
文章目录
- Abstract
- 1 INTRODUCTION
- 2 BACKGROUND
- 3 POINT CLOUD DATASETS
- 4 COMMON DEEP ARCHITECTURES FOR POINT CLOUD LEARNING
- 5 UNSUPERVISED POINT CLOUD REPRESENTATION LEARNING(无监督的点云representation learning)
- 5.3 Multiple modal-based methods
- 5.4 Local descriptor-based methods
- 6 BENCHMARK PERFORMANCES
- 7 FUTURE DIRECTION(未来方向)
- 8 CONCLUSION(结论)
Abstract
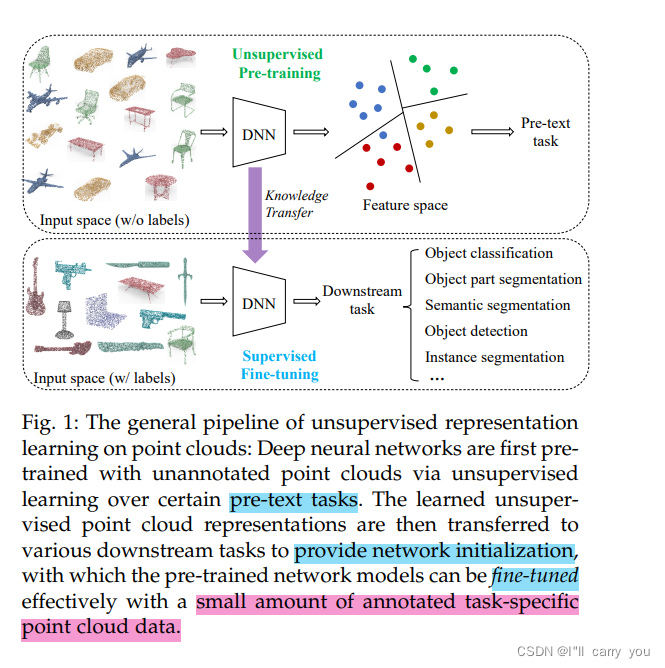
1 INTRODUCTION
2 BACKGROUND
2.1 Basic concepts

3 POINT CLOUD DATASETS
4 COMMON DEEP ARCHITECTURES FOR POINT CLOUD LEARNING
5 UNSUPERVISED POINT CLOUD REPRESENTATION LEARNING(无监督的点云representation learning)
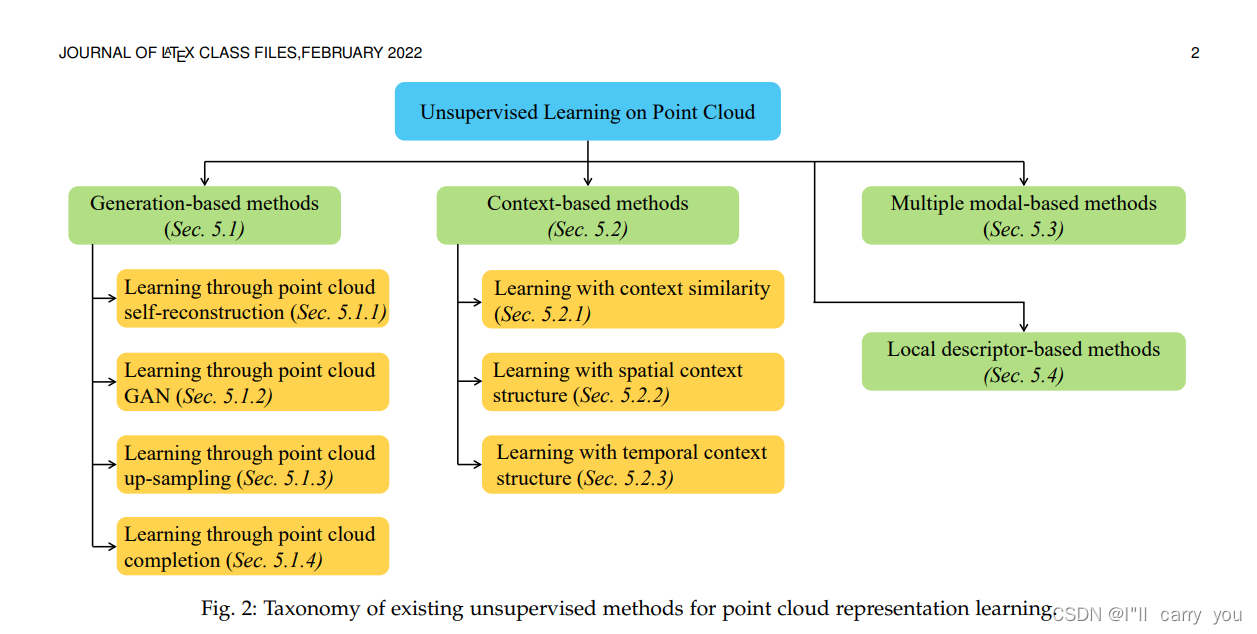
如图2所示,我们将现有的无监督点云表示学习方法分为四大类,包括基于生成的方法、基于上下文的方法、基于多模态的方法和基于局部描述符的方法(generation-based methods, context-based methods, multi-modal-based methods, and local descriptor based methods.)。根据这种分类法,我们对现有的方法进行了分类,并将对它们进行详细的回顾,如下所示。
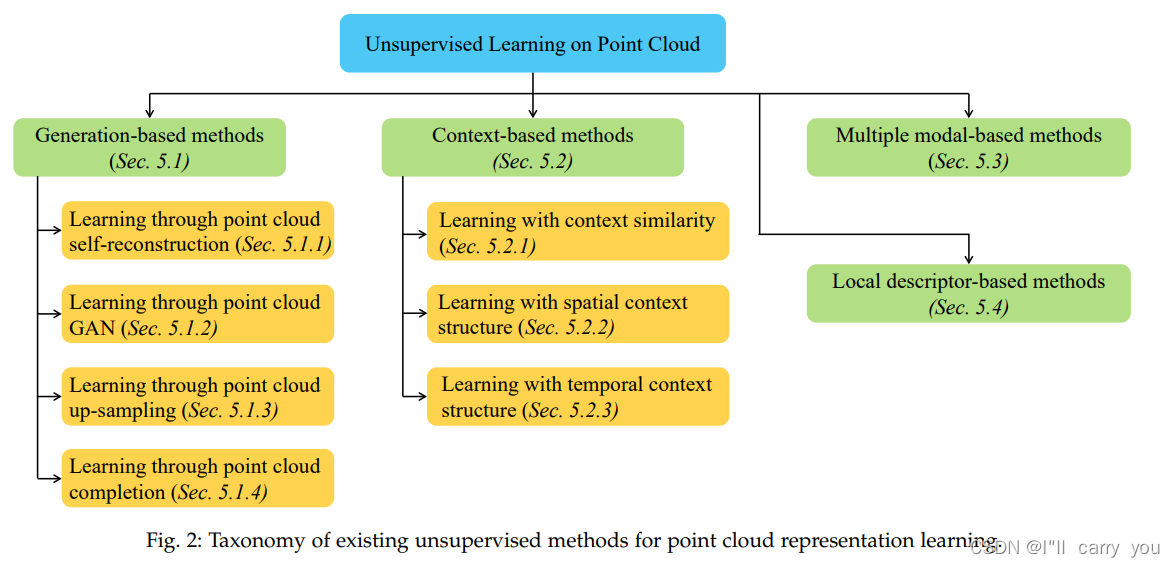
图2:现有无监督点云表示学习方法的分类
5.1 Generation-based methods
基于生成的无监督点云表示学习方法涉及生成点云对象的过程,根据pre-text tasks,可以进一步归纳为四个子类,包括点云自重构(生成与输入相同的点云对象)、点云GAN(生成假点云对象),点云向上采样(生成形状类似但比输入密度更大的点云)和点云完成(预测部分点云对象的缺失部分)。训练这些方法的ground truth是点云本身,它不需要人工注释,可以被视为无监督学习方法。表2中列出了基于生成的方法。
表2:基于生成的点云无监督表示学习方法综述

5.1.1 Learning through point cloud self-reconstruction
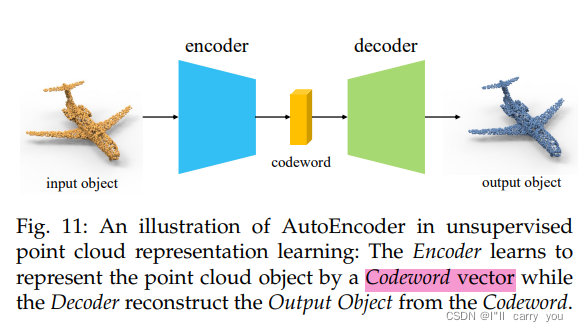
学习点云表示最常见的无监督方法之一是自重构3D对象,它将点云样本编码为表示向量,并将其解码回原始输入数据。在这个过程中,形状信息和语义结构被提取并编码到表示中。由于不涉及人类标注,因此它属于无监督学习。一个典型且最常用的模型是自动编码器[69](Autoencoder)。如图11所述,它由编码器网络和解码器网络组成。编码器将点云对象压缩并编码为一个名为码字[56](codeword)的低维嵌入向量。然后将其解码回3D空间,并要求输出与输入相同。通过尝试从编码中重新生成输入来验证(validated )和细化(refined )编码,自动编码器通过训练网络忽略不重要的数据(“噪声”)来学习降维表示[70]。

提出了一系列基于自重构的无监督方法:


为了进一步 提取 局部几何特征:

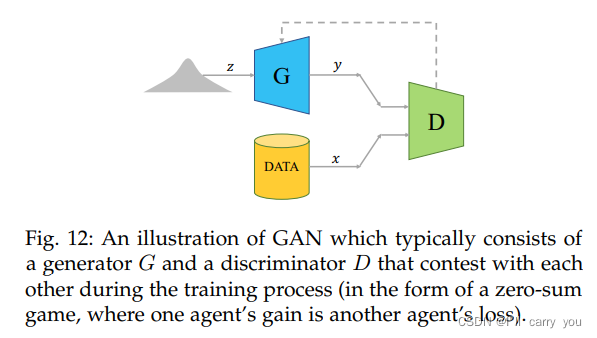
5.1.2 Learning through point cloud GAN



5.1.3 Learning through point cloud up-sampling
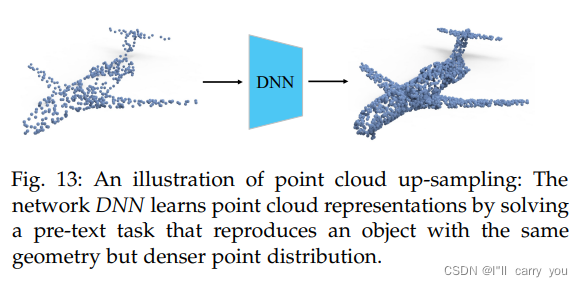
如图13所示,给定一组点,点云上采样任务旨在生成更密集的点集,这需要深层点云网络来学习3D形状的基本几何结构。不涉及人类注释,它属于无监督学习。
相关工作:


5.1.4 Learning through point cloud completion
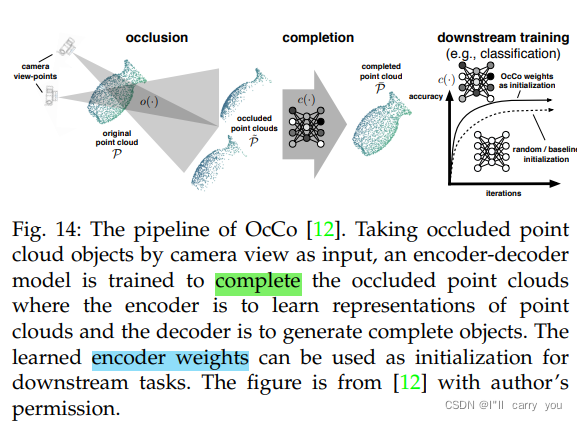
点云补全是基于其余三维点云对象预测任意缺失部分的任务。网络需要学习对象的内部几何结构和语义知识,以便正确预测缺失的部分,然后将其转移到下游任务中。由于点云完成任务不需要人工标注,这些方法属于无监督学习。
相关工作:


最近,在NLP[5]、[6]和2D vision[10]中,从不完整输入中恢复缺失部分作为代理任务( pre-text task )已被证明是非常成功的,而在点云无监督学习方面的研究却很少。我们相信这是未来研究的一个潜在和有希望的方向。(数据量少的缘故?)
5.1.5 Discussion
基于生成任务的点云无监督学习是一个历史悠久的主要研究方向。现有的方法主要集中在从对象级点云学习,而很少有研究场景级数据,这限制了无监督学习的应用。相反,基于生成的无监督学习方法在NLP[6]、[32]和2D vision[10]中都取得了巨大成功。为此,我们认为这方面有很大的潜力。
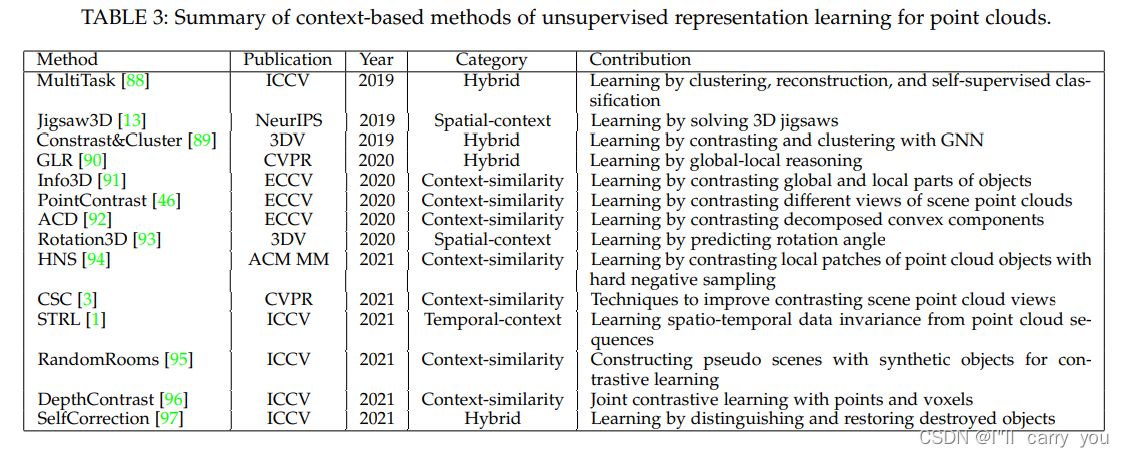
5.2 Context-based methods
另一类无监督点云学习方法是基于上下文的方法。与通过生成点云进行学习的基于生成的方法不同,这些方法使用discriminative pre-text tasks来学习点云的不同上下文,包括上下文相似性、空间上下文结构和时间上下文结构(context similarity, spatial
context structures and temporal context structures)。表3总结了一系列方法。
5.2.1 Learning with context similarity
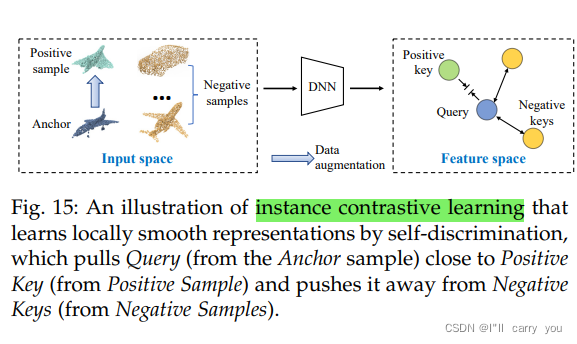
这种方法通过探索样本之间潜在的上下文相似性来形成无监督学习。一种典型的方法是对比学习(contrastive learning),近年来,对比学习在2D[7]、[8]、[104]和3D[3]、[46]、[96]无监督表征学习方面都表现出了优异的性能。图15显示了实例对比学习( instance-wise contrastive learning)的示例:

相关工作:


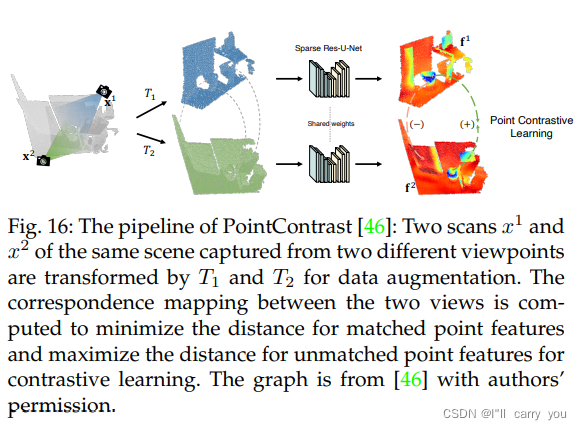




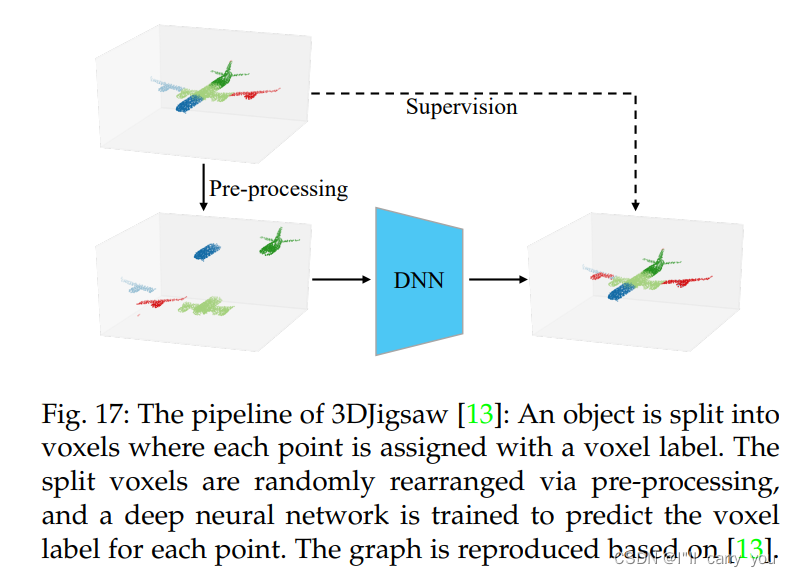
5.2.2 Learning with spatial context structure
5.2.3 Learning with temporal context structure
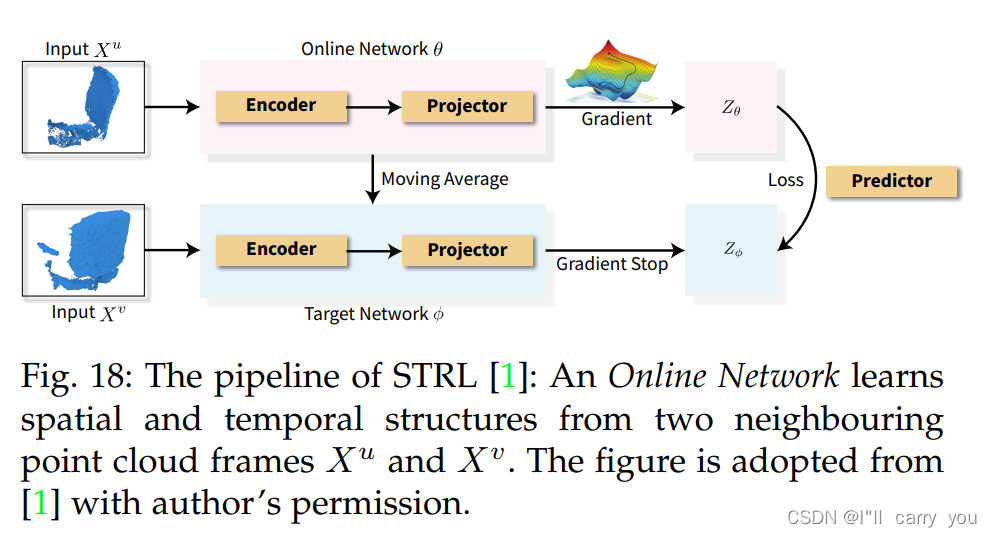

5.2.4 Discussion

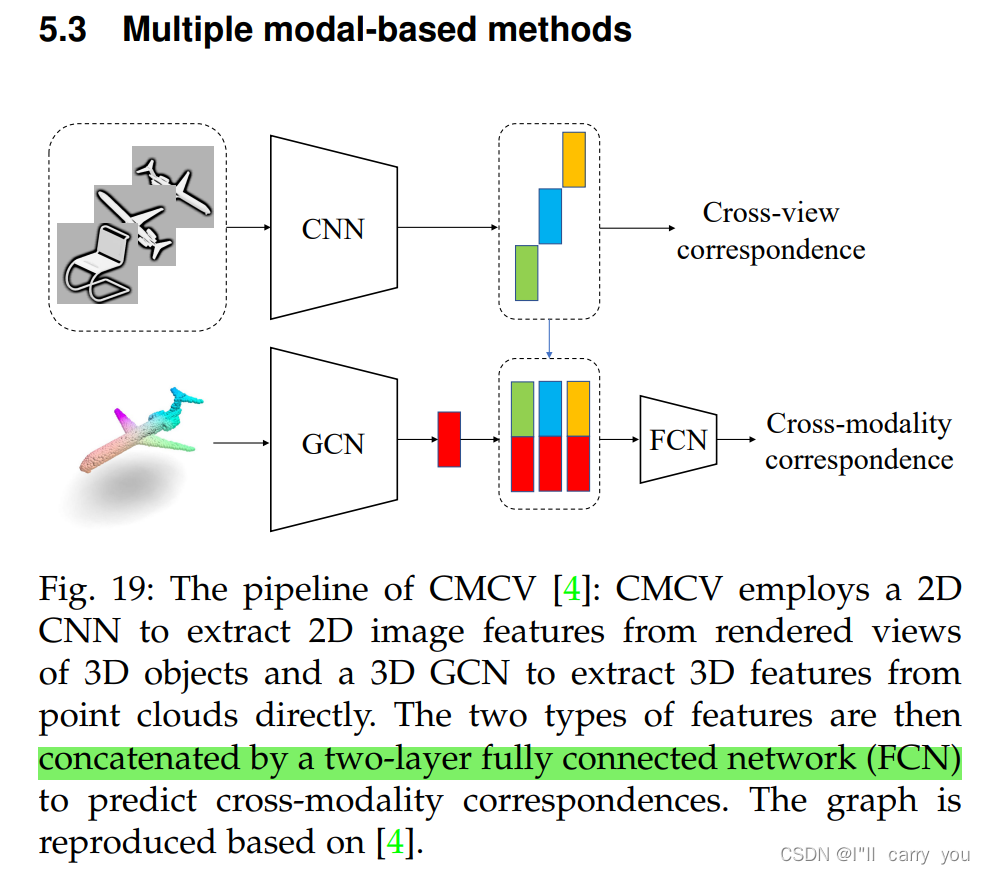
5.3 Multiple modal-based methods


5.4 Local descriptor-based methods


6 BENCHMARK PERFORMANCES

6.1 Object-level tasks
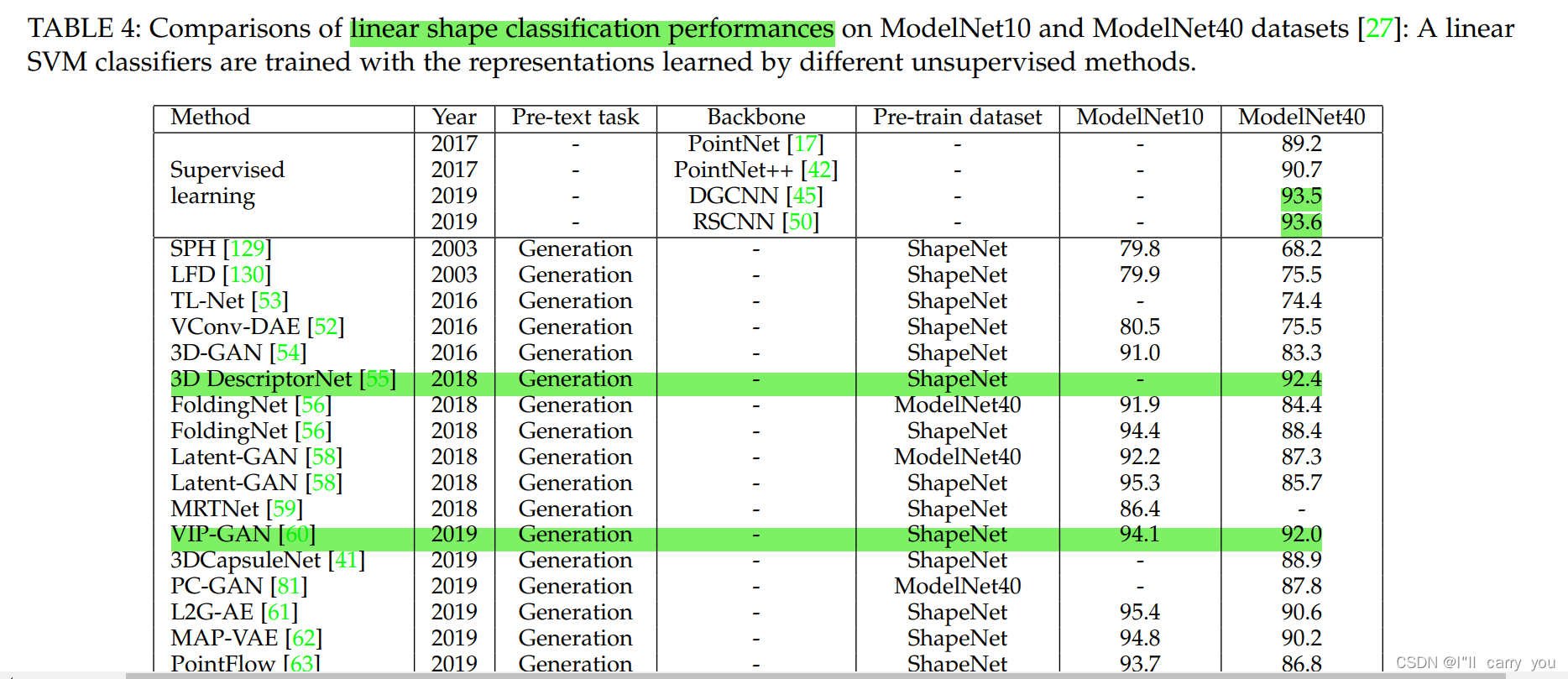
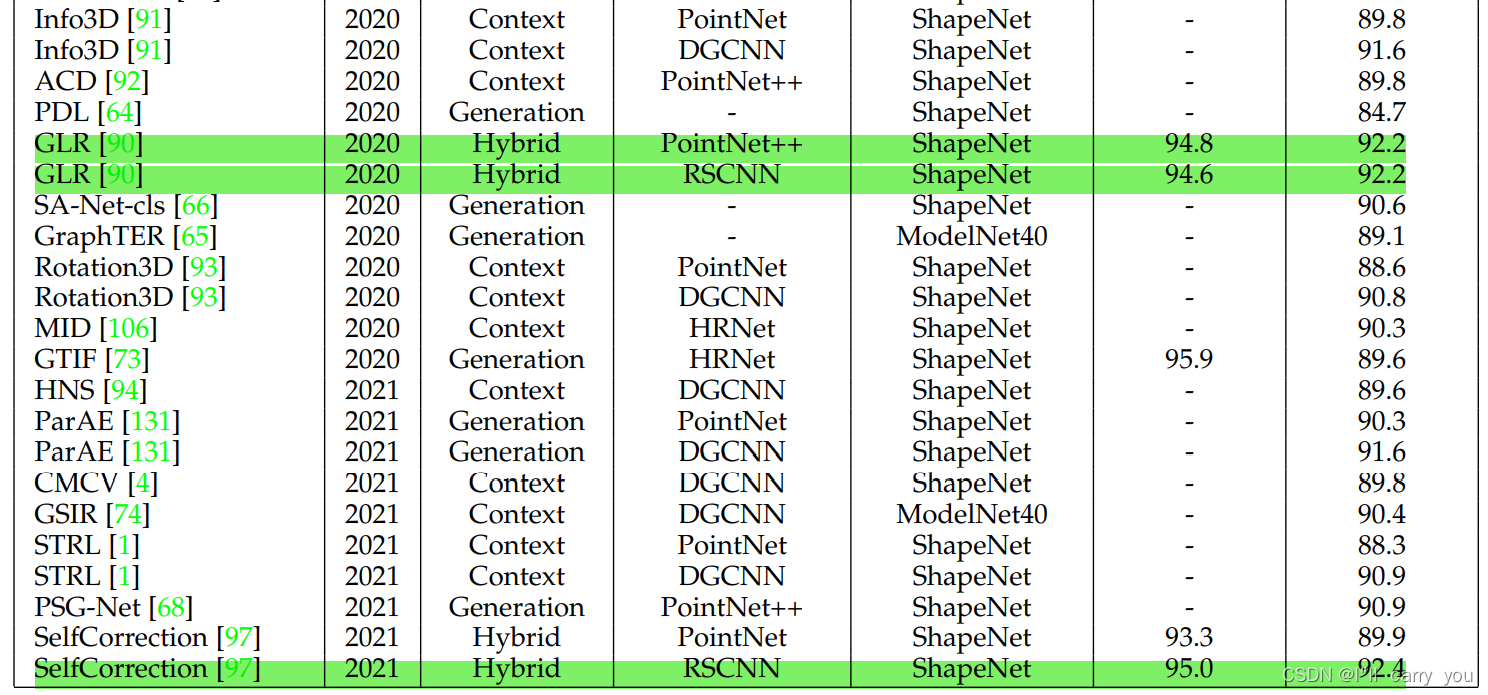
6.1.1 Object classification
Backbone 大多是 PointNet,PointNet++,DGCNN,RSCNN,所以这几个网络必须掌握
6.1.2 Object part segmentation
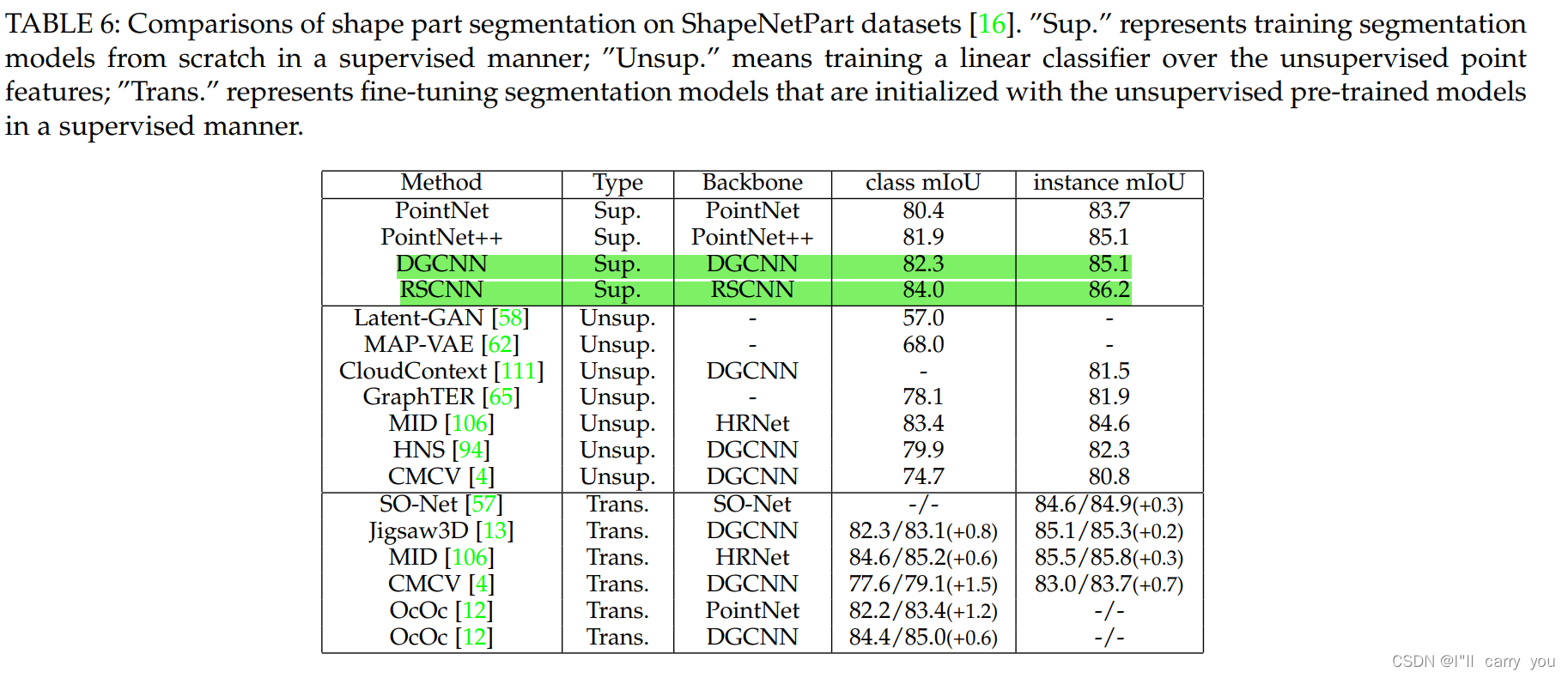
6.2 Scene-level tasks
7 FUTURE DIRECTION(未来方向)





8 CONCLUSION(结论)
