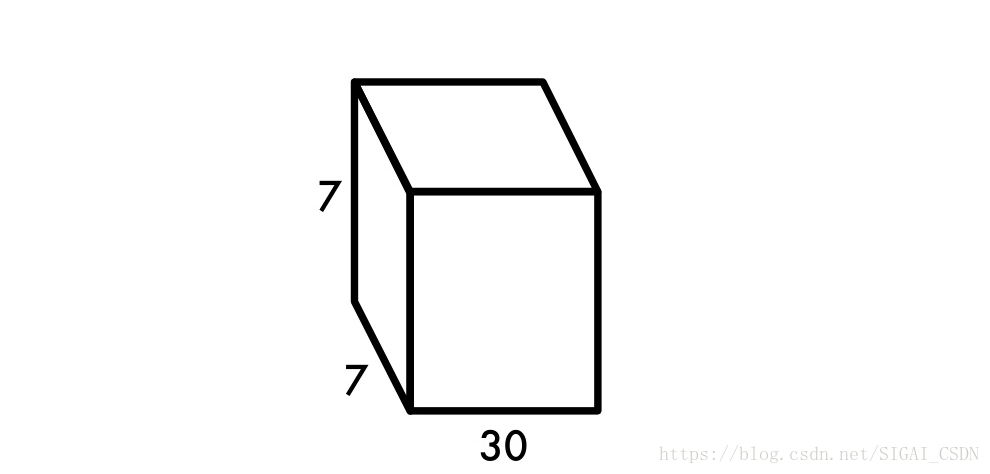

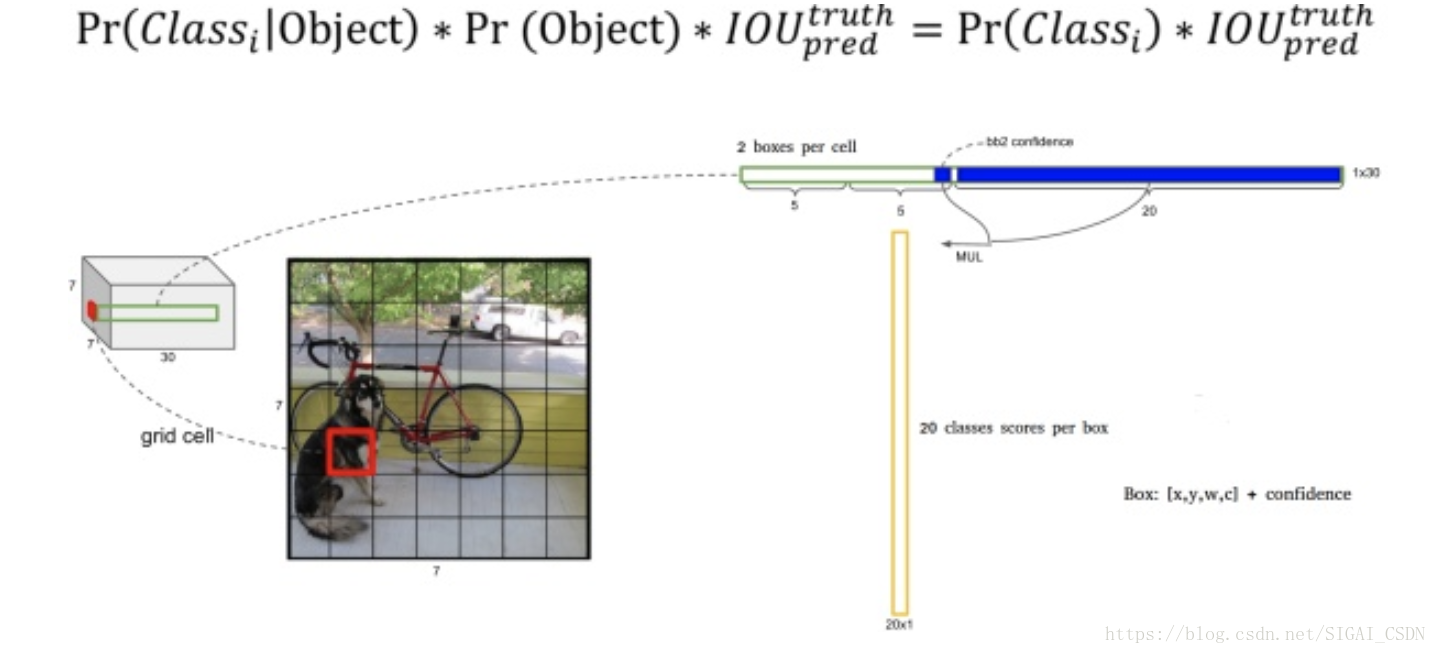
损失函数设计
YOLOv1的损失函数设计简单粗暴对所有的项统一用sum-squared error进行优化。

损失函数分析:

显然,对小框预测偏差10个像素带来了更高的损失。通过增加根号,使得预测相同偏差与更小的框产生更大的损失。但根据YOLOv2的实验证明,还有更好的方法解决这个问题。
YOLOv1的优点
-
YOLO v1检测物体非常快。
因为没有复杂的检测流程,YOLO将目标检测重建为一个单一的回归问题,从图像像素直接到边界框坐标和分类概率,而且只预测98个框,YOLO可以非常快的完成物体检测任务。YOLO在Titan X 的 GPU 上能达到45 FPS。Fast YOLO检测速度可以达到155 FPS。
2、YOLO可以很好的避免背景错误,其它物体检测算法使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时,由于最后进行回归之前接了4096全连接,所以每一个Grid cell对应的预测结果都相当于使用了全图的上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。
3、YOLO可以学到更泛化的特征。 当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。
YOLO v1的缺点
-
对邻近物体检测效果差,由于每个grid cell仅预测两个框和一个分类,对于多物体的中心位置落入同一cell,YOLOv1力所不及。
-
用全连接的问题在于,虽然获取了全局信息,但是比起1×1卷积来说也丢失了局部
细节信息;全连接带来了参数量的巨增。
-
对不常见的长宽比物体泛化能力偏弱,这个问题主要是YOLO没有Anchor的不同s尺度框的设计,只能通过数据去驱动。
-
损失函数的设计问题,对坐标的回归和分类的问题同时用MSE损失明显不合理。
-
由于YOLOv1是直接预测的BBox位置,相较于预测物体的偏移量,模型会不太好稳定收敛。
YOLOv2的实现细节[7]
YOLOv2网络结构
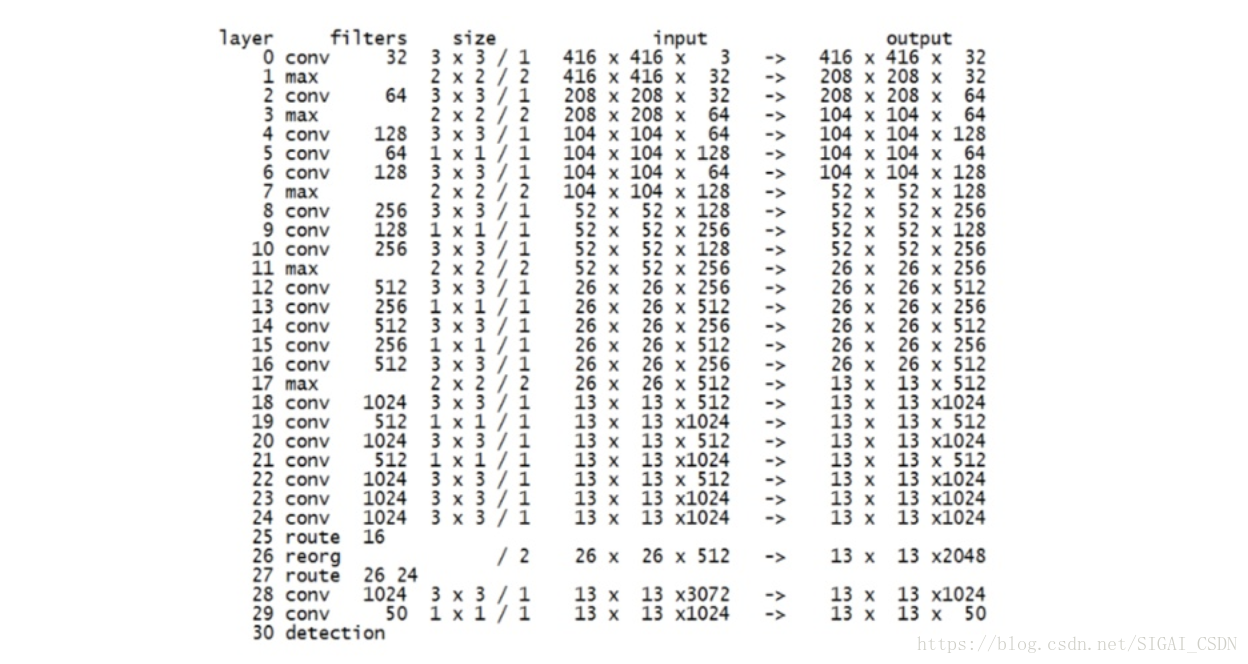
相较于YOLOv1的改进:
-
保留v1数据增强的策略的同时,增加了图片180°反转和多尺度训练。
-
添加了batch normalization,舍弃掉了dropout,提升模型泛化能力的同时使得模型更容易收敛。
-
首次提出darknet19,并用全卷积替代全连接,解决了v1全连接的问题,大大减少了参数规模。
-
不再像v1一样,直接预测BBox的位置和大小,而是受faster r-cnn影响,有了anchor的概念,从而预测BBox相对于anchor boxes的偏移量。
-
v2对Faster R-CNN的人为设定先验框方法做了改进,采样k-means在训练集BBox上进行聚类产生合适的先验框.由于使用欧氏距离会使较大的BBox比小的BBox产生更大的误差,而IOU与BBox尺寸无关,因此使用IOU参与距离计算,使得通过这些sanchor boxes获得好的IOU分值。改进的距离评估公式:
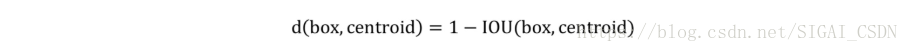
使用聚类方法进行选择的优势是达到相同的IOU结果时所需的anchor box数量更少,使得模型的表示能力更强,任务更容易学习。同时作者发现直接把faster-rcnn预测region proposal的策略应用于YOLO会出现模型在训练初期不稳定。原因来自于预测region proposal的中心点相对于anchor boxes中心的偏移量较大,不好收敛,公式如下:
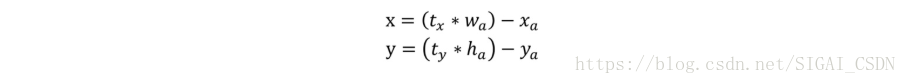
由公式可见,如果预测值=1,region proposal将要向右移一个anchor box的宽度。这个公式对于region proposal和anchor box之间不受限制的,所以随机初始化模型需要很长时间才能稳定以预测合理的偏移。
作者对此公式做了改进:
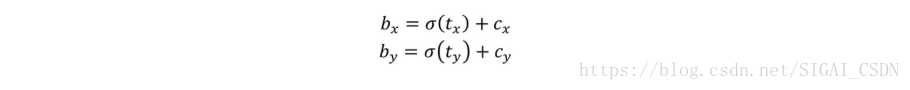
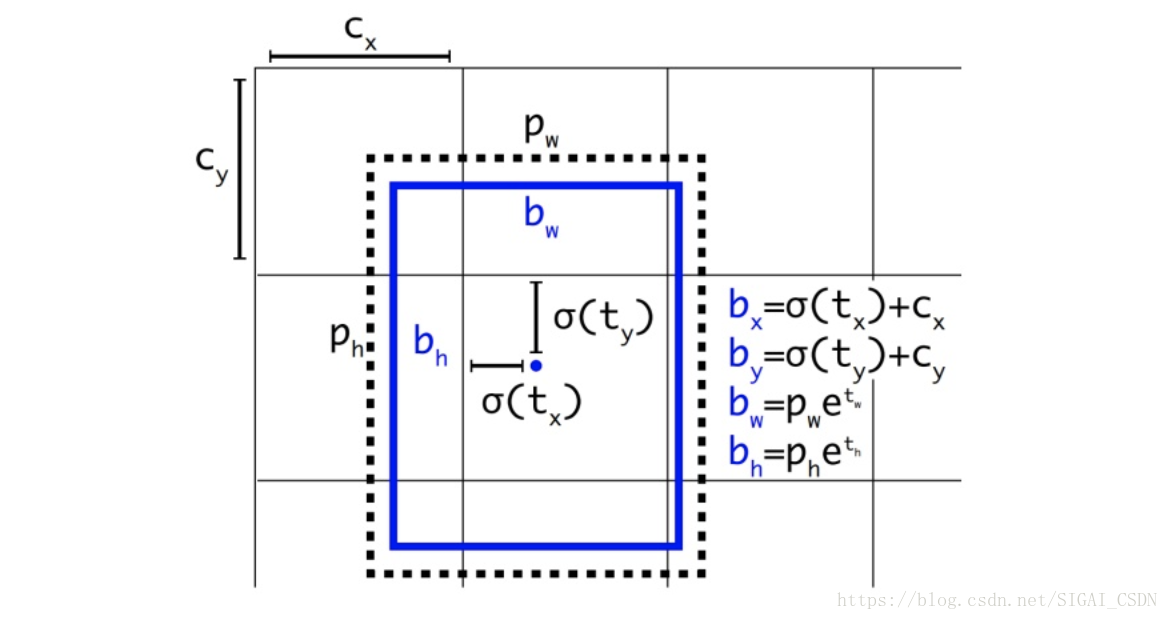
由下图可见,将预测值加以sigmoid运算,将region proposal的中心点牢牢地限定在了anchor box的中心点所在的cell里,很明显这样偏移量会好学了很多。

YOLOv3的实现细节[8]
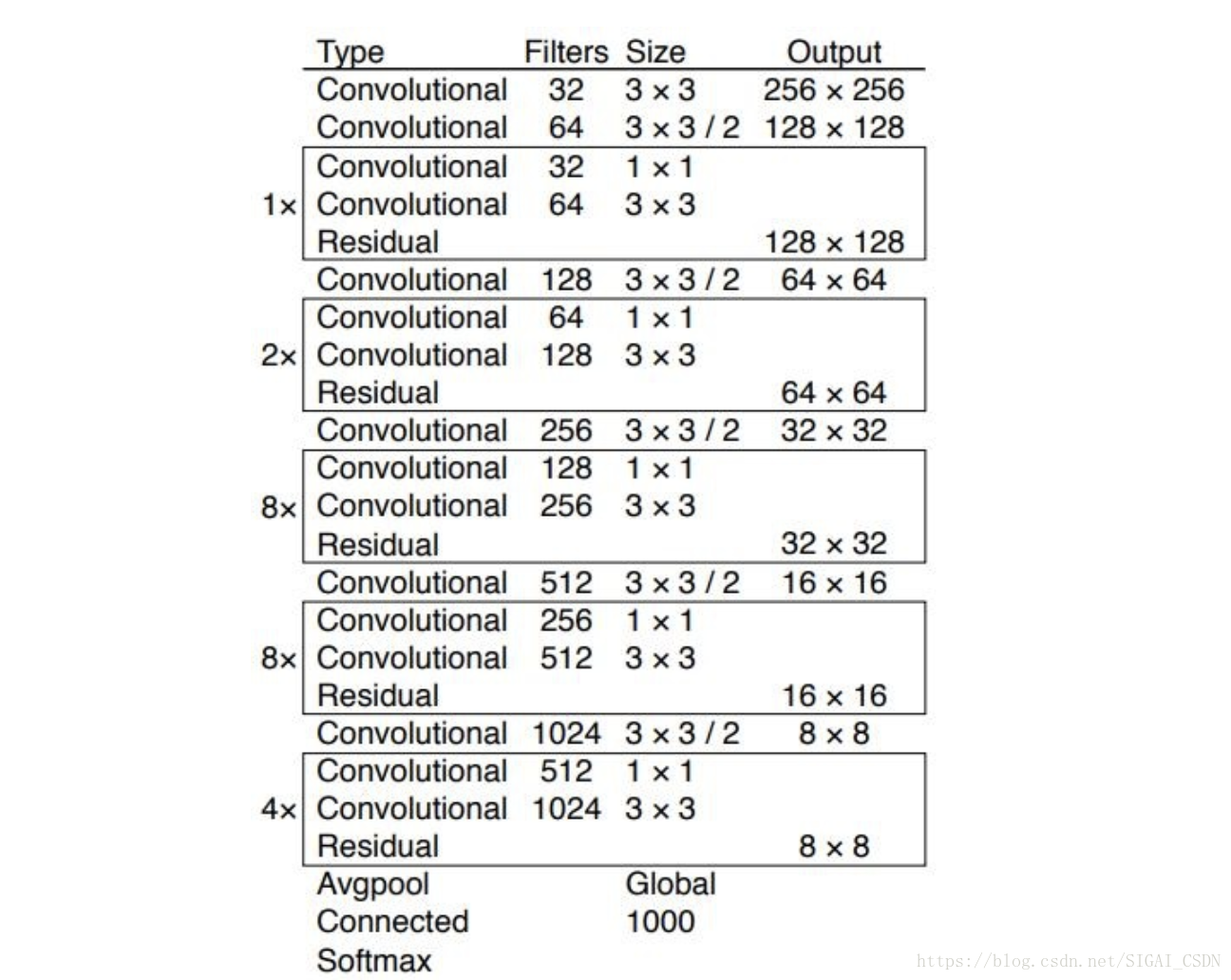
YOLOv3网络结构
相较于前两版的改进点:
-
提出了darknet53,由于加深了网络,应用resnet的思想,添加了residual block,降低了梯度消失的风险。不再使用pooling层,而是用步长为2的卷积层代替,避免了信息丢失,想进一步了解的同学可以拜读一下这篇文章Springenberg J T, Dosovitskiy A, Brox T, et al. Striving for simplicity: The all convolutional net[J]. arXiv preprint arXiv:1412.6806, 2014.。
-
在检测部分,作者参考了FPN(feature pyramid networks)的思想。用非线性插值方法上采样了两次,获得了3个不同大小的feature maps。和v2相似,作者依然对ground truth 框的大小进行了聚类,不同的是,v3获得的9个尺度的anchor boxes。每个feature map分配3个尺度的anchor boxes。由于深层、语义特征丰富的负责预测大物体(分配大anchor);浅层、几何特征丰富的负责预测小物体(分配小anchor)。这次不仅框多了,而且更细致了,对检测小物体放了大招,所以就目前来说这种策略对检测小物体已经做到头了,想要再改进,可能要换思路了,如果一味地增大输入尺寸显然是不合理的。
-
用Sigmoid代替Softmax,这个改进主要是用于多标签分类。Softmax输出的结果有互斥性,只能预测一类,而如果一个物体有多个标签(如:人和女人),那么Softmax是做不到的。但是在真实的检测场景中存在这样的情况,所以作者使用了Sigmoid函数替代。
最后放一张图,下个不负责任的结论:YOLOv3是集大成者
!
参考文献
[1] Uijlings, J.R., van de Sande, K.E., Gevers, T., Smeulders, A.W.: Selective search for object recognition. IJCV (2013)
[2] C Lawrence Zitnick and Piotr Dollar. Edge boxes: ´ Locating object proposals from edges. In Computer Vision–ECCV 2014, pages 391–405. Springer, 2014.
[3] Ming-Ming Cheng, Ziming Zhang, Wen-Yan Lin, and Philip Torr. Bing: Binarized normed gradients for objectness estimation at 300fps. In Computer Vision and Pattern Recognition, pages 3286–3293, 2014.
[4] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. arXiv preprint arXiv:1506.02640, 2015. 5, 6
[5] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Region-based convolutional networks for accurate object detection and segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 1, pp. 142–158, Jan. 2016.
[6] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link:
http://arxiv.org/abs/1409.4842
.
推荐阅读