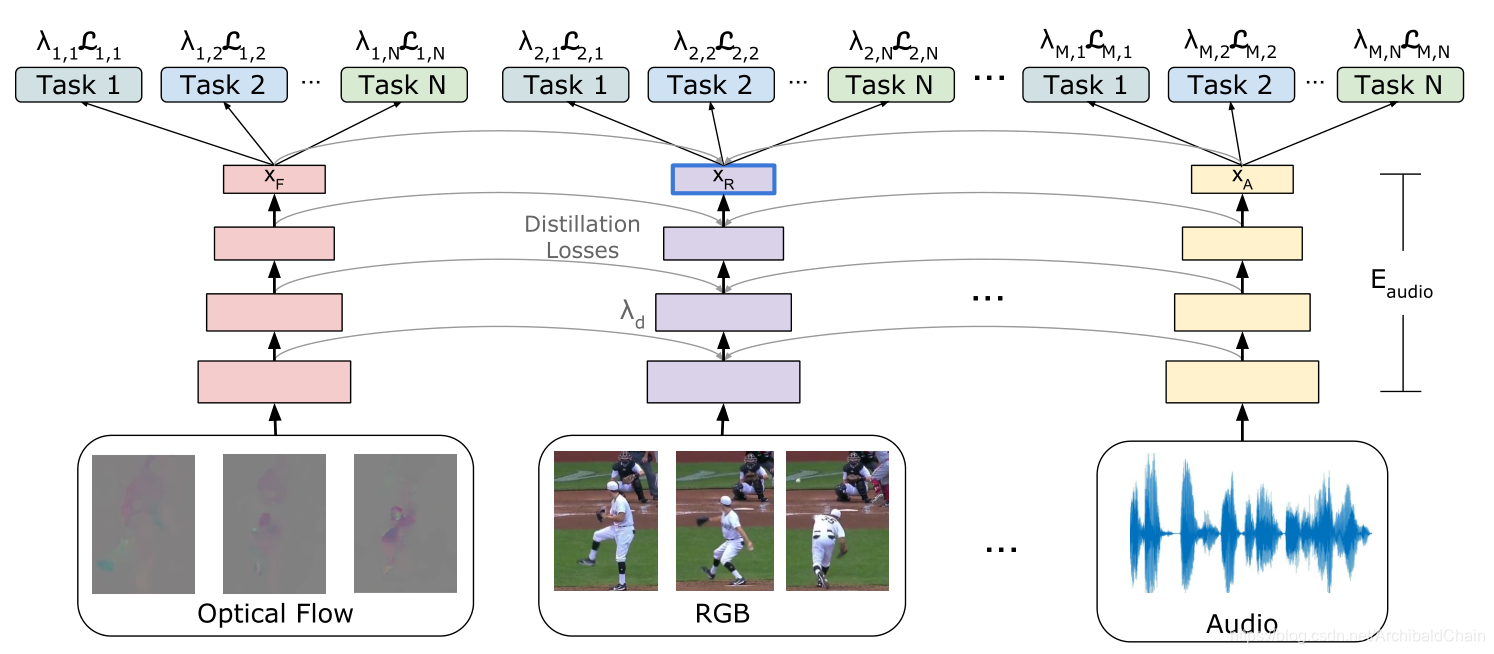
Ld is L2 distance of a layer in the main network Mi to another network Li Ld(Li,Mi)=∥Li−Mi∥2
Evolution Algorithm
Using GA to determine the λ
Each λm,t orλd is constrained to be in [0,1]
Unsupervised loss function
Zipf Distribution matching (ELo)
cluster centroids {c1,c2,…ck} where ci∈RD
Naively assuming all clusters have the same variance, and let 2σ2=1
we can compute the probability of a feature vector x∈RD belonging to a cluster ci as p(x∣ci)=2σ2π1exp(−2σ2(x−ci)2) Bayes rules: p(ci∣x)=∑jkp(cj)p(x∣cj)p(ci)p(x∣ci)=∑j=1kexp−2σ2(x−cj)2exp−2σ2(x−ci)2=∑j=1kexp−(x−cj)2exp−(x−ci)2 which is standard softmax function
given the above probability of each video belonging to each cluster, and the Zipf distribution, we compute the prior probability of each class as q(ci)=Hk,s1/is where H is kth harmonic number and s is real constant.
p(ci)=N1∑x∈Vp(ci∣x), the average over all videos in the set.
KL divergence : KL(p∥q)=i=1∑kp(ci)log(q(ci)p(ci)) This will be our fitness function.
it poses a prior constraint over the distribution of (learned) video representations in clusters to follow the Zipf distribution.