本文转自:https://www.cnblogs.com/fariver/p/7446921.html
1 YOLO
创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测
1.1 创新点
(1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回归,但建议框之间有重叠,这会带来很多重复工作。YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
1.2 Inference过程
YOLO网络结构由24个卷积层与2个全连接层构成,网络入口为448x448(v2为416x416),图片进入网络先经过resize,网络的输出结果为一个张量,维度为:
![]()
其中,S为划分网格数,B为每个网格负责目标个数,C为类别个数。该表达式含义为:
(1) 每个小格会对应B个边界框,边界框的宽高范围为全图,表示以该小格为中心寻找物体的边界框位置。
(2) 每个边界框对应一个分值,代表该处是否有物体及定位准确度:
![]()
(3) 每个小格会对应C个概率值,找出最大概率对应的类别P(Class|object),并认为小格中包含该物体或者该物体的一部分。
1.3 分格思想实现方法
一直困惑的问题是:分格思想在代码实现中究竟如何体现的呢?
在yolov1的yolo.cfg文件中:
[net]
batch=1
subdivisions=1
height=448
width=448
channels=3
momentum=0.9
decay=0.0005
saturation=1.5
exposure=1.5
hue=.1
conv24 。。。
[local]
size=3
stride=1
pad=1
filters=256
activation=leaky
[dropout]
probability=.5
[connected]
output= 1715
activation=linear
[detection]
classes=20
coords=4
rescore=1
side=7
num=3
softmax=0
sqrt=1
jitter=.2
object_scale=1
noobject_scale=.5
class_scale=1
coord_scale=5最后一个全连接层输出特征个数为1715,而detction层将该1715的特征向量整个为一个,![]() 的张量。其中,side∗side即为原图中S∗S的小格。为什么side位置的输出会对应到原图中小格的位置呢?因为训练过程中会使用对应位置的GT监督网络收敛,测试过程中每个小格自然对应原图小格上目标的检测。
的张量。其中,side∗side即为原图中S∗S的小格。为什么side位置的输出会对应到原图中小格的位置呢?因为训练过程中会使用对应位置的GT监督网络收敛,测试过程中每个小格自然对应原图小格上目标的检测。
预测处理过程数据的归一化
在训练yolo前需要先准备数据,其中有一步为:
python voc_label.py中有个convert函数
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)GT边界框转换为(xc, yc, w, h)的表示方式,wc, yc, w, h被归一化到0~1之间。
再看损失函数
参见博文
1.4 YOLO缺点
1) 对小物体及邻近特征检测效果差:当一个小格中出现多于两个小物体或者一个小格中出现多个不同物体时效果欠佳。原因:B表示每个小格预测边界框数,而YOLO默认同格子里所有边界框为同种类物体。
(2) 图片进入网络前会先进行resize为448 x 448,降低检测速度(it takes about 10ms in 25ms),如果直接训练对应尺寸会有加速空间。
(3) 基础网络计算量较大,yolov2使用darknet-19进行加速。
1.5 实验结论
(1) 速度更快(实时):yolo(24 convs) -> 45 fps,fast_yolo(9 convs) -> 150 fps
(2) 全图为范围进行检测(而非在建议框内检测),带来更大的context信息,使得相对于Fast-RCNN误检率更低,但定位精度欠佳。
1.6 YOLO损失函数
Yolo损失函数的理解学习于潜伏在代码中
** Loss = λcoord * 坐标预测误差(1) + 含object的box confidence预测误差 (2)+ λnoobj* 不含object的box confidence预测误差(3) + 每个格子中类别预测误差(4) **

(1) 整个损失函数针对边界框损失(图中1, 2, 3部分)与格子(4部分)主体进行讨论。
(2) 部分1为边界框位置与大小的损失函数,式中对宽高都进行开根是为了使用大小差别比较大的边界框差别减小。例如,一个同样将一个100x100的目标与一个10x10的目标都预测大了10个像素,预测框为110 x 110与20 x 20。显然第一种情况我们还可以失道接受,但第二种情况相当于把边界框预测大了一倍,但如果不使用根号函数,那么损失相同,都为200。但把宽高都增加根号时:
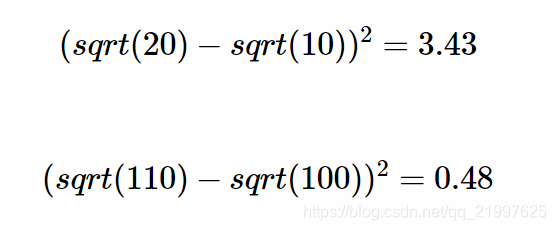
显然,对小框预测偏差10个像素带来了更高的损失。通过增加根号,使得预测相同偏差与更小的框产生更大的损失。但根据YOLOv2的实验证明,还有更好的方法解决这个问题。
(3) 若有物体落入边界框中,则计算预测边界框含有物体的置信度Ci和真实物体与边界框IoUCiˆ的损失,我们希望两差值越小损失越低。
(4) 若没有任何物体中心落入边界框中,则Ciˆ为0,此时我们希望预测含有物体的置信度Ci越小越好。然而,大部分边界框都没有物体,积少成多,造成loss的第3部分与第4部分的不平衡,因此,作才在loss的三部分增加权重λnobj=0.5 。
(5) 对于每个格子而言,作者设计只能包含同种物体。若格子中包含物体,我们希望希望预测正确的类别的概率越接近于1越好,而错误类别的概率越接近于0越好。loss第4部分中,若pi(c)ˆ中c为正确类别,则值为1,若非正确类别,则值为0。
参考译文
参考潜伏在代码中
2 YOLOv2
yolov1基础上的延续,新的基础网络,多尺度训练,全卷积网络,Faster-RCNN的anchor机制,更多的训练技巧等等改进使得yolov2速度与精度都大幅提升,改进效果如下图:
2.1 BatchNorm
Batchnorm是2015年以后普遍比较流行的训练技巧,在每一层之后加入BN层可以将整个batch数据归一化到均值为0,方差为1的空间中,即将所有层数据规范化,防止梯度消失与梯度爆炸,如:
0.930=0.04
加入BN层训练之后效果就是网络收敛更快,并且效果更好。YOLOv2在加入BN层之后mAP上升2%。
关于BN作用
2.2 预训练尺寸
yolov1也在Image-Net预训练模型上进行fine-tune,但是预训练时网络入口为224 x 224,而fine-tune时为448 x 448,这会带来预训练网络与实际训练网络识别图像尺寸的不兼容。yolov2直接使用448 x 448的网络入口进行预训练,然后在检测任务上进行训练,效果得到3.7%的提升。
2.3 更细网络划分
yolov2为了提升小物体检测效果,减少网络中pooling层数目,使最终特征图尺寸更大,如输入为416 x 416,则输出为13 x 13 x 125,其中13 x 13为最终特征图,即原图分格的个数,125为每个格子中的边界框构成(5 x (classes + 5))。需要注意的是,特征图尺寸取决于原图尺寸,但特征图尺寸必须为奇数,以此保存中间有一个位置能看到原图中心处的目标。
2.4 全卷积网络
为了使网络能够接受多种尺寸的输入图像,yolov2除去了v1网络结构中的全连层,因为全连接层必须要求输入输出固定长度特征向量。将整个网络变成一个全卷积网络,能够对多种尺寸输入进行检测。同时,全卷积网络相对于全连接层能够更好的保留目标的空间位置信息。
2.5 新基础网络
下图为不同基础网络结构做分类任务所对就的计算量,横坐标为做一次前向分类任务所需要的操作数目。可以看出作者所使用的darknet-19作为基础预训练网络(共19个卷积层),能在保持高精度的情况下快速运算。而SSD使用的VGG-16作为基础网络,VGG-16虽然精度与darknet-19相当,但运算速度慢。关于darknet-19基础网络速度
2.6 anchor机制
yolov2为了提高精度与召回率,使用Faster-RCNN中的anchor机制。以下为我对anchor机制使用的理解:在每个网格设置k个参考anchor,训练以GT anchor作为基准计算分类与回归损失。测试时直接在每个格子上预测k个anchor box,每个anchor box为相对于参考anchor的offset与w,h的refine。这样把原来每个格子中边界框位置的全图回归(yolov1)转换为对参考anchor位置的精修(yolov2)。
至于每个格子中设置多少个anchor(即k等于几),作者使用了k-means算法离线对voc及coco数据集中目标的形状及尺度进行了计算。发现当k = 5时并且选取固定5比例值的时,anchors形状及尺度最接近voc与coco中目标的形状,并且k也不能太大,否则模型太复杂,计算量很大。
2.7 新边界框预测方式
这部分没有看太懂,先占个坑,等以后明白了再来补,感觉应该是在弥补大小边界框回归误差损失的问题吧。这里发现有篇博文对这部分讲得挺仔细的。
2.8 残差层融合低级特征
为了使用网络能够更好检测小物体,作者使用了resnet跳级层结构,网络末端的高级特征层与前一层或者前几层的低级细粒度特征结合起来,增加网络对小物体的检测效果,使用该方法能够将mAP提高1%。
同样,在SSD检测器上也可以看出使用细粒度特征(低级特征)将进行小物体检测的思想,但是不同的是SSD直接在多个低级特征图上进行目标检测,因此,SSD对于小目标检测效果要优于YOLOv2,这点可以coco测试集上看出,因为coco上小物体比较多,但yolov2在coco上要明显逊色于ssd,但在比较简单的检测数据集voc上优于ssd。
2.9 多尺寸训练
yolov2网络结构为全卷积网络FCN,可以适于不同尺寸图片作为输入,但要满足模型在测试时能够对多尺度输入图像都有很好效果,作者训练过程中每10个epoch都会对网络进行新的输入尺寸的训练。需要注意的是,因为全卷积网络总共对输入图像进行了5次下采样(步长为2的卷积或者池化层), 所以最终特征图为原图的1/32。所以在训练或者测试时,网络输入必须为32的位数。并且最终特征图尺寸即为原图划分网络的方式。
译文参见
ref1
ref2比较明白
ref3