分类与回归
监督学习的问题主要有两种,分别是分类classification和回归regression。
分类: 分类问题的目的是预测类别标签class label,这些标签来自预定义的可选列表。
回归: 回归任务的目的是预测一个连续值,也叫作浮点数floating-point number,即预测值不是一个类别而是一个数字值。打个比方,假如要根据一个人的年龄学历等feature来预测这个人的收入,那么预测值为一个金额,可以在给定范围内任意取值。
区分分类与回归: 最好的办法就是看输出是否具有某种连续性,如果在可能的结果之间具有连续性,那么它就是一个回归问题。
泛化 generalize: 如果一个模型能对没有见过的数据做出准确的预测,那么就表明这个模型能从训练集generalize到测试集。
过拟合 overfitting 欠拟合 underfitting: 如果我们总想找到最简单的模型,构建与一个对于现有信息量过于复杂的模型,即在拟合模型的时候过分关注训练集的细节,得到了一个与训练集上表现很好但是不能泛化到新数据上的模型,那么就是overfitting过拟合。反之,如果模型过于简单,无法抓住数据的全部内容以及数据中的变化,甚至在训练集上表现就很差,那么就是underfitting欠拟合。
所以,在二者之间存在一个最佳位置,找到这个位置就是我们最想要的模型。
监督学习算法 supervised learning algorithm:
开始介绍最常用的机器学习算法,以及每个算法的复杂度,适用数据,如何构建模型。其中许多算法啥都有分类和回归两种形式。
首先模型都必须基于数据集进行构建,所以我们先了解一下数据集
模拟数据集:
- 二分类数据集forge数据集:
X, y = mglearn.dataset.make_forge() - 回归数据集wave数据集:
X, y = mglearn.datasets.make_wave(n_samples=40)
现实世界数据集:
- 分类数据集:乳腺癌数据集,每个肿瘤都被标记为良性或者恶性。30个特征
- 回归数据集:波士顿放假数据集,根据犯罪率,地理位置等信息预测房价中位数。13个特征
有时候我们还需要拓展训练集,比如输入feature不仅包括这13个features,还可以包括这些feature之间的乘积也叫作交互项 ,像这样导出特征的方法叫做特征工程feature engineering
K近邻:
k-NN算法算是最简单的机器学习算法,构建模型只需要保存训练数据集,想要对新的数据点做出预测,算法会在训练集中找到最近的数据点。
使用k近邻分类classification:
mglearn.plots.plot_knn_classification(n_neighbors=k)
最简单的版本就是考虑一个最近邻k=1,我们还可以考虑k个最近邻,在这种情况下,我们使用投票法来指定label,我们看哪个类别的最近邻更多,就将这个类别作为预测结果。
下面我们应用这个k近邻算法:
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # 将数据集分为训练数据集和测试数据集
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3) # 将这个模型实例化
clf.fit(X_train, y_train) # 使用训练数据集对这个分类器进行拟合
print("Test set predictions:", clf.predict(X_test)) # 对测试数据集进行预测
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test))) # 评估模型泛化能力
下面我们分析这个KNeighborsClassifier:
对于二维数据集,我们可以在平面上画出所有可能的测试点的预测结果,然后根据每个点的所属类别进行着色,这样可以查看两个类别数据的分界线,也就是决策边界decision boundary
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# the fit method returns the object self, so we can instantiate
# and fit in one line
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend(loc=3)
然后我们发现k=1的时候,决策边界紧跟着训练数据,k越大,边界越平滑,更平滑的边界对应着更简单的模型。
接下来,我们来画出模型复杂度与泛化能力之间的关系:
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# try n_neighbors from 1 to 10
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# build the model
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# record training set accuracy
training_accuracy.append(clf.score(X_train, y_train))
# record generalization accuracy
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
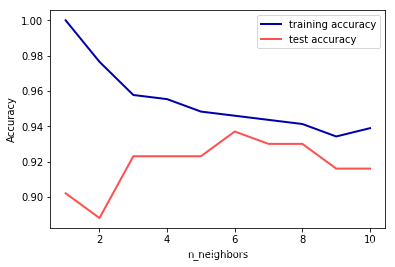
通过这张图,我们可以看到过拟合与欠拟合的一些特性,比如当k=1的时候,模型对于训练数据集上的预测结果非常的完美,但是测试数据集上的精确度比更多近邻的时候精确度低。这样看来,最佳性能的应该在中间的某处,这样对于训练和测试数据集的精度都比较好。
k近邻回归regression:
在回归问题上,使用多个近邻的预测结果为这些邻居的平均值。使用方法跟分类问题基本一致:
from sklearn.neighbors import KNeighborsRegressor
X, y = mglearn.datasets.make_wave(n_samples=40)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
reg = KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train, y_train)
print("Test set predictions:\n", reg.predict(X_test))
print("Test set R^2: {:.2f}".format(reg.score(X_test, y_test)))
对于回归问题的score方法,返回的是R的平方,这个分数也叫做决定系数,位于0~1之间,等于1的时候为完美预测,等于0的时候代表总是预测训练数据集的平均值。
算法总结:
KNeighbors分类器有两个参数,即邻居的个数以及数据点之间距离的度量方法,往往使用较小的邻居数就能得到比较好的结果,距离的度量方法默认使用欧式距离,这个方法大多数情况效果良好。在训练数据集很大的情况下,预测速度会比较慢,这个算法对于features很多的数据集处理很不好,对于大多数feature取值为0的数据集(稀疏数据集)来说,算法效果非常不好。所以这个算法在实践中往往不会用到。
线性模型linear:
线性模型在实践中被广泛使用,线性模型是利用输入features的线性函数来进行预测的。
用于回归regression的线性模型:
y = w[0]*x[0]+w[1]*x[1]+....+w[p]*x[p]+b
x[0]到x[p]为单个数据点的特征,w和b为学习模型的参数,所以对于单一特征来说预测结果是一条直线,对于两个特征是一个平面,更多特征即更高维度是一个超平面。
如果数据集有多个特征,那么线性模型很强大,尤其是当特征数量大于训练数据集数量时,任何目标y都可以在训练集上用线性函数完美的拟合。下面我们介绍许多不同的线性回归模型,这些模型之间的差异就是它们如何从训练数据集中学习参数w和b,以及如何控制模型的复杂度。
- 线性回归,也叫作普通最小二乘法,ordinary least squares OLS:
线性回归寻找参数b和w,使对训练集的预测值与真实的回归目标值之间的均方误差mean squared error最小,这个误差是预测值与真实值之差的平方和除以sample数量。但是线性回归没有参数,所以无法控制模型的复杂度。
from sklearn.linear_model import LinearRegression
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
lr = LinearRegression().fit(X_train, y_train)
print("lr.coef_:", lr.coef_) # 【0.394】这个应该是一个numpy数组,每个元素对应一个输入特征,本例只有一个输入特征
print("lr.intercept_:", lr.intercept_) # -0.031
print("Training set score: {:.2f}".format(lr.score(X_train, y_train))) # 0.67
print("Test set score: {:.2f}".format(lr.score(X_test, y_test))) # 0.66 与训练集分数太接近说明可能存在欠拟合
对于一维数据集来说,过拟合风险很小,因为模型非常简单,但是对于高维数据集来说,线性模型变得更加强大,过拟合的风险也会变大。然后我们把这个模型用于波士顿房价训练集,结果发现训练集分数为0.95,但是测试集分数为0.61,这是很明显的过拟合标志,所以我们需要一个可以控制模型复杂度的模型,那么标准的线性回归的常用替代方法之一就是岭回归ridge regression。
- 岭回归ridge regression:L2正则化
它的预测公式与普通最小二乘法的公式相同,但是对系数w的选择不仅要在训练集上表现良好,还需要拟合附加的约束,还希望所有的w都应该接近于0,即斜率很小,即每个feature对输出的影响尽可能小的情况下同时给出很好的预测结果。
这种约束就是正则化regularization,为避免过拟合,岭回归用到的这种被称为L2正则化。
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=10).fit(X_train, y_train)
print("Training set score: {:.2f}".format(ridge.score(X_train, y_train))) # 0.89
print("Test set score: {:.2f}".format(ridge.score(X_test, y_test))) # 0,75
可以发现ridge在训练集上的分数比linear regression要低,但是在测试数据集上的分数更高。因为ridge是一种约束能力更强的模型,所以更不容易存在过拟合。复杂度更小的模型意味着在训练集上性能更差,但是泛化能力更好,但是我们恰恰只对泛化能力感兴趣,所以选择ridge。
ridge模型对于模型的简单性即系数趋向于0以及训练集性能之间做出权衡,可以通过设置alpha参数来设定。上面例子默认使用alpha=1,增大alpha会使得系数更加趋向于0==》降低训练集性能,但是可能会提高泛化能力。对于非常小的alpha可以让系数收到的限制更小,会得到一个与linear regression类似的模型。
无论是岭回归还是线性回归,所有数据集大小对应的训练分数都要高于测试分数,随着模型的可用数据越来越多,两个模型的性能都在提升,最终线性回归追上了岭回归,所以,只要有足够多的训练数据集,正则化就不那么重要了。
- lasso回归lasso regression:L1正则化
与ridge regression相似,使用lasso也是约束系数使之接近于0,但是使用的方法不一样,是L1正则化,使用L1正则化的结果是某些系数刚好等于0,这说明某些features被模型完全的忽略。不过这样模型更容易解释,也可以呈现模型最重要的特征。
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso.score(X_train, y_train))) # 0.29
print("Test set score: {:.2f}".format(lasso.score(X_test, y_test))) # 0.21
print("Number of features used:", np.sum(lasso.coef_ != 0)) # 4
上述例子我们可以发现,模型在训练集和测试集上面的表现都很差,这表示存在欠拟合,可以看到模型中的特征只用到了4个,所以我们让模型更加拟合,适当减少alpha参数的值。同时,我们还需要增加max_iter的值,即运行迭代的最大次数:
lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)
这样结果比较好,最后得出使用到模型特征105个中的33个,模型也更容易理解,但是alpha也不能设置得太小,因为可能会消除正则化的效果,使模型过拟合。
我们可以对不同模型的系数进项作图:
plt.plot(lasso.coef_, 's', label="Lasso alpha=1")
plt.plot(lasso001.coef_, '^', label="Lasso alpha=0.01")
plt.plot(lasso00001.coef_, 'v', label="Lasso alpha=0.0001")
plt.plot(ridge01.coef_, 'o', label="Ridge alpha=0.1")
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")

比较ridge regression和lasso regression:
在实践中,两个模型一般首选ridge regression。但是如果发现数据集特征很多但是只有其中几个是很重要的,那么选择lasso regression可能会更好。在sklearn中,还提供了ElasticNet类,结合了ridge和lasso的惩罚项,在实际操作中这种结合的效果最好,只是需要调节两个参数:L1正则化和L2正则化。
用于分类classification的线性模型:
y = w[0]*x[0]+w[1]*x[1]+....+w[p]*x[p]+b > 0
如果函数值小于0为类别a,如果函数值大于0为类别b,对于所有用于分类的线性模型,这个规则都是通用的。
对于regression的线性模型,输出y是特征的线性模型,是直线,平面或者超平面。但是对于用于分类的线性模型,决策边界是输入的线性函数,也就是说,线性分类器是利用直线,平面或者超平面来分开两个类别的分类器。
最常见的两种线性分类算法是逻辑回归Logistic regression(LogisticRegression中实现)和线性支持向量机linear support vector machine(LinearSVC中实现),其中要注意逻辑回归名字中有回归,但是这是一种分类算法。这两个模型都默认使用了L2正则化。但是对于这两个模型,决定正则化强度的权衡参数叫做C,C值越大,对应的正则化越弱,那么LogisticRegression和LinearSVC将尽可能的将训练集拟合到最好,反之,如果C值较小,那么模型更强调使系数向量更接近于0。除此之外,C值还有一个作用,较小的值可以让算法尽量适应大多数数据点,较大的值更强调每个数据点都分类正确的重要性:
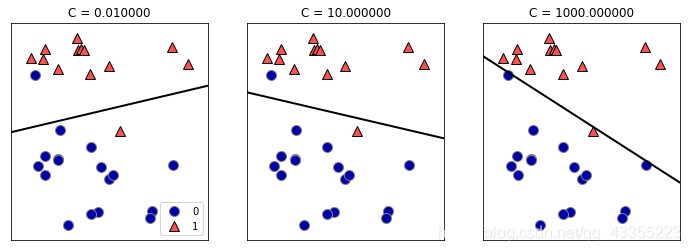
- 逻辑回归logistic regression:默认L2正则化
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
logreg = LogisticRegression(C=1).fit(X_train, y_train)
print("Training set score: {:.3f}".format(logreg.score(X_train, y_train))) # 0.953
print("Test set score: {:.3f}".format(logreg.score(X_test, y_test))) # 0.958
这里C=1其实是默认值,我们可以发现C=1给出了相当不错的精度,但是由于训练集和测试集的性能太接近,我们有理由怀疑这个模型可能是欠拟合的,所以我们尝试增加参数C来将训练集拟合得更好。使用C=100时,我们得到0.972/0.965,可以发现我们的猜想是正确的,因为这个更复杂的模型性能更好,得到了更高的训练集和测试集精度。使用C=0.01时,我们得到一个正则化更强的模型,得到精度0.934/0.930,可以看出我们将已经就比较欠拟合的模型变得更加欠拟合了,所以精度双双降低。
逻辑回归默认使用L2正则化,但是如果我们想要一个可解释性更强的模型,使用L1正则化可能会更好,因为这样模型只使用少数几个特征:
lr_l1 = LogisticRegression(C=C, penalty="l1").fit(X_train, y_train)
我们可以使用penalty参数来改变正则方式,也会影响这个模型是使用全部features还是其中的部分features。
- LinearSVC:
很多线性分类器只使用于二分类,不能轻易推广到多类别问题,除了逻辑回归。
**多分类原理:**将二分类推广到多分类,最常见的方法是one vs rest,即对每个类别都学习一个二分类模型,将这个类别与所有其他的类别尽量分开,这样就生成了与类别数量一样多的二分类模型。然后我们在测试点上运行所有的二分类模型,对应类别上分数最高的二分类模型即为预测结果。
我们使用one vs rest方法应用到三分类数据集上:
from sklearn.datasets import make_blobs
X, y = make_blobs(random_state=42)
linear_svm = LinearSVC().fit(X, y)
print("Coefficient shape: ", linear_svm.coef_.shape) #(3,2)
print("Intercept shape: ", linear_svm.intercept_.shape) # (3,)
coef_每行是三个类别之一的系数向量,每列是每个特征对应的系数向量,然而intercept_是一个一维数组,即每个类别的截距。
然后我们将这3个二类分类器给出的直线可视化:
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.ylim(-10, 15)
plt.xlim(-10, 8)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1','Line class 2'], loc=(1.01, 0.3))
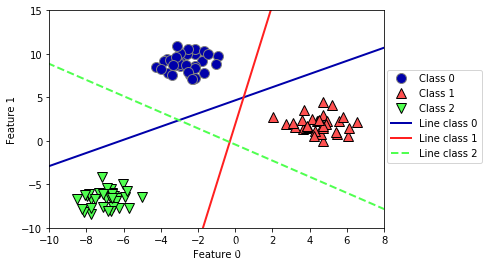

总结优缺点:
线性模型的主要参数是正则化参数,在回归模型中为alpha,在LinearSVC和logistic regression中叫做C。alpha较大或者C较小,说明模型比较简单,通常在对数尺度上对这两个参数进行搜索。
还需要确定使用L1还是L2正则化,如果只有几个特征比较重要或者需要一个可解释的模型,那么可以使用L1正则化,否则默认使用L2正则化。
线性模型的训练速度很快,预测速度也很快,如果特征数量大于样本数量,线性模型的表现都比较好,所以常用于非常大的数据集。
朴素贝叶斯分类器Naive Bayes
Naive Bayes(后面简称NB)是与线性模型非常相似的一种分类器,训练速度往往更快,但是泛化能力会比线性分类器稍差。NB高效的原因在于他是通过单独查看每个特征来学习参数的。
SKlearn中有三种朴素贝叶斯分类器:
- GaussianNB: 用于任意连续数据,保存每个类别中每个特征的平均值和标准差。
- BernoulliNB: 假定输入数据为二分类数据,主要用于文本数据分类,计算每个类别中特征不为0的元素的个数
- MultinomialNB: 假定输入数据为计数数据(比如一个单词在一个句子里面出现的次数),主要用于文本数据分类。计算每个类别中每个特征的平均值。
我们在这里解释一个BermoulliNB模型:这个分类器计算每个类别中特征不为0的元素的个数
X = np.array([[0, 1, 0, 1],
[1, 0, 1, 1],
[0, 0, 0, 1],
[1, 0, 1, 0]])
y = np.array([0, 1, 0, 1])
可以看出我们有4个数据点,每个点有4个二分类特征。从y中我们可以看出一共有两个类别为0和1,对于类别0,第一个和第三个数据点为类别0。即[0,1,0,1]和[0,0,0,1],第一个特征有两个为0,没有不为0的,第二个特征…以此类推,计算每个类别中非0元素个数:
counts = {}
for label in np.unique(y):
counts[label] = X[y == label].sum(axis=0)
print("Feature counts:\n", counts)
Feature counts:
{0: array([0, 1, 0, 2]), 1: array([2, 0, 2, 1])}
优缺点总结:
MultinominalNB和BernoulliNB只有一个参数alpha,用于控制模型的复杂度。alpha的工作原理:算法向数据中添加alpha这么多个虚拟数据点,这些点对所有的features都取正值。所以这样可以将统计数据平滑化,alpha越大,平滑性越强,模型复杂度越低。但是alpha值对模型的性能并不重要,通常只是对精度略有提高。这两个模型广泛用于稀疏计数数据,比如文本。
GaussianNB主要用于高维数据。
决策树 decision tree:
决策树是广泛用于分类和回归任务的模型,本质上是从一层层if/else问题中进行学习得出结论的:
mglearn.plots.plot_animal_tree()
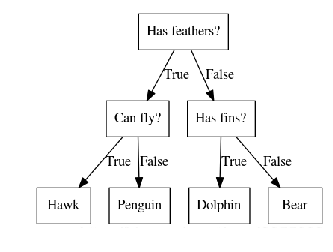
如图所示,树的每一个节点代表一个问题或者一个包含答案的终结点(叶节点),树的连线将问题的答案与即将要问到的下一个问题连接起来。