在前面的博客中介绍了监督学习和半监督学习,本篇博客将开始介绍无监督学习。
目录
Hierarchical Agglomerative Clustering (HAC)
Principle Component Analysis (PCA)
无监督学习介绍
监督学习、半监督学习、无监督学习
- 监督学习中的样本
中的
是已知的,所以监督学习算法可以在训练集数据中充分使用数据的信息
- 半监督学习的样本
中只有R个样本的
-
Transductive learning :将未知标签的数据作为测试集数据(用了未知标签的数据的feature)
-
Inductive learning:未知标签的数据不作为测试集数据
-
无监督学习的样本
中的
无监督学习的用处
-
聚类(Clustering) 和降维( Dimension Reduction)
-
Generation
聚类(Clustering)
K均值聚类
- 将
样本聚合成K个类
- 初始化类中心
,
- 重复
-
利用
-
利用分好的K个类中的样本重新算出每一个类的
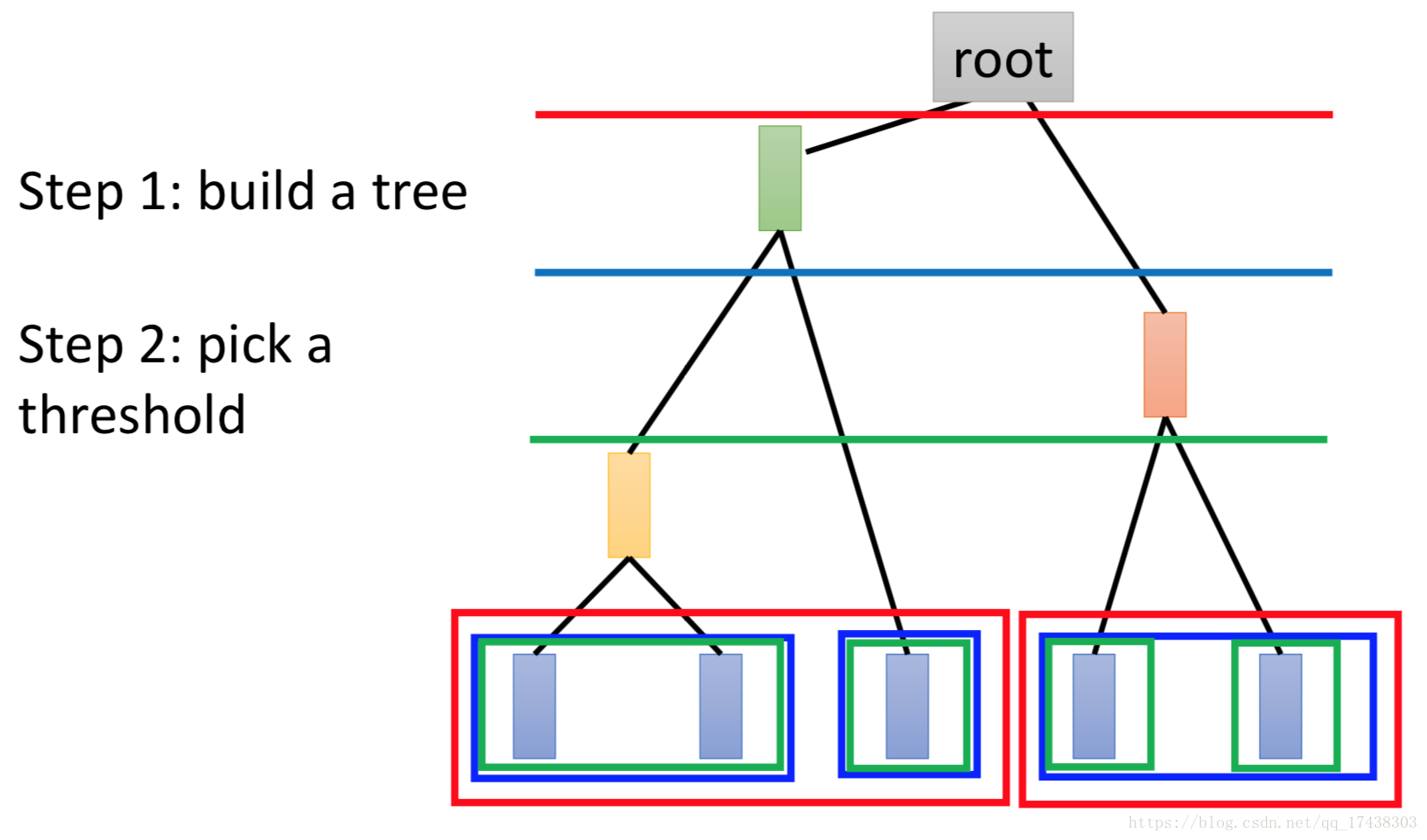
Hierarchical Agglomerative Clustering (HAC)
假设有5个样本,计算两两之间的相似度,将最相似的两个样本聚合在一起(比如第一个和第二个),再将剩下的4个聚合在一起,以此类推。
降维( Dimension Reduction)
Feature selection
直接按照特征的分布来选取有分布的特征。
Principle Component Analysis (PCA)
PCA介绍
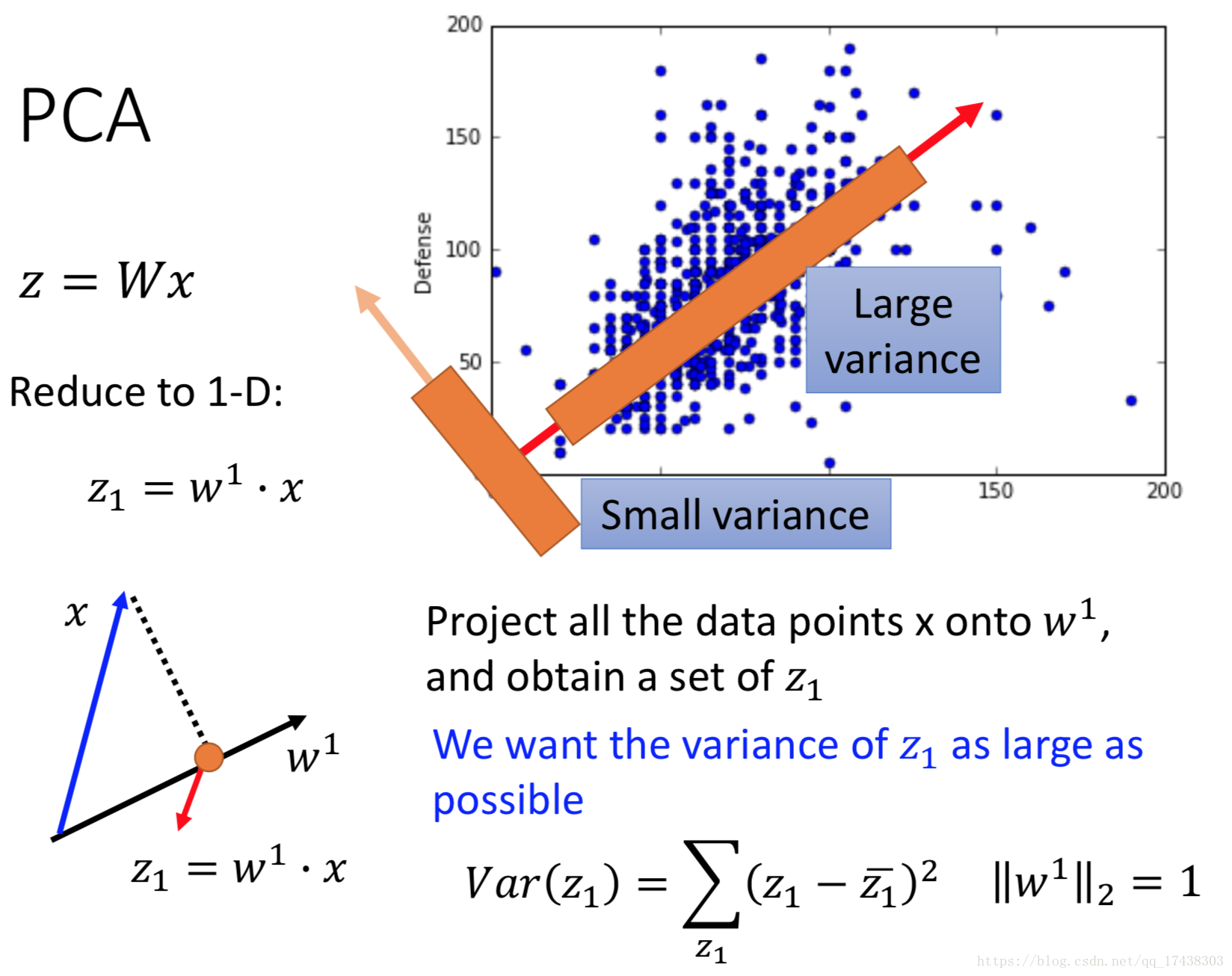
现在举一个从二维数据降到一维的情况,表示
在
向量上的投影,我们希望找到
使得样本投影在这一向量上的点的分布方差最大,如图,我们选择Large variance这一向量。
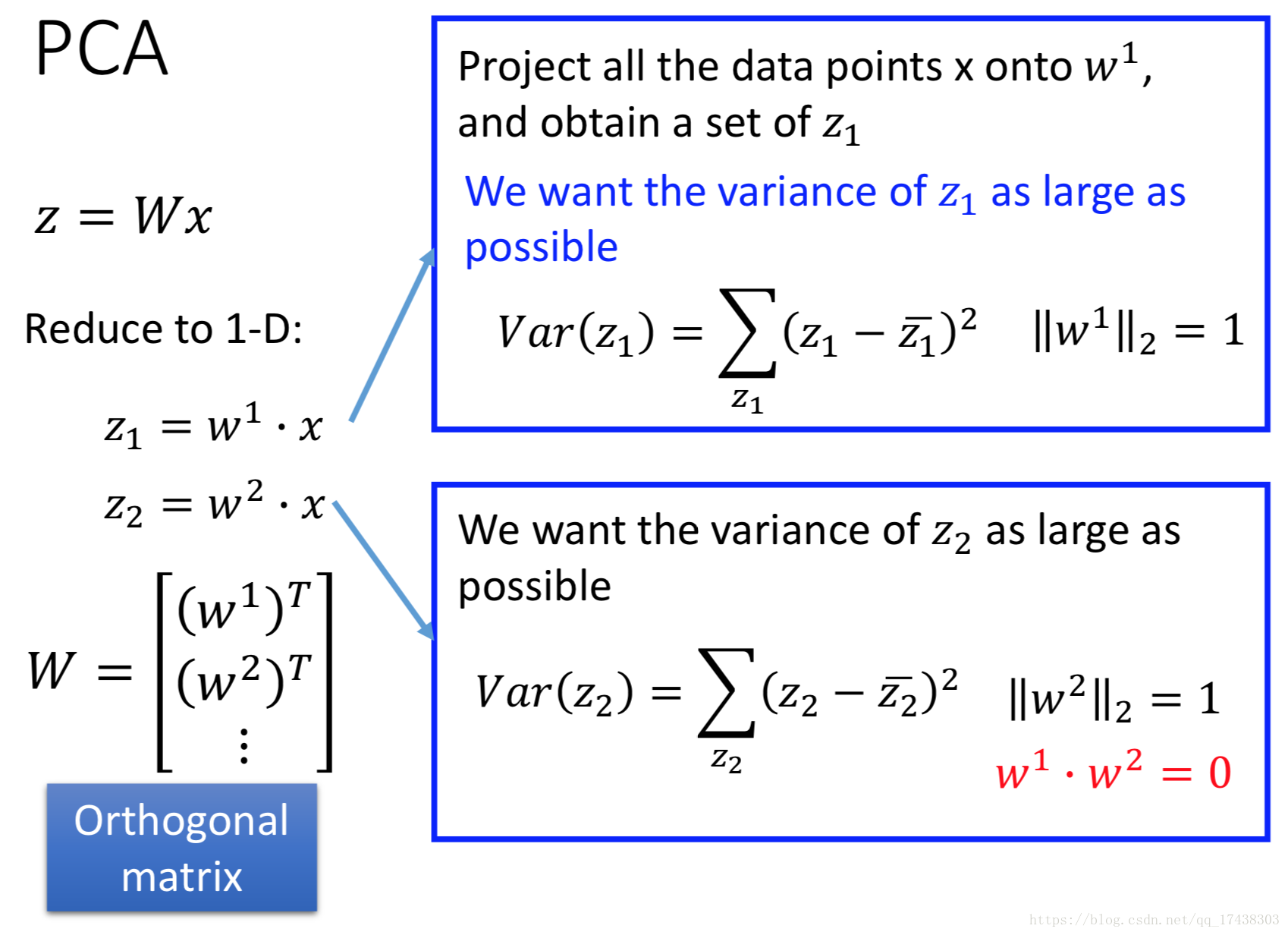
现在考虑高维的情况,此时同样的思路也是找到相互垂直的,使得
分布方差最大。
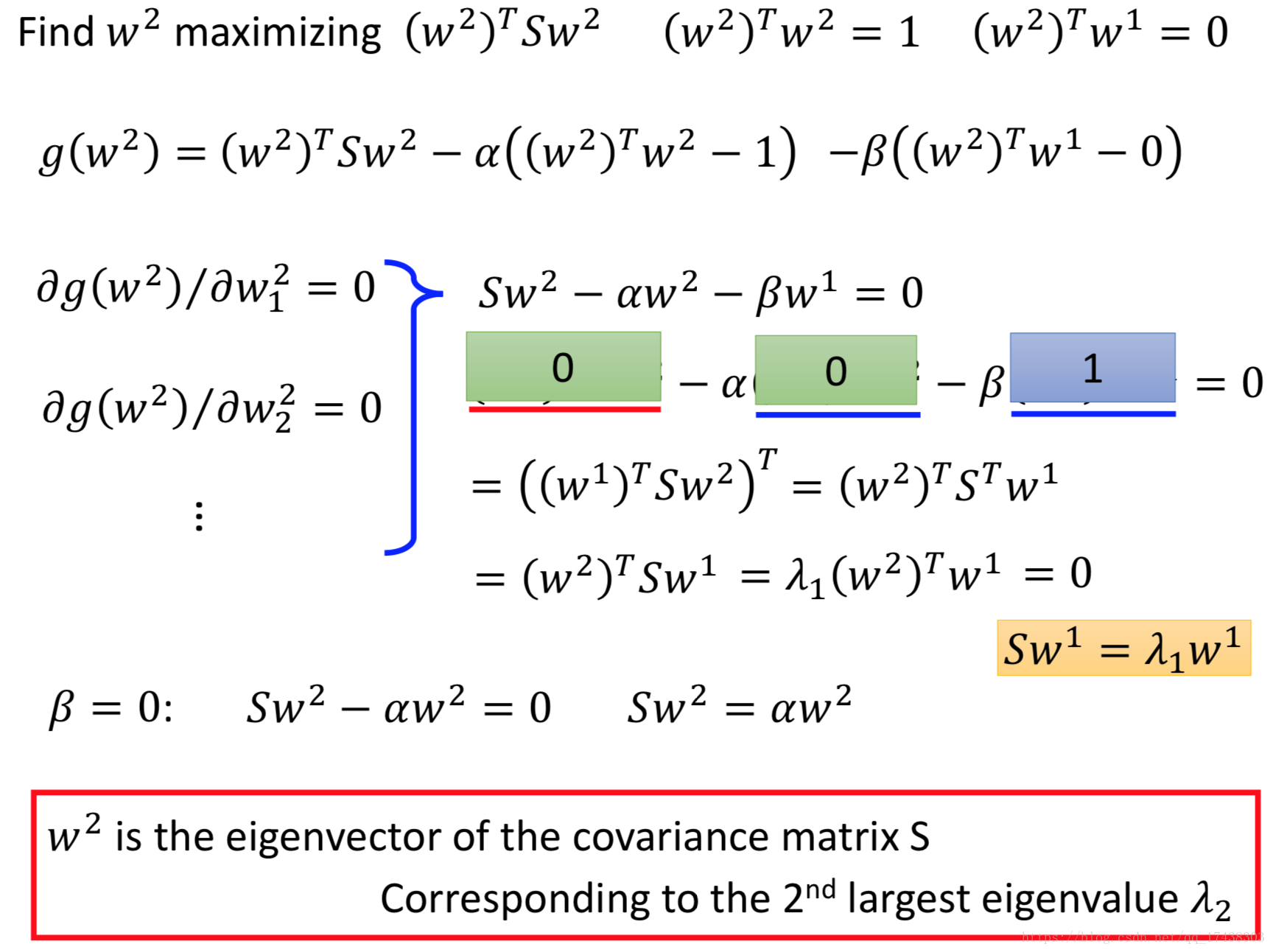
W求解
接下来推导如何计算,先计算
:


接下来计算,同样也是极大化
:
PCA-decorrelation
降维之后的之间彼此是互相垂直的(
是一个对角矩阵),由此得出的结果再作为其他模型的输入,可以大大减少模型的参数。

PCA-NN
PCA可以看作是一个一层的神经网络,我们现在找到了,图中
表示误差,则可以表示为图中的神经网络(3维降为2维)。
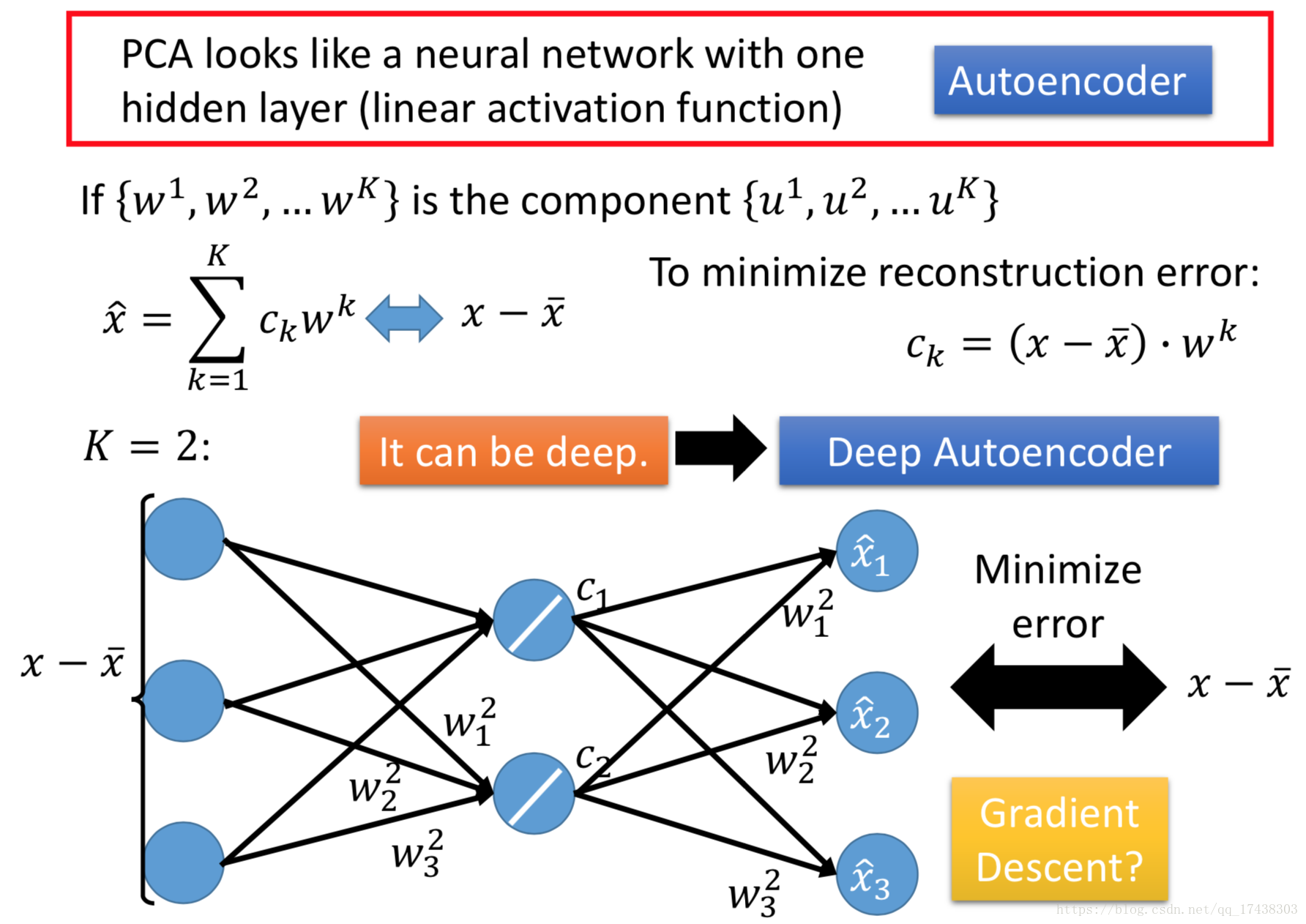
直接用Gradient Descent训练出来的w和PCA中的不一样,因为PCA中的w一定是垂直的,Gradient Descent训练出来的w不一定
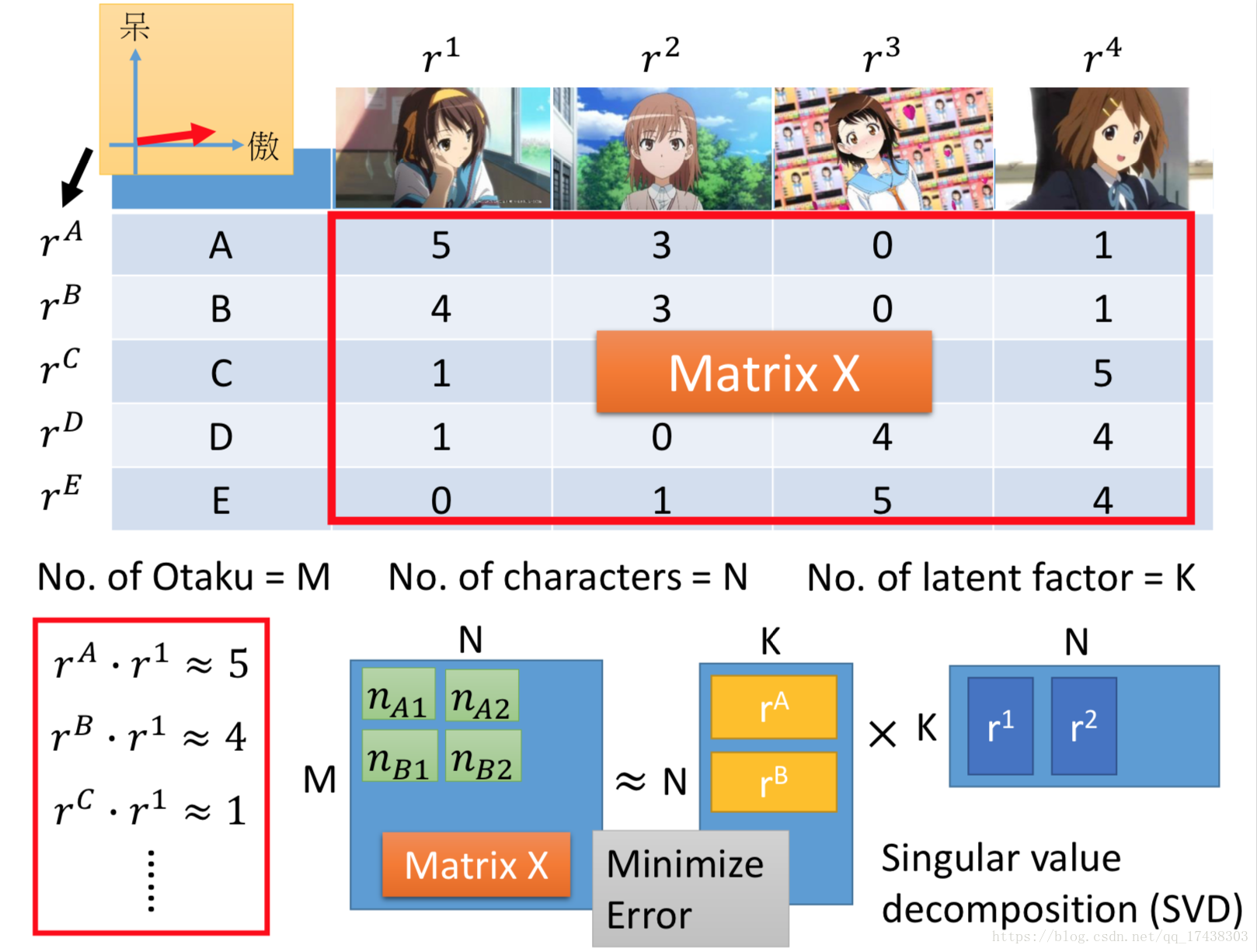
Matrix Factorization
现在假设有两种object,它们之间是受到共同的factor的影响,举个例子,现在假设有、
、
、
和
五个人,有
、
、
和
四种手办,可以直观地看到
多的人倾向于有更多的
,
多的人倾向于有更多的
,因此二者之间存在这隐藏的关系(萌、呆),属性相同的人和手办相互match(推荐系统!!!),越match二者的latent factor内积越大(如
)。
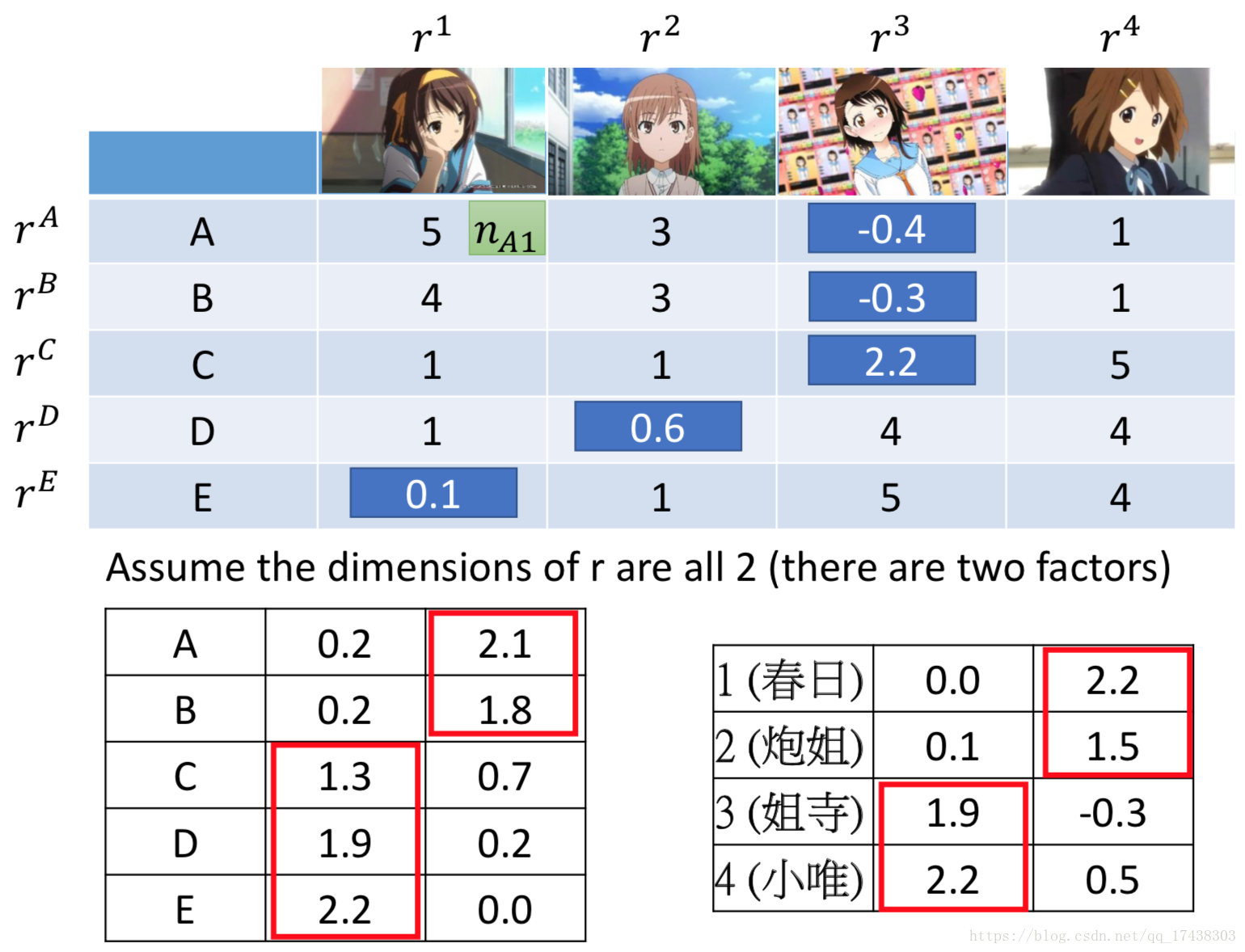
现在考虑更复杂的情况,假设A所在的地区就没有发行手办3,那么此时应该用?表示,此时应如下图,利用梯度下降算法最小化。

最终计算出、
、
、
和
五个人与
、
、
和
四种手办的共同属性,并且可以由此计算出?值
现在考虑更精致的模型,考虑其他独立的因素对手办购买的影响,比如(除了潜在因子
还考虑了
这个人购买手办的意愿
与手办1吸引人购买的能力
),最小化新的
。
