文章目录
Unsupervised Learning: Generation
本文将简单介绍无监督学习中的生成模型,包括PixelRNN、VAE和GAN,以后将会有一个专门的系列介绍对抗生成网络GAN
Introduction
正如Richard Feynman所说,“What I cannot create, I do not understand”,我无法创造的东西,我也无法真正理解,机器可以做猫狗分类,但却不一定知道“猫”和“狗”的概念,但如果机器能自己画出“猫”来,它或许才真正理解了“猫”这个概念
这里将简要介绍:PixelRNN、VAE和GAN这三种方法
PixelRNN
Introduction
RNN可以处理长度可变的input,它的基本思想是根据过去发生的所有状态去推测下一个状态
PixelRNN的基本思想是每次只画一个pixel,这个pixel是由过去所有已产生的pixel共同决定的
这个方法也适用于语音生成,可以用前面一段的语音去预测接下来生成的语音信号
总之,这种方法的精髓在于根据过去预测未来,画出来的图一般都是比较清晰的
pokemon creation
用这个方法去生成宝可梦,有几个tips:
-
为了减少运算量,将40×40的图像截取成20×20
-
如果将每个pixel都以[R, G, B]的vector表示的话,生成的图像都是灰蒙蒙的,原因如下:
-
亮度比较高的图像,一般都是RGB值差距特别大而形成的,如果各个维度的值大小比较接近,则生成的图像偏向于灰色
-
如果用sigmoid function,最终生成的RGB往往都是在0.5左右,导致色彩度不鲜艳
-
解决方案:将所有色彩集合成一个1-of-N编码,由于色彩种类比较多,因此这里先对类似的颜色做clustering聚类,最终获得了167种色彩组成的向量
我们用这样的向量去表示每个pixel,可以让生成的色彩比较鲜艳
-
相关数据连接如下:
使用PixelRNN训练好模型之后,给它看没有被放在训练集中的3张图像的一部分,分别遮住原图的50%和75%,得到的原图和预测结果的对比如下:
VAE
VAE全称Variational Autoencoder,可变自动编码器
Introduction
前面的文章中已经介绍过Autoencoder的基本思想,我们拿出其中的Decoder,给它随机的输入数据,就可以生成对应的图像
但普通的Decoder生成效果并不好,VAE可以得到更好的效果
在VAE中,code不再直接等于Encoder的输出,这里假设目标降维空间为3维,那我们使Encoder分别输出 m 1 , m 2 , m 3 m_1,m_2,m_3 m1,m2,m3和 σ 1 , σ 2 , σ 3 \sigma_1,\sigma_2,\sigma_3 σ1,σ2,σ3,此外我们从正态分布中随机取出三个点 e 1 , e 2 , e 3 e_1,e_2,e_3 e1,e2,e3,将下式作为最终的编码结果:
c i = e σ i ⋅ e i + m i c_i = e^{\sigma_i}\cdot e_i+m_i ci=eσi⋅ei+mi

此时,我们的训练目标不仅要最小化input和output之间的差距,还要同时最小化下式:
∑ i = 1 3 ( 1 + σ i − ( m i ) 2 − e σ i ) \sum\limits_{i=1}^3 (1+\sigma_i-(m_i)^2-e^{\sigma_i}) i=1∑3(1+σi−(mi)2−eσi)
与PixelRNN不同的是,VAE画出的图一般都是不太清晰的,但在某种程度上我们可以控制生成的图像
write poetry
VAE还可以用来写诗,我们只需要得到某两句话对应的code,然后在降维后的空间中得到这两个code所在点的连线,从中取样,并输入给Decoder,就可以得到类似下图中的效果

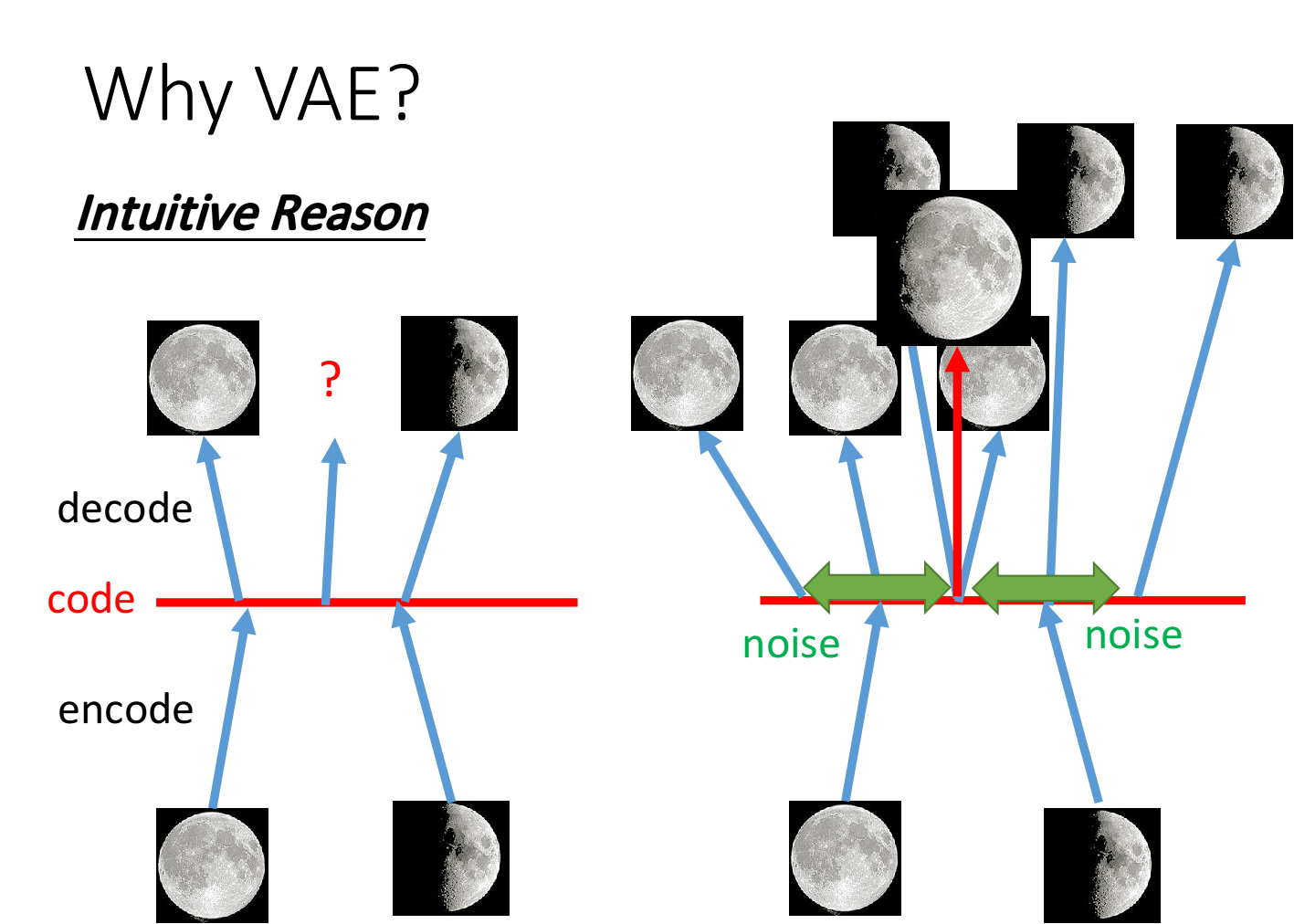
Why VAE?
VAE和传统的Autoencoder相比,有什么优势呢?
事实上,VAE就是加了噪声noise的Autoencoder,它的抗干扰能力更强,过渡生成能力也更强
对原先的Autoencoder来说,假设我们得到了满月和弦月的code,从两者连线中随机获取一个点并映射回原来的空间,得到的图像很可能是完全不一样的东西
而对VAE来说,它要保证在降维后的空间中,加了noise的一段范围内的所有点都能够映射到目标图像,如下图所示,当某个点既被要求映射到满月、又被要求映射到弦月,则它最终映射出来的结果就很有可能是两者之间的过渡图像
再回过来头看VAE的结构,其中:
-
m i m_i mi其实就代表原来的code
-
c i c_i ci则代表加了noise以后的code
-
σ i \sigma_i σi代表了noise的variance,描述了noise的大小,这是由NN学习到的参数
注:使用 e σ i e^{\sigma_i} eσi的目的是保证variance是正的
-
e i e_i ei是正态分布中随机采样的点
注意到,损失函数仅仅让input和output差距最小是不够的,因为variance是由机器自己决定的,如果不加以约束,它自然会去让variance=0,这就跟普通的Autoencoder没有区别了

额外加的限制函数解释如下:
下图中,蓝线表示 e σ i e^{\sigma_i} eσi,红线表示 1 + σ i 1+\sigma_i 1+σi,两者相减得到绿线
绿线的最低点 σ i = 0 \sigma_i=0 σi=0,则variance e σ i = 1 e^{\sigma_i}=1 eσi=1,此时loss最低
而 ( m i ) 2 (m_i)^2 (mi)2项则是对code的L2 regularization,让它比较sparse,不容易过拟合

关于VAE原理的具体推导比较复杂,这里不再列出
problems of VAE
VAE有一个缺点,它只是在努力做到让生成的图像与数据集里的图像尽可能相似,却从来没有想过怎么样真的产生一张新的图像,因此由VAE生成的图像大多是数据集中图像的线性变化,而很难自主生成全新的图像
VAE做到的只是模仿,而不是创造,GAN的诞生,就是为了创造
GAN
GAN,对抗生成网络,是近两年非常流行的神经网络,基本思想就像是天敌之间相互竞争,相互进步
GAN由生成器(Generator)和判别器(Discriminator)组成:
- 对判别器的训练:把生成器产生的图像标记为0,真实图像标记为1,丢给判别器训练分类
- 对生成器的训练:调整生成器的参数,使产生的图像能够骗过判别器
- 每次训练调整判别器或生成器参数的时候,都要固定住另一个的参数
GAN的问题:没有明确的训练目标,很难调整生成器和判别器的参数使之始终处于势均力敌的状态,当两者之间的loss很小的时候,并不意味着训练结果是好的,有可能它们两个一起走向了一个坏的极端,所以在训练的同时还必须要有人在旁边关注着训练的情况
以后将会有GAN系列的文章介绍,本文不再做详细说明