定义符号
m:训练样本的数目
n:特征的数量
x‘s:输入变/特征值
y‘s:输出变量/目标变量
(x,y):训练样本 ->(x(i),y(i)):训练集,第i个训练样本,i=1,2..,m
监督学习
定义:(口头表达,非正式)我们给学习算法一个数据集,这个数据集由“正确答案”组成,它的目标是给定某个训练集,需要学习某个函数h:X->Y(x到Y的映射), 使得h(x)就是一个“好”的预测器,能够给出相应的输出值y。函数h称为hypothesis。
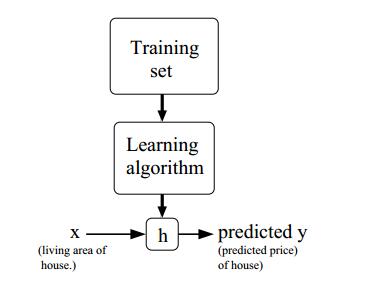
解释:首先通过训练集来学习出一个算法得到一个假设函数h,然后利用假设函数来完成x到y的最好映射。
监督学习的例子
假定我们有一个数据集,它给出了居住地和房子价格的关系,如下表格所示:

假设上面的数据有47组,图像如下图所示:
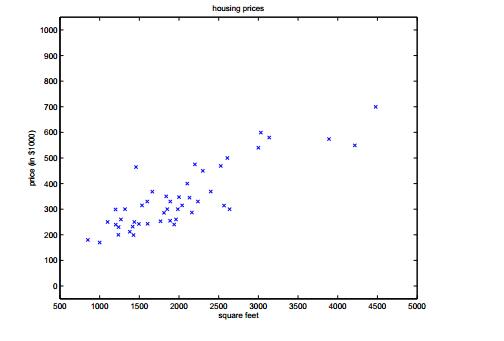
这样根据我们上面给出的训练集我们要经过一个学习算法,得到一个假设函数,使得这个假设函数能更好的拟合我们给出的数据,从而在以后当我们给出房屋的大小时能更好的预测房屋的价格。
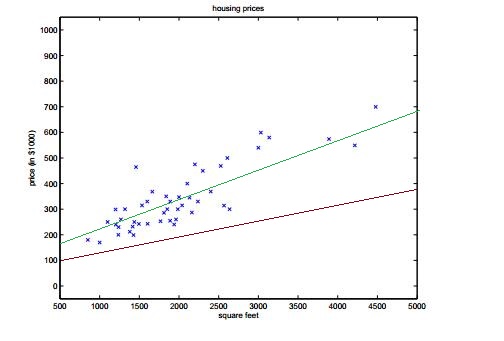
如上图所示,假设我们得出的假设函数是一个线性的,这样上面的函数明显比下面相对于我们给出的样本能够更好的拟合。这就是一个监督问题。
监督学习的分类
当我们想要预测的输出值为连续的,例如上例中我们的输出值是价格,那么该学习问题为一个回归(Regression)问题。当输出值y仅能在一个有限的离散值集合中取值,我们称之为分类(Classification)问题。