文章目录
YOLO
整体结构

源码
def _build_net(self):
"""build the network"""
if self.verbose:
print("Start to build the network ...")
self.images = tf.placeholder(tf.float32, [None, 448, 448, 3])
net = self._conv_layer(self.images, 1, 64, 7, 2)
net = self._maxpool_layer(net, 1, 2, 2)
net = self._conv_layer(net, 2, 192, 3, 1)
net = self._maxpool_layer(net, 2, 2, 2)
net = self._conv_layer(net, 3, 128, 1, 1)
net = self._conv_layer(net, 4, 256, 3, 1)
net = self._conv_layer(net, 5, 256, 1, 1)
net = self._conv_layer(net, 6, 512, 3, 1)
net = self._maxpool_layer(net, 6, 2, 2)
net = self._conv_layer(net, 7, 256, 1, 1)
net = self._conv_layer(net, 8, 512, 3, 1)
net = self._conv_layer(net, 9, 256, 1, 1)
net = self._conv_layer(net, 10, 512, 3, 1)
net = self._conv_layer(net, 11, 256, 1, 1)
net = self._conv_layer(net, 12, 512, 3, 1)
net = self._conv_layer(net, 13, 256, 1, 1)
net = self._conv_layer(net, 14, 512, 3, 1)
net = self._conv_layer(net, 15, 512, 1, 1)
net = self._conv_layer(net, 16, 1024, 3, 1)
net = self._maxpool_layer(net, 16, 2, 2)
net = self._conv_layer(net, 17, 512, 1, 1)
net = self._conv_layer(net, 18, 1024, 3, 1)
net = self._conv_layer(net, 19, 512, 1, 1)
net = self._conv_layer(net, 20, 1024, 3, 1)
net = self._conv_layer(net, 21, 1024, 3, 1)
net = self._conv_layer(net, 22, 1024, 3, 2)
net = self._conv_layer(net, 23, 1024, 3, 1)
net = self._conv_layer(net, 24, 1024, 3, 1)
net = self._flatten(net)
net = self._fc_layer(net, 25, 512, activation=leak_relu)
net = self._fc_layer(net, 26, 4096, activation=leak_relu)
net = self._fc_layer(net, 27, self.S*self.S*(self.C+5*self.B))
self.predicts = net
YOLO的核心思想
- YOLO全称是you only look once。之前的目标检测算法,R-CNN等是将目标检测问题转换为region proposal+ object classification的问题来解决。相对于之前的检测算法的一个关键的思想改进是,将目标检测问题视为一个回归问题,通过一个网络实现训练和预测,极大的提升了检测速度。
实现方法
- 直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
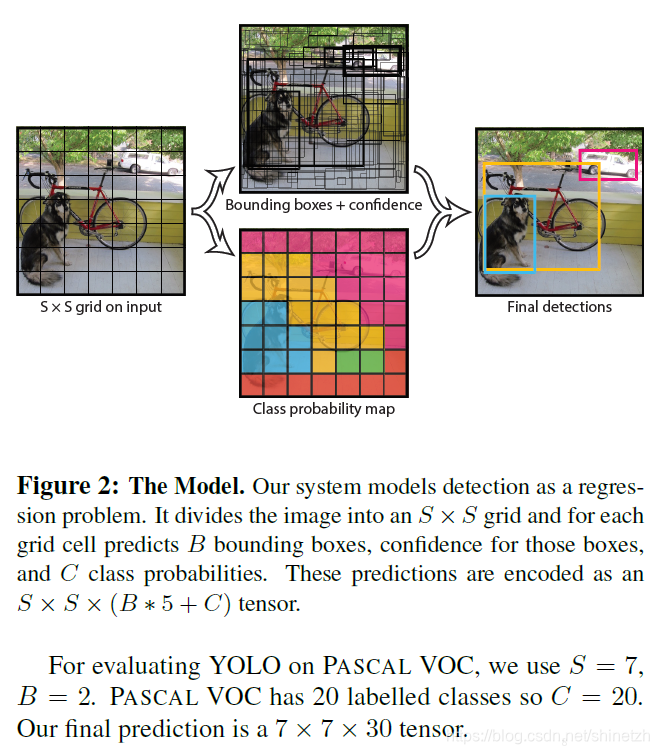
损失函数

训练
- 先将网络中前20层卷积层后面加上一个平均池化层和一个全连接层在ImageNet上面1000个类别的分类数据集上进行预训练。使用的是DarkNet framework
- 将模型转换为检测模型,在之后加入四层卷积层和两层全连接层,作为最终的检测模型。为了提高检测效果,将输入图片从224x224大小增加为448x448,在预训练的时候采用的输入图片大小是224x224
- 使用leaky Relu,作为激活函数
预测
- 设置置信度阈值,过滤掉置信度小于该阈值的box,保留置信度较高的预测框
- 对留下来的预测框采用NMS算法,得到最终的预测结果。这里有两种思路,一种是区分类别分别采用NMS算法;另一种是对所有预测框同等对待。区别类别采用NMS算法理论上来说效果更好,但是很多实现都是对所有预测框同等对待,实际效果并差别不大,主要原因可能是在同一个位置出现不同类别的概率较小。
优缺点
- 训练和预测都是end-to-end,所以YOLO算法比较简洁且速度快
- YOLO对整个图片做卷积,在目标检测时有更大的视野,不容易对背景误判
- 模型泛化能力强,比如可以对艺术画作进行检测
- 虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的 bounding box 作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是 YOLO 方法的一个缺陷。这方面可以看SSD,采用的多尺度单元格。
- 在宽高比方面泛化率底,无法定位不寻常比例的物体,定位不如proposal+classification方法准确
YOLO-V2
论文 https://arxiv.org/pdf/1612.08242.pdf
主要包含内容YOLOv2相对于YOLOv1的改进,以及在YOLOv2基础上YOLO9000的训练过程,wordtree的构建。
模型结构
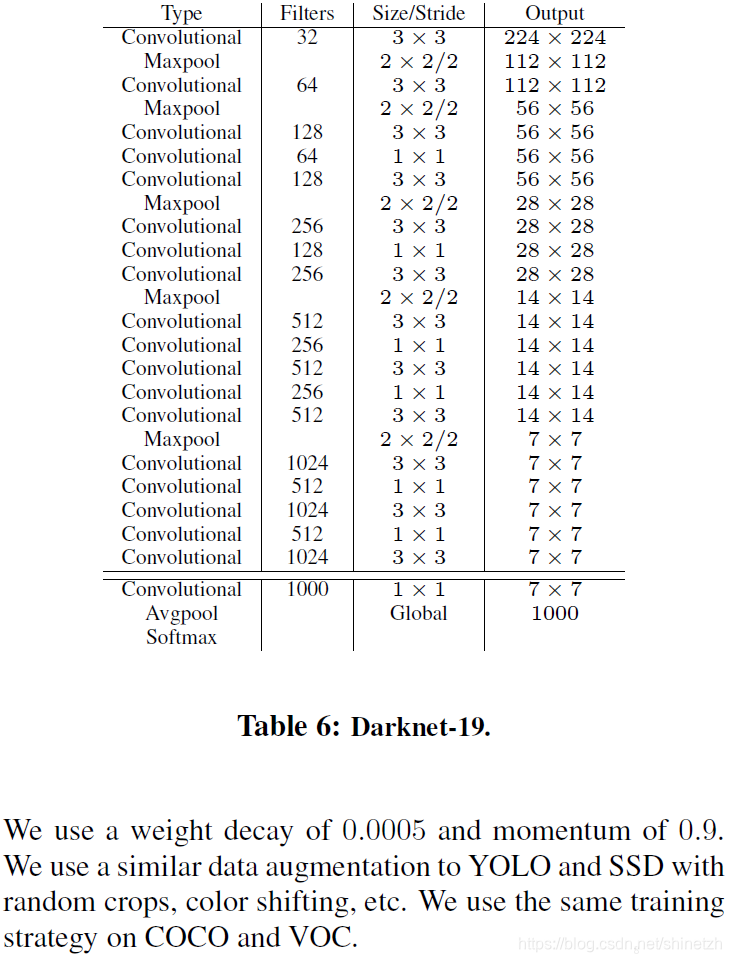
代码
def darknet(images, n_last_channels=425):
"""Darknet19 for YOLOv2"""
net = conv2d(images, 32, 3, 1, name="conv1")
net = maxpool(net, name="pool1")
net = conv2d(net, 64, 3, 1, name="conv2")
net = maxpool(net, name="pool2")
net = conv2d(net, 128, 3, 1, name="conv3_1")
net = conv2d(net, 64, 1, name="conv3_2")
net = conv2d(net, 128, 3, 1, name="conv3_3")
net = maxpool(net, name="pool3")
net = conv2d(net, 256, 3, 1, name="conv4_1")
net = conv2d(net, 128, 1, name="conv4_2")
net = conv2d(net, 256, 3, 1, name="conv4_3")
net = maxpool(net, name="pool4")
net = conv2d(net, 512, 3, 1, name="conv5_1")
net = conv2d(net, 256, 1, name="conv5_2")
net = conv2d(net, 512, 3, 1, name="conv5_3")
net = conv2d(net, 256, 1, name="conv5_4")
net = conv2d(net, 512, 3, 1, name="conv5_5")
shortcut = net
net = maxpool(net, name="pool5")
net = conv2d(net, 1024, 3, 1, name="conv6_1")
net = conv2d(net, 512, 1, name="conv6_2")
net = conv2d(net, 1024, 3, 1, name="conv6_3")
net = conv2d(net, 512, 1, name="conv6_4")
net = conv2d(net, 1024, 3, 1, name="conv6_5")
# ---------
net = conv2d(net, 1024, 3, 1, name="conv7_1")
net = conv2d(net, 1024, 3, 1, name="conv7_2")
# shortcut
shortcut = conv2d(shortcut, 64, 1, name="conv_shortcut")
shortcut = reorg(shortcut, 2)
net = tf.concat([shortcut, net], axis=-1)
net = conv2d(net, 1024, 3, 1, name="conv8")
# detection layer
net = conv2d(net, n_last_channels, 1, batch_normalize=0,
activation=None, use_bias=True, name="conv_dec")
return net
改进策略
YOLO模型虽然速度较快,但是相对于R-CNN,在检测定位精度上面较差。YOLOv2主要是针对检测精度上面进行了一系列的改进。
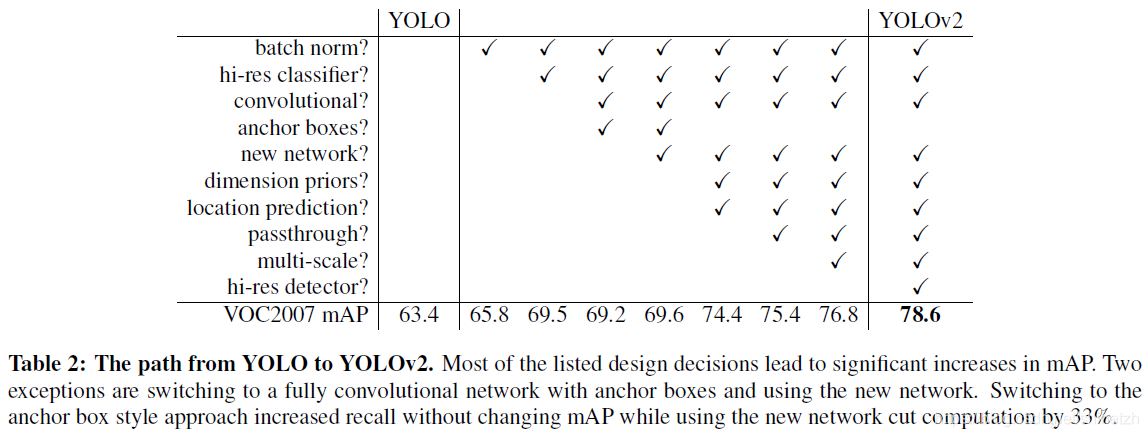
训练
- 在ImageNet上面预训练模型,先采用的输入时224x224训练160个epochs;然后调整输入为448x448,finetune,10个epochs;更改Darknet-19的分类模型为检测模型,在检测数据集上进行finetune网络。
- 为了保证最终得到的特征图维度大小为奇数,在检测模型中采用的输入图片的大小是416x416,采用总步长为32,则最终的特征图大小为13x13,这样保证了特征图正好只有一个中心位置。
- loss函数

YOLO9000
联合ImageNet的庞大的分类数据集,以及coco的检测数据集,训练得到可以检测9000+类别的YOLO9000模型。这是这篇文章中最大的贡献。主要采用的方法是采用联合两个数据集构建wordtree的方法
在COCO和ImageNet数据集上进行联合训练遇到的第一问题是两者的类别并不是完全互斥的,比如"Norfolk terrier"明显属于"dog",所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree,结合COCO和ImageNet建立的WordTree如下图所示:
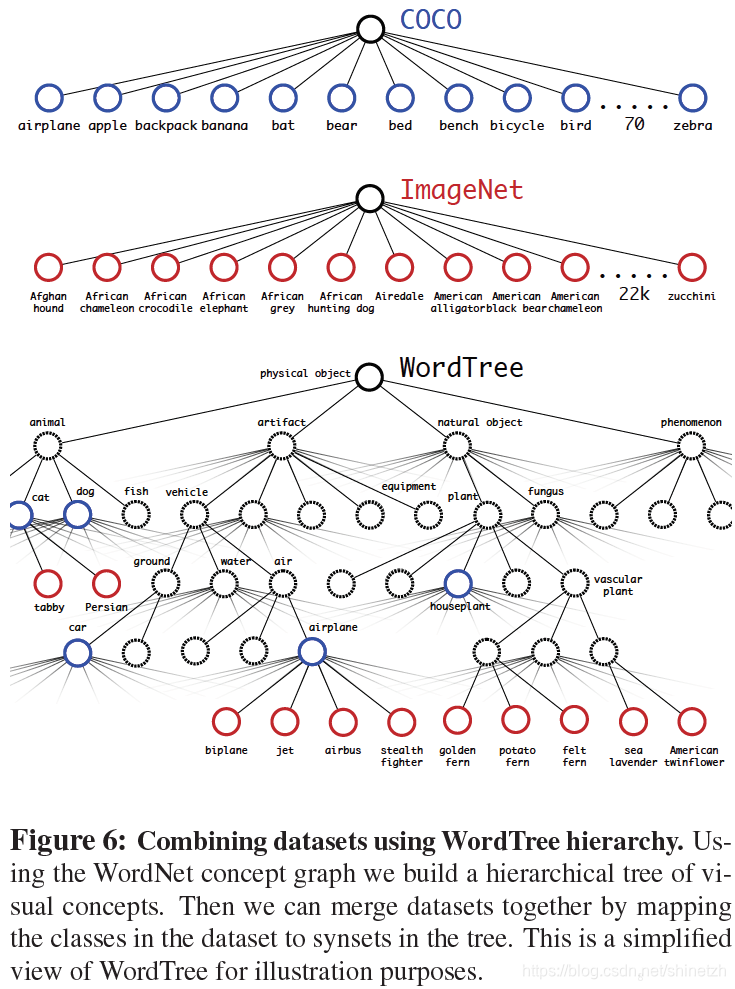
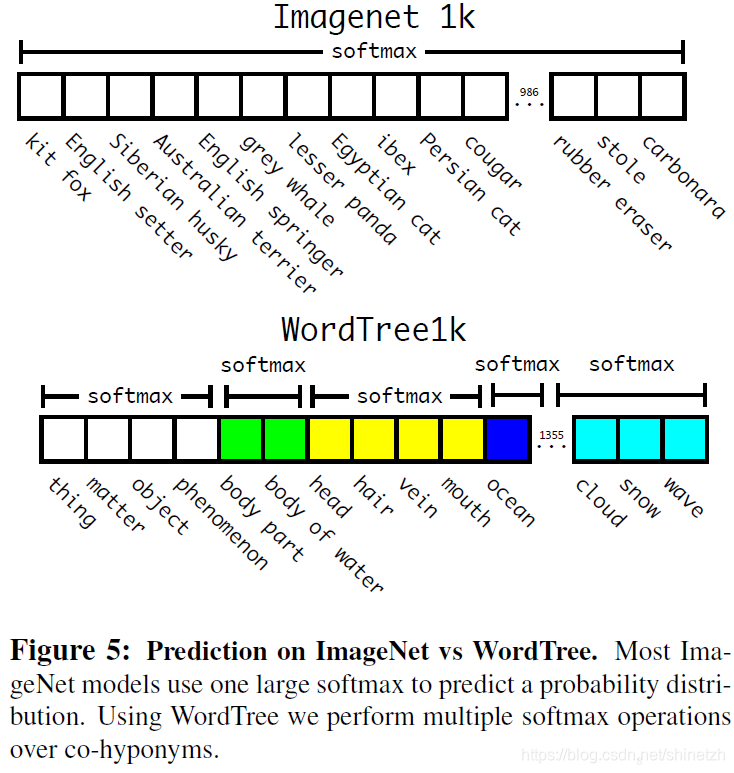
在训练时,如果是检测样本,按照YOLOv2的loss计算误差,而对于分类样本,只计算分类误差。在预测时,YOLOv2给出的置信度就是 Pr(physical \space object) ,同时会给出边界框位置以及一个树状概率图。在这个概率图中找到概率最高的路径,当达到某一个阈值时停止,就用当前节点表示预测的类别。通过联合训练策略,YOLO9000可以快速检测出超过9000个类别的物体,总体mAP值为19,7%。
YOLOv3
改进点
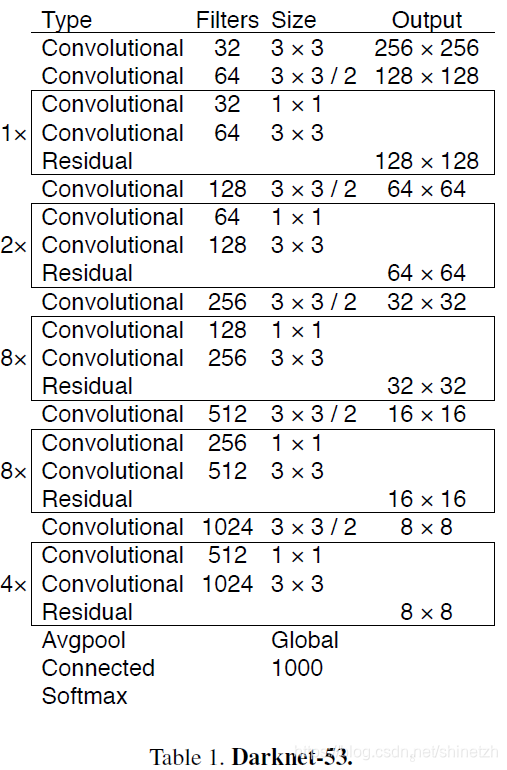
- 引入残差模型,特征图提取模型深度从19增加到53
- 引入特征金字塔网络结构,实现多尺度检测,YOLOv3采用3个尺度特征图:13x13,26x26,52x52
YOLOv3结构

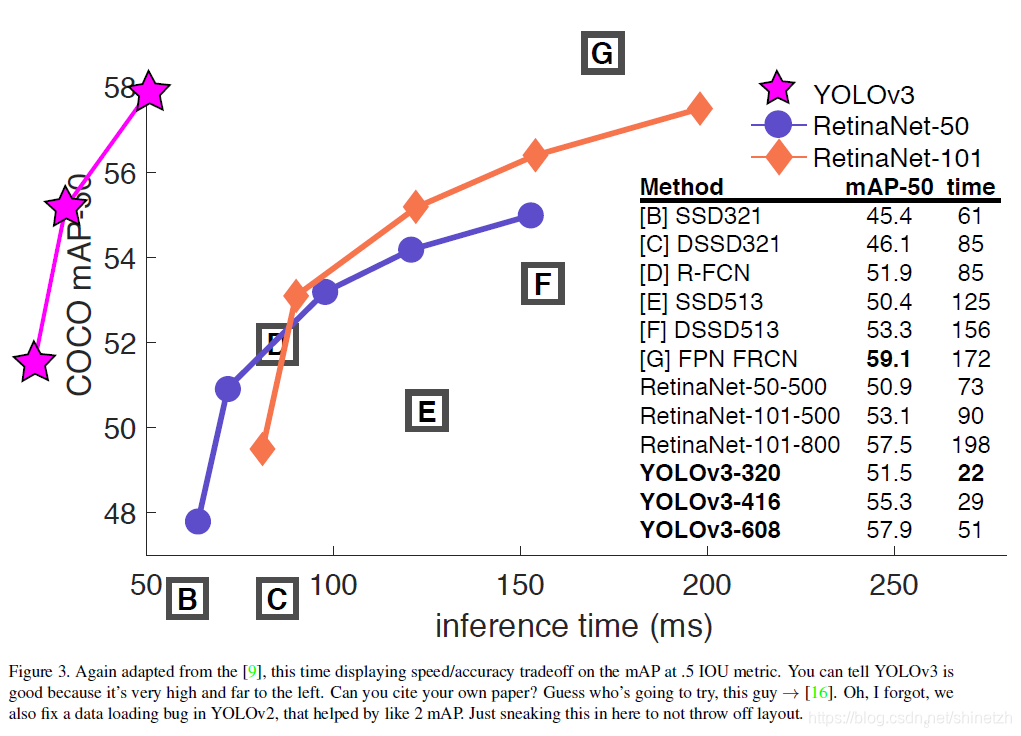
与其他模型对比结果
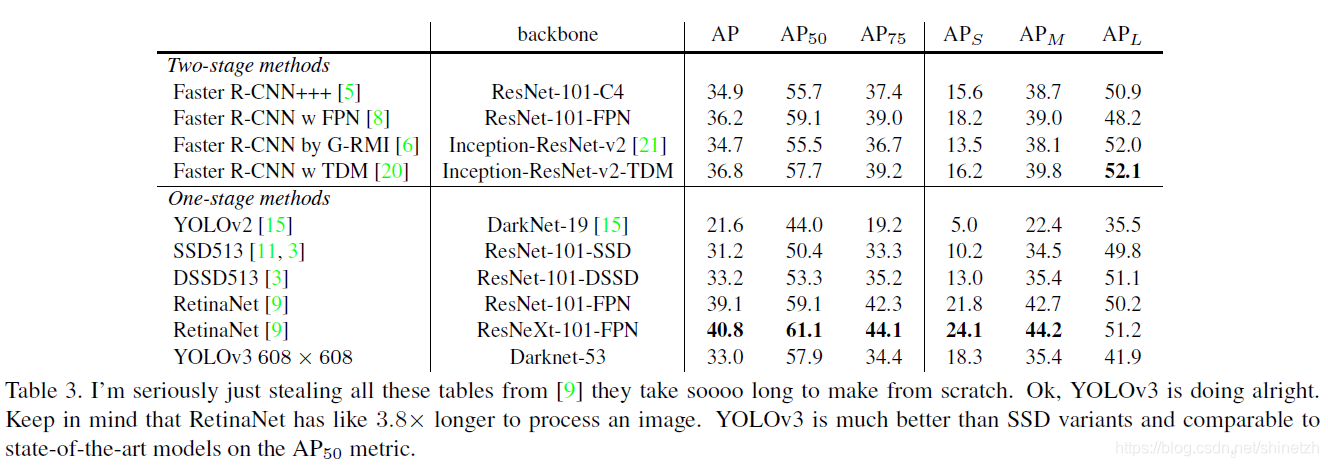
参考:
https://arxiv.org/pdf/1506.02640.pdf
https://arxiv.org/pdf/1612.08242.pdf
https://pjreddie.com/media/files/papers/YOLOv3.pdf
https://zhuanlan.zhihu.com/p/32525231
https://blog.csdn.net/guleileo/article/details/80581858
https://zhuanlan.zhihu.com/p/35325884