1.卷积层(Convolutional Layer)
"卷积"的“卷”指的是 num_channel通道数, 经过卷积后size减小,输出层深度为卷积核个数。
① 为什么要用卷积?
19世纪60年代,科学家通过对猫的视觉皮层细胞研究发现,每一个视觉神经元只会处理一小块区域的视觉图像,即感受野(Receptive Field)。卷积神经网络的概念即出自于此。说简单这样做保留了图像的空间信息。
图像具有很强的空间相关性。其中每一个卷积核滤波得到的图像就是一类特征的映射,即一个特征图。
② 为什么卷积核(又称过滤器、感受野)常取奇数size?
-
保护位置信息:保证了 锚点 刚好在中间,方便以模块中心为标准进行滑动卷积,避免了位置信息发生 偏移 。
-
padding时对称:保证了 padding 时,图像的两边依然相 对称 。
池化层过滤器不一定取奇数
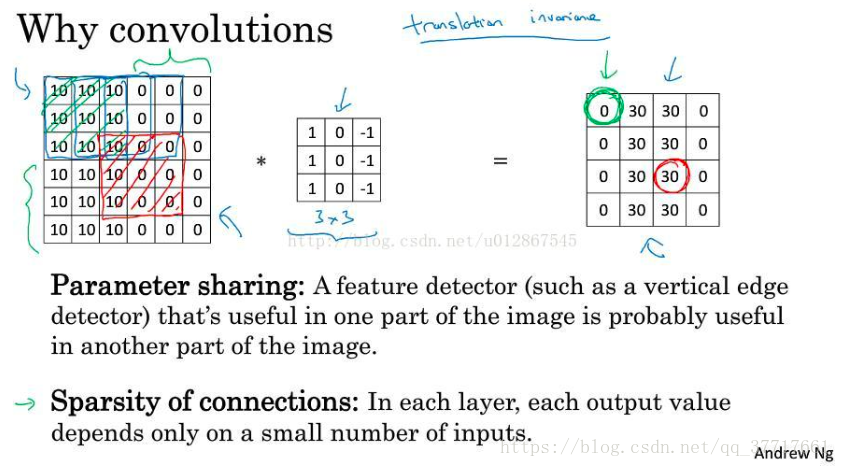
③ 卷积神经网络有2大优点:
1、参数共享:极大地减少参数数量。每个特征检测器都可以在输入图片的不同区域使用相同的参数,而且不仅适用于提取垂直或水平等低阶特征,还适用于鼻子、眼睛等高阶特征。
2、稀疏连接:在每一层,每个输出的值仅仅依赖于输入的很小一部分。如:绿框0只依赖于输入的绿框,红框30只依赖于输入的红框。把大的图像拆分成一个个小块来学习。
④1 * 1 卷积核的作用
-
降维或升维:通过卷积核的个数来改变网络的深度。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。如果filter个数为200则结果大小为500*500*200。
-
引入非线性:从而使输入层的通道数减少或保持不变,提升网络的表达能力
⑤ CNN的发展史 详细
1. 1986年 Lenet
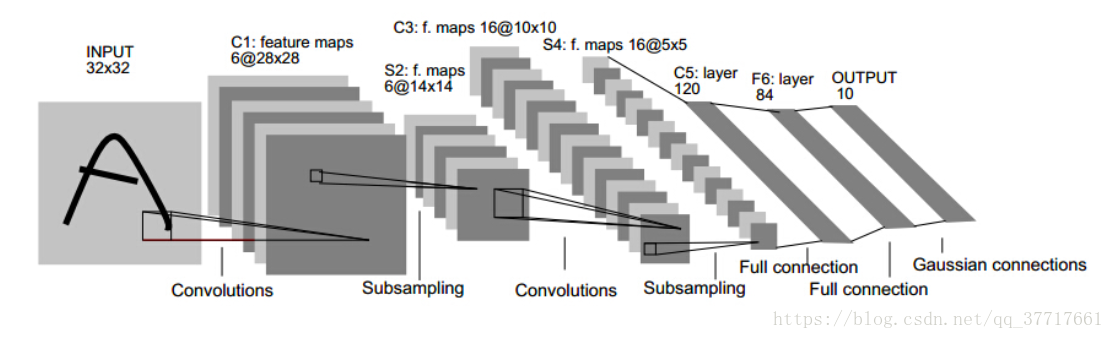
conv1 + pool1 + conv2 + pool2 + fc1 + fc2 + output ,一般是七层,习惯池化层跟在卷积层之后
2. 2012年 Imagenet比赛冠军的model —— Alexnet

证明了CNN在复杂模型下的有效性,让CNN和GPU大火了一把,推动了有监督DL 的发展。
Alexnet有一个特殊的计算层,LRN 层,做的事是对当前层的输出结果做平滑处理。
3. 2014年 Imagenet比赛冠军的model —— GoogleNet
习惯采用并行卷积
GoogleNet 证明了一件事:用更多的卷积,更深的层次可以得到更好的结构
这个model基本上构成部件和alexnet差不多,不过中间有好几个inception的结构:

4. 2014年 VGG

特点也是连续(串行)卷积多,参数量巨大
5.2014年 Imagenet比赛冠军的model —— ResNet 残差网络

模型构成简单,连LRN这样的层都没有了。
特点在于设计了block,可以跨层连接,缓解了网络过深导致的梯度爆炸、梯度消失。

残差网络能起作用的原因: 如果采用了权重衰减,如图有可能z[l+2]这一项为0,那么a[l+2] = a[l] ,因此残差网络等价于浅层网络融合,所以残差网络无论放在神经网络的中间还是末端都不会影响网络性能。

2.垂直边缘检测

上图中的上测原始图是由亮到暗,所以最后的结果[0,30,30,0]表示检测到的垂直边缘是30,比较亮,代表由亮过渡到暗。
上图中的下测原始图是由暗到亮,所以最后的结果[0,-30,-30,0]表示检测到的垂直边缘是-30,比较暗,代表由暗过渡到亮。


上图的上测表示的索贝尔和scharr过滤器。上图下侧表示我们可以不用前人的参数,而是可以通过反向传播不断更新得到参数,那样不仅可以检测出垂直,水平,任意角度的边缘都可以检测出来。
3. 填充 padding

什么是padding? padding就是在图像周围填充像素,padding = 1填充1圈,padding = 2填充2圈。
那么为什么需要填充呢?由于卷积的两个缺点:
①输出可能变得非常小(假设没有padding,那么每回卷积运算后,图像都会变小,那么在n层以后,图像就会变得非常非常小)
②容易丢失边缘信息
有2种卷积操作“有效”和“相同”:
有效就是无填充,输入维度N X N的,过滤器维度F X F,输出维度(N-F + 1)X(N-F + 1);
相同就是有填充,输出的大小和输入的大小相同,并且相同的过滤器 f 维度通常都是奇数,输入维度n X n的,过滤器维度f X f,输出维度(N + 2P-F + 1)X(N + 2P-F + 1)X num_channel。
padding两种用法:
①计算输出维度时因除以步长为小数,用来补齐
②当s=1时,p一般取 (f-1)/2 可以使输入、输出层size不变
4. 步长 stride

卷积的步长可以改变,如之前的步长为1,当我们改为2后,如上图所示,做卷积运算右移时,移动2步,由红框移动到绿框,由绿框移动到紫框
输出维度

由于池化层没有参数,可以将卷积层、池化层看作一层,例如: layer1 :conv1 + pool1
5.池化层 (Pooling Layer)
主要作用:缩减模型大小(size),提高计算速度,同时提高所提取特征的鲁棒性,但是其深度(通道数)不变。
主要形式:① 平均池化 ; ② 最大池化
常用参数:① f = 2 ,s = 2 (更常用可以把size减半,证明(n-2+0)/2+1=n/2); ② f = 3 ,s = 2
输出形式:

6. 全连接层
主要作用:用于输出部分的处理,和上一层所有节点相连,把卷积结果拉平,把前面提取到的特征综合起来。
被 全卷积层 替代 ~~~~~~~待补充
被 1*1 卷积核替代~~~~~~待补充
7.Inception 网络
作用:代替人工决定卷积层中过滤器的类型。消除尺寸对于识别结果的影响,一次性使用多个不同filter size来抓取多个范围不同的概念,并让网络自己选择需要的特征。
输入(可以是被卷积完的长方体输出作为该层的输入)进来后,通常我们可以选择直接使用像素信息(1x1 卷积)传递到下一层,可以选择3x3卷积,可以选择5x5卷积,还可以选择max pooling的方式 downsample刚被卷积后的feature maps。 但在实际的网络设计中,究竟该如何选择需要大量的实验和经 验的。 Inception就不用我们来选择,而是将4个选项给神经网络,让网络自己去选择最合适的解决方案。
