解决的问题
主要还是无监督图像特征预训练的问题
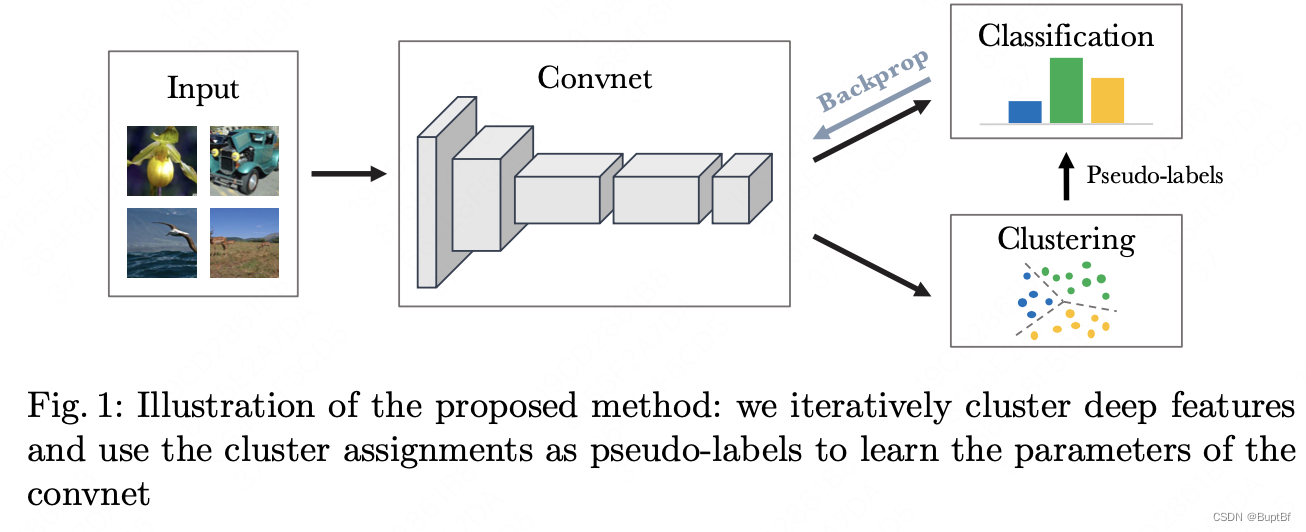
解决方案
使用卷积网络进行特征提取,然后对这些特征进行聚类,之后聚类产生了伪标签,使用这些进行损失回传,这样就能训练特征提取网络,反复进行特征提取聚类和训练,达到最终效果。
其他细节(防止训练崩溃)
Empty clusters.
就是怎么处理空簇,就是出现空簇的时候随机再把自己另外一个非空簇拆成两个,大约逻辑就是把这个簇的簇心,做一个随机扰动,形成一个新的簇心,之后再把这个非空簇分到这个新簇心和老簇心。
More precisely, when a cluster becomes empty, we randomly select a non-empty cluster and use its centroid with a small random perturbation as the new centroid for the empty cluster. We then reassign the points belonging to the non-empty cluster to the two resulting clusters.
Trivial parametrization.
大约就是指这个聚类聚的太密集了,就是特征提取网络没有很好的提取出特征,后面聚类全都聚在一起了,那就没有太大意义了。所以要有惩罚类别的损失设计,在损失回传的时候,样本少的类别的权重要增加,样本多的类别权重要降低,于是就选择样本数的倒数作为损失权重进行回传。
A strategy to circumvent this issue is to sample images based on a uniform distribution over the classes, or pseudo-labels. This is equivalent to weight the contribution of an input to the loss function in Eq. (1) by the inverse of the size of its assigned cluster.