1.逻辑回归为什么用对数不用平方?
平方求解的最优化问题可能变成非凸的,得不到全局最优解,对数损失对应于二项分布,解决分类问题更合适。
对LR损失函数的解释:
∵预测值y_hat 表示预测为1的概率,y表示标签值
∴y=0时,p(y|x)=1-y_hat; y=1时,p(y|x) = y_hat
又∵对数函数严格单调递增,优化p(y|x)等价于优化logp(y|x)
∴logp(y|x) = log((y_hat^y)*((1-y_hat)^(1-y))) = ylogy_hat+(1-y)log(1-y_hat)
前面加负号是因为要最小化损失函数
2.激活函数
1)sigmoid
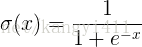
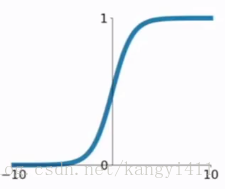
可用作二元分类输出的激活函数.
2)tanh
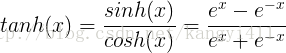
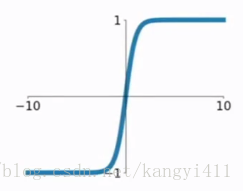
sigmoid取值范围(0,1),参数梯度同号,而tanh取值以0为均值,更容易得到最优解。
3)ReLU
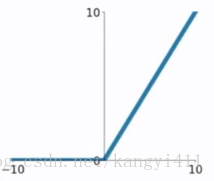
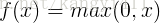
相比于前两个函数,优点:
①输入为正数时,不存在梯度饱和问题,sigmoid和tanh太过平滑
②输入为负数时,输出都设为0,增加稀疏性,缓解过拟合
③线性计算比指数计算快
缺点:
如果输入为负数,某些区域又比较敏感的情况下,可能存在梯度消失问题
ReLU之后,通常加BN层,尽可能保证每层属于同一分布
4)Leaky ReLU
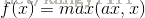
Leaky ReLU为ReLU的改进型,在输入为负数时,避免梯度消失。
引用https://blog.csdn.net/kangyi411/article/details/78969642
3.神经网络中为什么要引入非线性激活函数?
如果不用激活函数(其实相当于激活函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
4.神经网络中为什么参数W要随机初始化,b不用?
因为如果W初始化为0 则对于任何Xi,每个隐藏层对应的每个神经元的输出都是相同的,这样即使梯度下降训练,无论训练多少次,这些神经元都是对称的,无论隐藏层内有多少个结点,都相当于在训练同一个函数。
而b不存在对称性问题,可以用0初始化。