Abstract
在《基于深度学习的目标检测思路》中,提到了可以用滑动窗口的思路来做目标检测。除了滑动窗口,还有其他的目标检测算法吗?
目标检测介绍
传统的目标检测算法,都是基于滑动窗口,训练模型的,如下图所示。

该方法对目标的标注,需要标注目标的位置、大小、类型等信息,标注成本是很高的。但是,做目标检测是少不了这个标注工作的。
这种传统的滑动窗口目标检测方法,最大的缺点是: 窗口大小不固定,需要动态改变窗口做多次训练、预测操作,这对模型的训练是非常耗时的。
有没有办法针对一幅图像,只做一次训练呢?这就是YOLO算法要解决的问题。
YOLO算法
YOLO算法的做法,是用一个MxN的网格覆盖在原图上,并对各个小网格的内容进行标注。如下图所示,我们这里假设图像是100x100x3的彩色图像,网格是3x3的,但实际使用过程中,网格会更密。
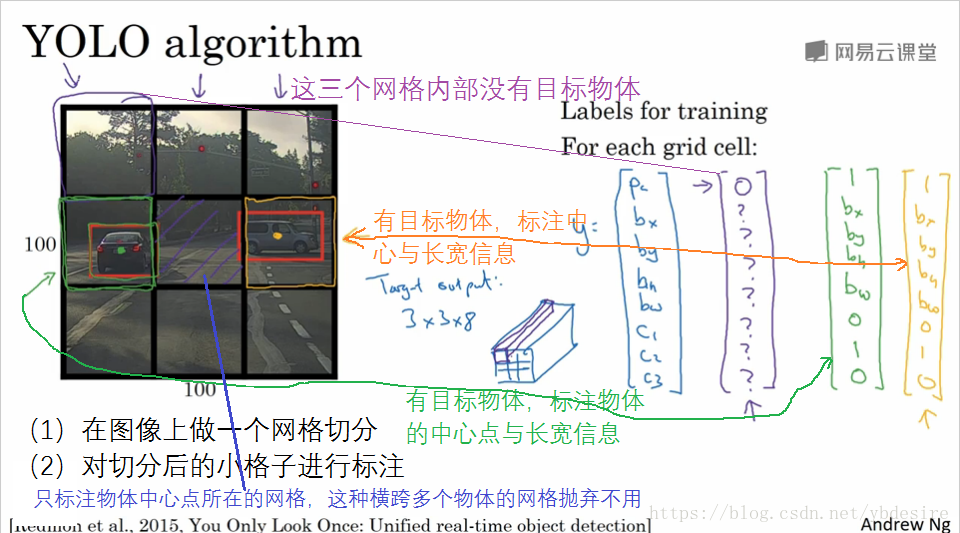
网格覆盖原图后,就对每个小网格的内容进行标注,需要标注如下信息
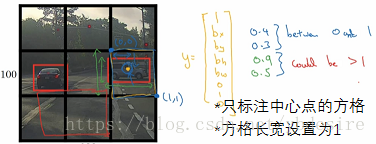
- pc:小网格内是否有目标物体的中心点,注意是根据中心点进行标注,横跨多个网格的物体也只标注有中心点存在的网格。
- bx,by,bh,bw:目标物体中心点在网格中的x-y坐标,以及目标物体的长、宽。一般将小网格长宽取1后进行标注,这样位置坐标都被转化为0~1之间的数值。
- c1,c2,c3:类别,这里假设分三类。
可见,每个小网格需要标注8个Y值。如图3x3的网格,需要标注3x3x8个输出值。标注中有一个小技巧,就是尽量将Y值转化为0~1之间的数值。
最终训练模型时,一幅图像,只需要训练一次:
- 输入:100x100x3
- 输出:3x3x8
所以YOLO算法的效率很高,可以做到实时检测。
YOLO算法实例
可以在这里(https://pjreddie.com/darknet/yolo/)看到YOLO算法做视频物体检测的效果,也能看到很多YOLO网格的设置。github上(https://github.com/pjreddie/darknet/wiki/YOLO:-Real-Time-Object-Detection)也有一个用神经网络框架darknet实现的YOLO算法实例。当然了,也少不了tensorflow的版本(https://github.com/gliese581gg/YOLO_tensorflow)。
参考
本文图片取自AndrewNG的Deep Learning课程,在此表示感谢!