Shallow Neural Network
Neural Networks Overview
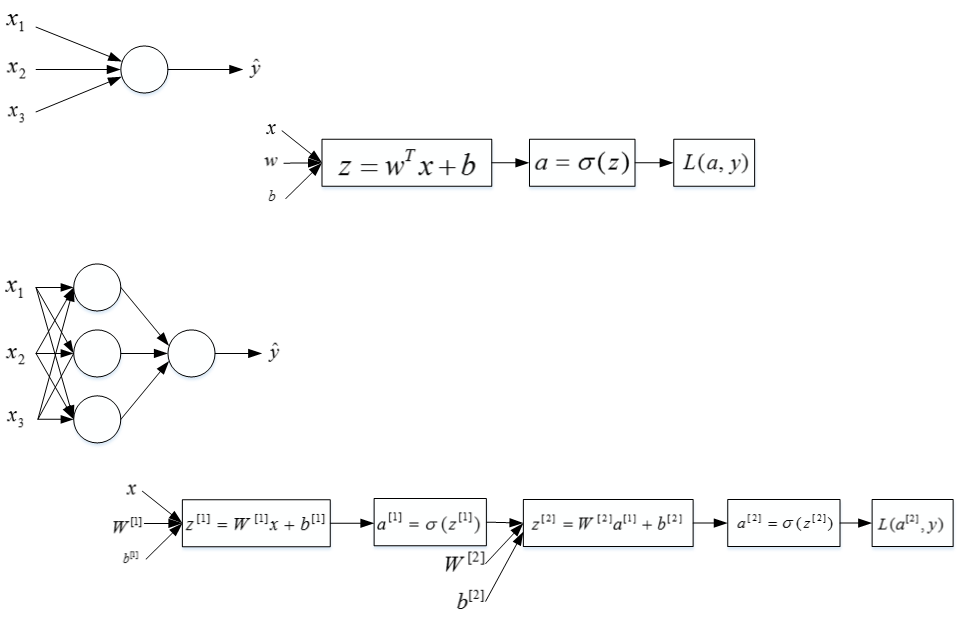
同样,反向传播过程也分成两层。第一层是输出层到隐藏层,第二层是隐藏层到输入层。其细节部分我们之后再来讨论。
Neural Network Representation
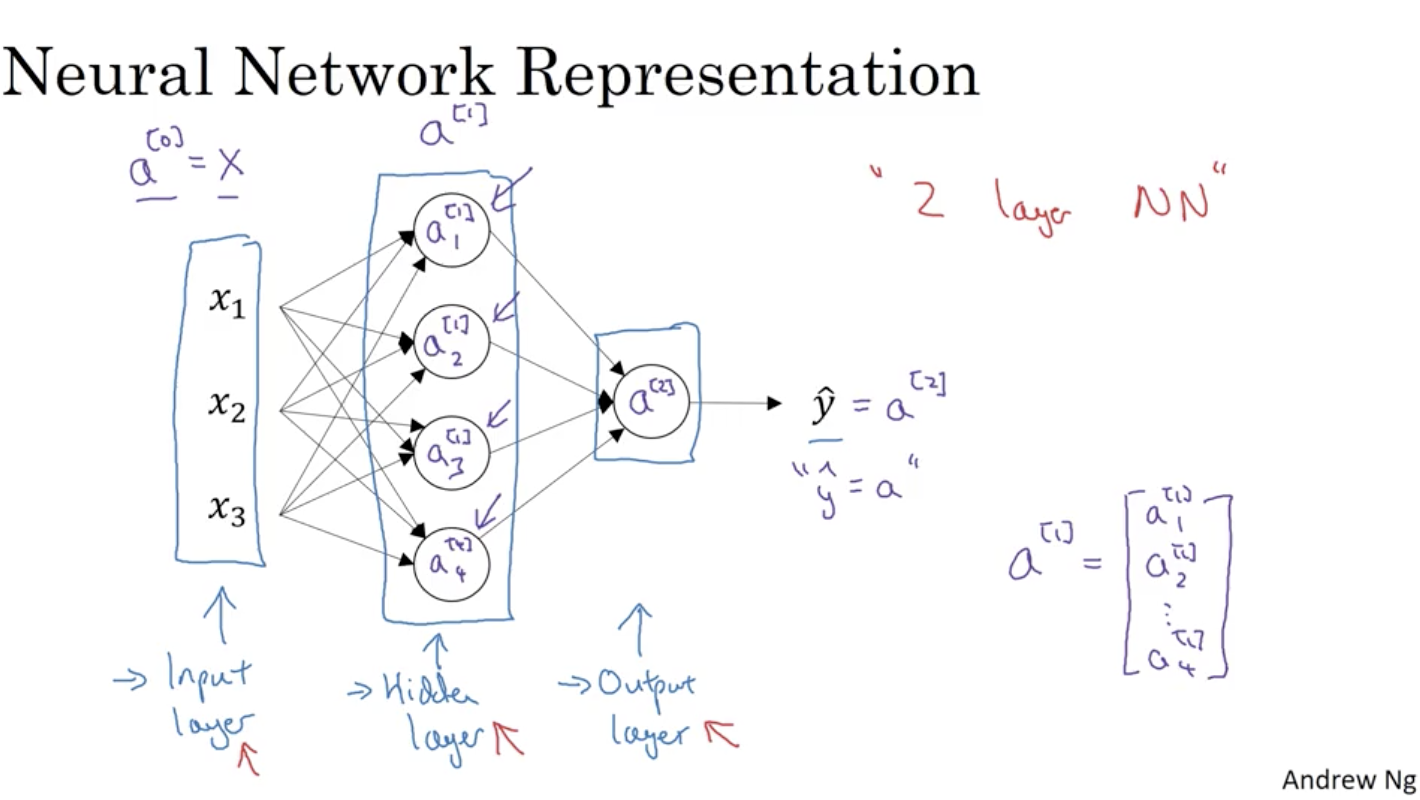
在神经网络中,我们以相邻两层为观测对象,前面一层作为输入,后面一层作为输出,两层之间的w参数矩阵大小为 ,b参数矩阵大小为 ,这里是作为 的线性关系来说明的,在神经网络中, 。
在logistic regression中,一般我们都会用 来表示参数大小,计算使用的公式为: ,要注意这两者的区别。
Computing a Neural Network’s Output
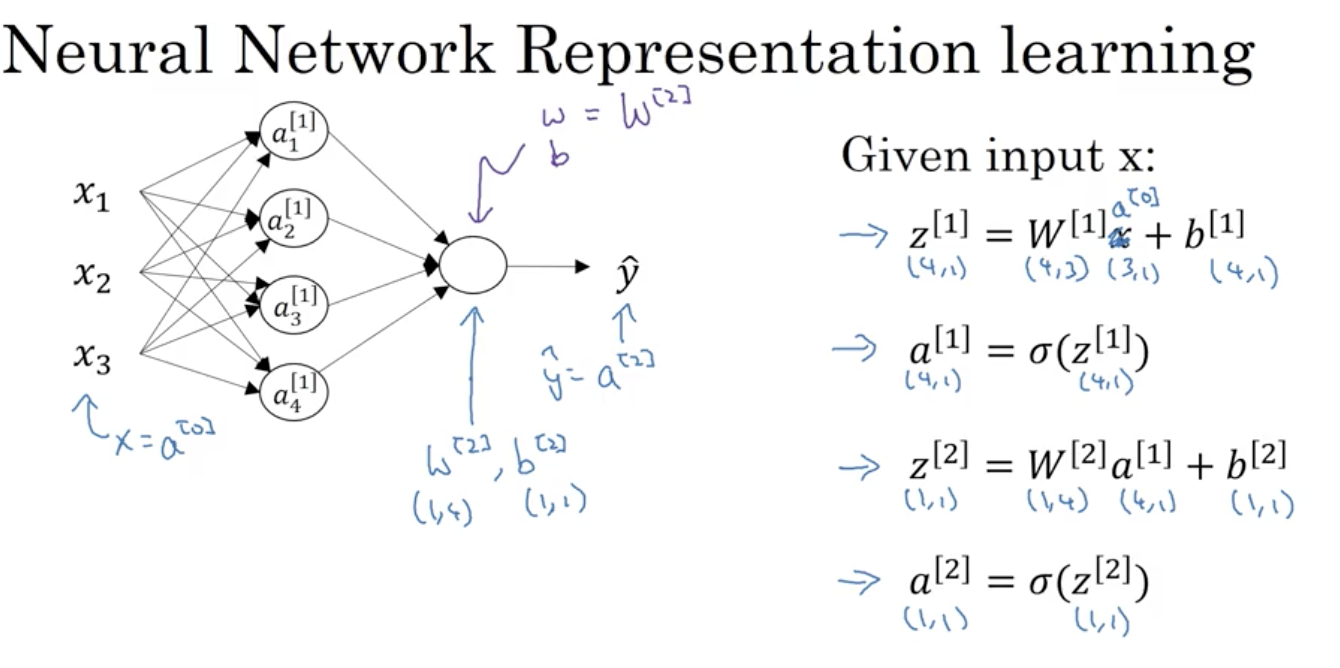
Vectorizing across multiple examples

Explanation for Vectorized Implementation
这部分Andrew用图示的方式解释了m个样本的神经网络矩阵运算过程。其实内容比较简单,只要记住上述四个矩阵的行表示神经元个数,列表示样本数目m就行了。
值得注意的是输入矩阵X也可以写成 。
Activation functions
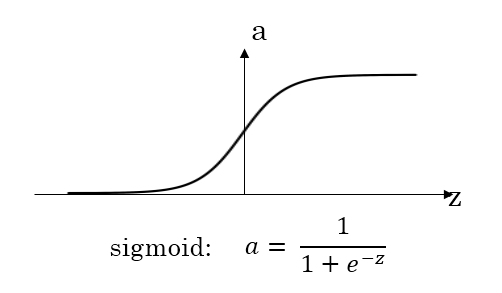
- sigmoid function
- tanh function
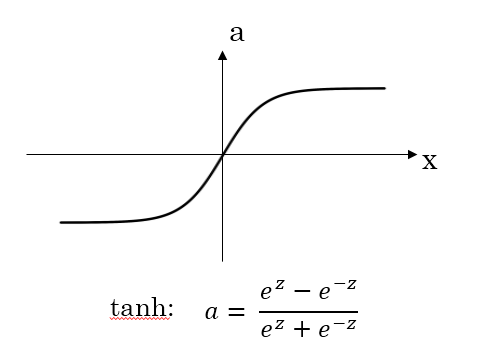
- ReLU function
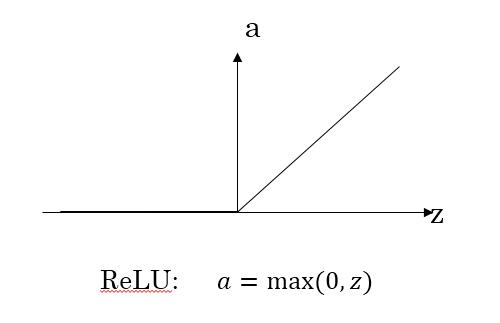
- Leaky ReLU函数
激活函数的选择:
sigmoid函数和tanh函数比较:
- 隐藏层:tanh函数的表现要好于sigmoid函数,因为tanh取值范围为[−1,+1],输出分布在0值的附近,均值为0,从隐藏层到输出层数据起到了归一化(均值为0)的效果。
- 输出层:对于二分类任务的输出取值为{0,1},故一般会选择sigmoid函数。
然而sigmoid和tanh函数在当|z|很大的时候,梯度会很小,在依据梯度的算法中,更新在后期会变得很慢。在实际应用中,要使|z|尽可能的落在0值附近,从而提高梯度下降算法运算速度。
ReLU弥补了前两者的缺陷,当z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当z<0时,梯度一直为0,但是实际的运用中,该缺陷的影响不是很大。
Leaky ReLU保证在z<0的时候,梯度仍然不为0。
最后总结一下,如果是分类问题,输出层的激活函数一般会选择sigmoid函数。但是隐藏层的激活函数通常不会选择sigmoid函数,tanh函数的表现会比sigmoid函数好一些。实际应用中,通常会会选择使用ReLU或者Leaky ReLU函数,保证梯度下降速度不会太小。其实,具体选择哪个函数作为激活函数没有一个固定的准确的答案,应该要根据具体实际问题进行验证。
Why do you need non-linear activation functions?

从上图可以看出,如果令a=z,那么最后得到的 经过化简还是一个线性组合。这表明,使用神经网络与直接使用线性模型的效果并没有什么两样。即便是包含多层隐藏层的神经网络,如果使用线性函数作为激活函数,最终的输出仍然是输入x的线性模型。这样的话神经网络就没有任何作用了。因此,隐藏层的激活函数必须要是非线性的。
另外,如果所有的隐藏层全部使用线性激活函数,只有输出层使用非线性激活函数,那么整个神经网络的结构就类似于一个简单的逻辑回归模型,而失去了神经网络模型本身的优势和价值。
值得一提的是,如果是预测问题而不是分类问题,输出y是连续的情况下,输出层的激活函数可以使用线性函数。如果输出y恒为正值,则也可以使用ReLU激活函数,具体情况,具体分析。
Derivatives of activation functions
sigmoid导数:
tanh导数:
relu导数:
Leaky relu导数:
Gradient descent for Neural Networks

Random Initialization
如果在初始时,两个隐藏神经元的参数设置为相同的大小,那么两个隐藏神经元对输出单元的影响也是相同的,通过反向梯度下降去进行计算的时候,会得到同样的梯度大小,所以在经过多次迭代后,两个隐藏层单位仍然是对称的。无论设置多少个隐藏单元,其最终的影响都是相同的,那么多个隐藏神经元就没有了意义。
在初始化的时候,W参数要进行随机初始化,b则不存在对称性的问题它可以设置为0。
以2个输入,2个隐藏神经元为例:
W = np.random.rand((2,2))* 0.01
b = np.zero((2,1))
这里我们将W的值乘以0.01是为了尽可能使得权重W初始化为较小的值,这是因为如果使用sigmoid函数或者tanh函数作为激活函数时,W比较小,则 所得的值也比较小,处在0的附近,0点区域的附近梯度较大,能够大大提高算法的更新速度。而如果W设置的太大的话,得到的梯度较小,训练过程因此会变得很慢。
ReLU和Leaky ReLU作为激活函数时,不存在这种问题,因为在大于0的时候,梯度均为1
Summary
本节课主要介绍了浅层神经网络。首先,我们简单概述了神经网络的结构:包括输入层,隐藏层和输出层。然后,我们以计算图的方式推导了神经网络的正向输出,并以向量化的形式归纳出来。接着,介绍了不同的激活函数并做了比较,实际应用中根据不同需要选择合适的激活函数。激活函数必须是非线性的,不然神经网络模型起不了任何作用。然后,我们重点介绍了神经网络的反向传播过程以及各个参数的导数推导,并以矩阵形式表示出来。最后,介绍了权重随机初始化的重要性,必须对权重W进行随机初始化操作。