一、无监督学习引入
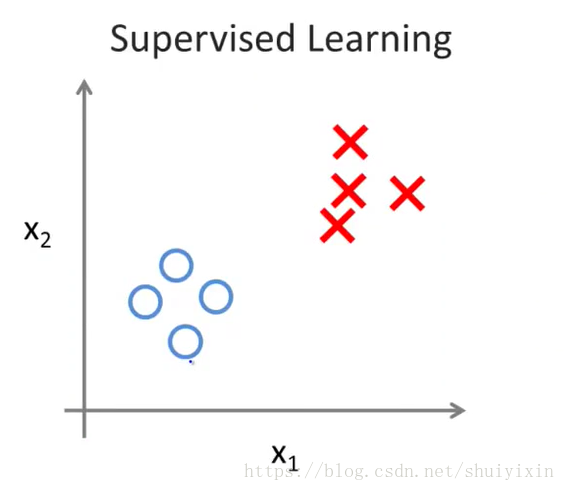
观察上面左边的图,该图是监督学习的分类问题,在监督学习中,数据集中的每个样本有相应的“正确答案”,即被标为良性或者恶性肿瘤。根据这些样本做出预测。
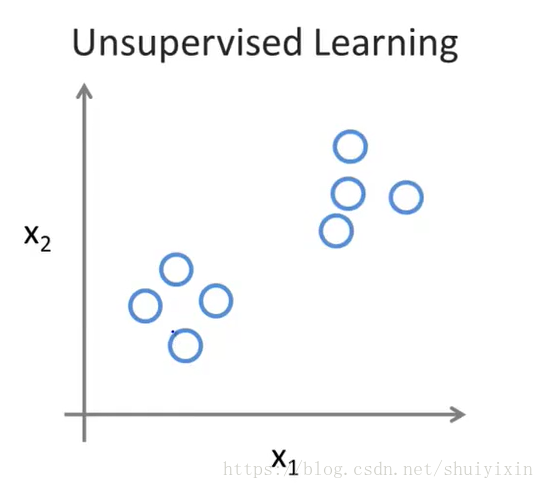
再看右侧,和左侧的区别在于,不管是哪一类,都用相同的符号“圆圈”表示。也就是在右侧的图中,没有了分类。所有的数据是一样的,没有对错之分。我们只有一个数据集,没有人告诉我们什么是正确的,我们也不知道每个数据点是什么含义。这就是我们今天要说的“无监督学习(Unsupervised learning)”。
二、无监督学习概念
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。无监督学习的数据集跟监督学习不同,没有任何标签,即没有相应的“正确答案”。
三、聚类算法简介
在最开始的问题中,我们提到,数据点是没有区别的,但是我们能发现,这些数据分为两部分,我们称之为“聚类”。实现这种无监督的算法,就称之为“聚类算法”。
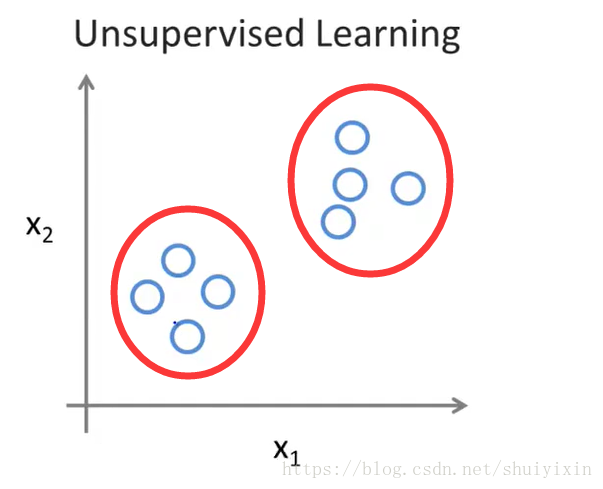
四、应用举例
1.谷歌新闻

谷歌新闻每天会报道成大量的新闻,并通过聚类算法,将新闻归类,组成一个个新闻专题。谷歌新闻要做的就是搜集成千上万的新闻,通过聚类的方式,将新闻分类。

2.基因芯片
基因芯片的基本思想是:给定一组不同的个体,对于每个个体,检测他们是否拥有某个特定的基因。
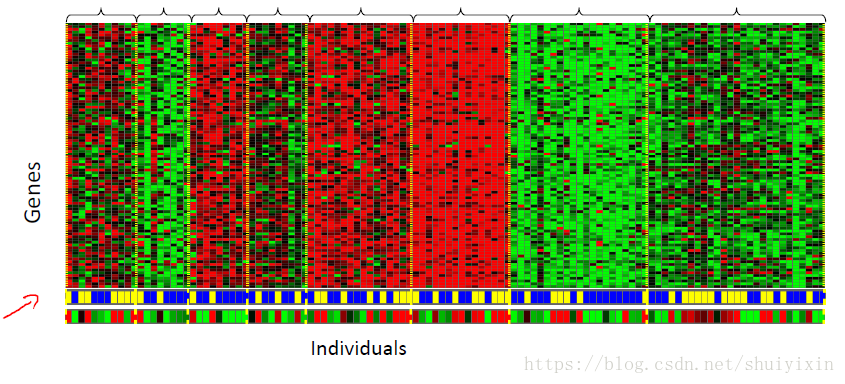
如图是DNA数据,该图中不同颜色展示了不同的个体,通过聚类算法,把不同的个体归到不同的类或者不同类型的人。我们没有提前告知,哪些是第一类人,哪些是第二类人,哪些是第三类人。甚至没有告诉他这些数据是什么东西,只是给算法一些数据。算法需要通过这些数据自动分析,自动把这些个体分类。我们没有给算法一个正确的答案,这就是无监督学习。
3.其他例子
下面包括组织计算机集群,社交网络分析,市场划分,天文数据分析等,这些都是应用无监督学习的例子。
4.鸡尾酒宴问题(Cocktail party problem)
“鸡尾酒会问题”(cocktailparty problem)是在计算机语音识别领域的一个问题,当前语音识别技术已经可以以较高精度识别一个人所讲的话,但是当说话的人数为两人或者多人时,语音识别率就会极大的降低,这一难题被称为鸡尾酒会问题。
该问题描述的是给定混合信号,如何分离出鸡尾酒会中同时说话的每个人的独立信号。当有N个信号源时,通常假设观察信号也有N个(例如N个麦克风或者录音机)。该假设意味着混合矩阵是个方阵,即J = D,其中D是输入数据的维数,J是系统模型的维数。
无监督学习是解决这个问题的一种很好的方法。算法不会提前知道声音是谁的,只是接收到了几段声音,通过聚类的方式,把声音分离出来。下面这幅图是该算法的公式:

当然,现在暂时不需要懂这个公式的原理和来源(当然,如果你明白,那就更棒啦。)以后会详细介绍。
五、吴大师建议
(从我准备走上机器学习之路,了解到吴恩达先生时,吴恩达先生就是我最敬佩的人之一了。所以,称之为大师,我认为是对他最真实、也是最发自内心的评价。)
在视频最后,吴大师建议编程用Octave,Octave,Octave。原因:代码简单,运行速度快。