目录
上接(第一章:神经网络的基本概念)
本页主要内容包括:
- 第二章:神经网络编程的的基础知识
- 2.1常用的符号
- 2.2 logistic回归的模型理解
- 2.3 损失函数与成本函数
- 2.4梯度下降法
- 2.5导数(略)
- 2.6更多导数的例子(略)
- 2.7计算图(略)
- 2.8使用计算图求导(略)
- 2.9 logistic回归中的梯度下降法
- 2.10 m个样本的梯度下降
- 2.11 向量化
- 2.12向量化的更多例子
- 2.13向量化logistic回归(略)
- 2.14向量化logistic回归的梯度输出
- 2.15Python中的广播(broadcasting)
- 2.16关于python_numpy向量的说明
- 2.17jupyter_ipthon笔记本的快速指南(略)
- 2.18(选修)logistic损失函数的解释(略)
-
对应的编程作业练习
2.神经网络编程的基础知识
2.1常用的符号:
(x,y)——表示一个单独的训练样本,x作为特征向量输入,标签y值为0或1
m:{(x(1),y(1)),(x(2),y(2))……(x(m),y(m))}——训练集由m个样本组成
m_train——训练集样本数目
m_test——测试集样本数目

2.2logistic回归的模型理解:
1) 是一个用于监督学习问题中的学习算法,当输出是0/1时,则为一个二元分类问题;
2) 二分分类的问题的目标往往是训练出一个分类器,它以图片的特征向量作为x的输入,通过神经网络的解析可以得到输出结果y;
3) 以一个例子入手:输入一张图片,判断是不是猫。

通过分析我们采用线性回归的方式可以将x与y联系起来,故假设为:
y=σ(w^T*x+b)
w=(x1,x2,……xm)
w^T+b 表示w的转置x再加b,同时用sigmoid 函数(σ(x))限制w^T+b的值域为(0,1),正好符合要求输出y的值域要求,其图像是 S 型的。

而往往在实际应用中我们采用:
a=σ(θ^Tx)
θ在这里即为一个特征向量,由【θ0,θ1……,θnx】组成,
其中θ0=b;
总而言之,θ更像是将 w(权重)和 b(偏置)打包在了一起,
2.3损失函数与成本函数
2.3.1损失函数L(误差函数):
在单个训练样本中定义的,来衡量预测输出值a和实际y值的接近程度,用以衡量在单个训练样本上算法的表现情况。
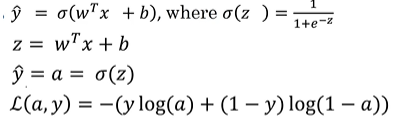

当损失函数L的值最小时,此时的θ为最优解。理解损失函数L的作用原理看如下两个示例:
a) 当y是1的时候,L=−log(a)。
此时我们要使L最小,就是使 a 最大。而a是由sigmoid 函数得出的,其最大值为 1,所以实际上此时的 a 在最优的情况下会接近 1。
b) 当y是0的时候,l=−log(1−a)。
同理,我们使L最小,则a最小,而sigmoid函数最小值为0,即使 a 无限接近0。
无论如何,我们都要使a尽可能接近 y。
2.3.2成本函数J:
为了衡量Logistic回归模型中的参数w与b的效果,并衡量模型在所有样本上的表现。我们用 x(i) 表示第 i 个样本的特征。

即:

成本函数J(w,b)是在水平轴w和b上的曲面,曲面的高度即为J(w,b)在某一点的值,在实际中我们需要找到这样的w,b使其对应的成本函数J值最小
2.4梯度下降法:
用来训练或学习训练集上的参数w和b,其核心就是——梯度下降法总是会朝着全局最小值方向移动,找到最小的J(w,b)

α在这里表示学习率,学习率可以控制每一次迭代或者梯度下降法中的步长,也可使用dw表示为: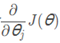
2.9logistic回归中的梯度下降法

想要使得预测输出值α与实际z值尽可能一致,我们需要使得J(w,b)向最优解移动,这个过程可以化简为:
①求出当前损失函数L对各变量的偏导数(以下“dx”形式看作用于存储数值的变量名):
对a的偏导数"da"da=dL(a,y)/da=-y/a+(1-y)/(1-a)
对z的偏导数"dz"=dL/dz=(dL/da)*(da/dz)=a-y
//注:da/dz=a(1-a)
对w1的偏导数:dL/dw1=(dL/dz)*(dz/dw1)="dz"*x1
对w2的偏导数:dL/dw2="dz"*x2
……(实际运用中输入的特征向量可能不止w1、w2)
对b的偏导数:db="dz"
②更新各项数值进行迭代(下列式子中θ对应w)
Repeat until convergence{

}(同时更新所有的θj)
将J(θ)带入上述更新公式中求出偏导数项,有:
Repeat until convergence{

}(同时更新所有θ j)
其中:
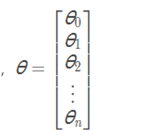
2.10m个样本的梯度下降
①初始化
②迭代更新

2.11向量化
在面对大型数据集时,尽可能使用向量化函数可以避免for循环带来的低效

向量化:z=np.dot(w,x)+b
在Jupyter notebook上对向量化与非向量化的差别的例子:

补充:可扩展深度学习实现是在GPU(图像处理单元)上做的,而视频中的jupter notebook是在CPU上运行的,两者都具有并行化的指令(SIMD,意思为单指令流多数据流),但GPU更加擅长SIMD计算
2.12向量化的更多例子
引入numpy库:import numpy as np
2.14向量化logistic回归的梯度输出
原始的for循环的梯度更新:

向量化取代其中的for循环可以这么做:
{
Z=np.dot(w^T*x)+b
A=sigmoid(Z)
"dZ"=A-Y(推导过程见2.9)
"dw"=1/m*X("dZ")^T
"db"=1/m*np.sum("dZ")
更新梯度:
w:=w-α"dw"//α是学习率
b:=b-α"db"//:=是赋值符号}
为一次完整的梯度下降迭代
2.15Python中的广播(broadcasting)
广播是一种让python代码执行更快的手段。
示例如下:

步骤:
①令这个矩阵等于3*4矩阵A
②对各列进行求和得到四个数字,分别对应四种不同事物的卡路里,再求出总量
③让四列每一列都除以对应的和
Python代码表现:
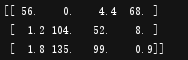
import numpy as np
A=np.array([[56.0,0.0,4.4,68.0],
[1.2,104.0,52.0,8.0],
[1.8,135.0,99.0,0.9]])
print(A)
cal=A.sum(axis=0)#axis=0意味着竖直相加,axis=1意味着水平相加
print(cal)
percentage=100*A/cal.reshape(1,4)
#reshape可以规范矩阵的行与列,实际上这个函数会以目标矩阵为模板,对当前欠缺的矩阵进行补齐或者删减
print(percentage)
输出:
①print(A)
②print(cal)

③print(percentage)

2.16关于python_numpy向量的说明
①注意在设置向量数组秩为1的数组时:
a=np.random.randn(5,1)#会得到51的列向量
a.T#会得到15的行向量
② assert():用于确定一个向量具体的维度是多少