会议:INTERSPEECH 2019
论文:Unsupervised Raw Waveform Representation Learning for ASR
作者:Purvi Agrawal, Sriram Ganapathy
Abstract
在本文中,我们提出了一种在无监督学习范例中使用原始语音波形的深度表示学习方法。提出的深度模型的第一层执行声学滤波,而随后的一层执行调制滤波。使用学习其参数的余弦调制高斯滤波器实现声学滤波器组。调制滤波是在第一层的对数转换后的输出上执行的,这是使用基于跳过连接的体系结构来实现的。来自两层滤波的输出被馈送到变分自动编码器模型。所有模型参数(包括过滤层)均使用VAE成本函数进行学习。我们在语音识别任务中采用学习的表示形式(第二层输出)。在Aurora-4(具有通道伪像的加性噪声)和CHiME-3(具有混响的加性噪声)数据库上进行了实验。在这些实验中,从建议的框架中学习到的表示比基线滤波器组功能和其他强大的前端在ASR结果上有了显着改进(在干净和多条件训练中,单词错误率相对于基线特征平均分别提高了16%和6%) ,分别在Aurora-4数据集上,比CHiME-3数据库的基线特征高21%)。
5. Summary
这项工作的主要贡献如下:
- 提出了具有最初两层卷积的CVAE架构,用于从无监督学习目标的原始波形中进行语音表示学习。
- 卷积的第一层执行声学FB学习,它显示为类似于mel FB的非线性频率分辨率。 在ASR任务中,提出的声学滤波器的性能类似于mel滤波器,并且比以前的无监督FB学习方法有所改进。
- 第二层执行调制滤波。 基于联合声学和调制滤波的功能用于ASR。
- 使用来自建议的CVAE模型的表示,相对于基线特征,多个数据集有了显着改进。
1. Introduction
尽管随着深度神经网络(DNN)的成功,自动语音识别(ASR)系统的性能已得到显着改善,但火车和测试条件不匹配时的性能下降仍然是要克服的挑战性任务[1]。通过获得鲁棒的语音表示可以部分克服它,其中表示不太容易受到噪声和混响的影响。本文着重于鲁棒语音表示的无监督学习方法。
语音处理应用程序的功能主要基于人类听觉处理的属性。对于语音识别功能,传统方法如mel滤波器组和gammatone滤波器组[2,3]近似于人类听力的早期部分。最近,随着神经网络的出现,从数据中学习特征的方法已得到积极的追求[4-6]。在有监督的数据驱动方法中,基础模型可以从原始信号中自动发现手头目标所需的功能,例如检测或分类。像[5,7,8]之类的几项工作专门在网络的初始层中结合了使用卷积层的类似于声学mel滤波器的学习。但是,这些方法高度依赖于标记训练数据的数量。此外,许多先前的工作都使用mel初始化。在本文中,我们假设即使没有标记数据也可以有效地执行表示学习。
在无监督表示学习的先前工作中,使用受限的Boltzmann机器(RBM)得出了声滤波器组[9,10]。这些工作采用了大量可学习的参数(例如,对于使用[10]方法的128个抽头的80个滤波器,使用128×80个参数)。为了克服这个问题,最近的努力引入了参数滤波器学习,例如高斯滤波器[11]和Sinc滤波器[12]。由于自由参数的数量较少,因此参数化方法比标准卷积层具有优势。但是,这些工作也以监督方式对网络进行了训练,以完成ASR的音素分类任务。在本文中,我们提出了一种无监督的参数滤波器学习方法,据我们所知,这是首次尝试。
这项工作直接从原始语音波形中提出了一种深度无监督的表示学习方法。特别地,表示学习作为两层过程进行。首先,使用CVAE中的第一卷积层从原始波形中学习声学滤波器组。我们使用余弦调制的高斯函数作为声学滤波器,以中心频率和带宽为可学习参数,并以随机初始化为起点。在时域中进行卷积,并将该层的输出合并并进行对数转换以获得时频表示。下一层从获得的表示中学习频谱和时间调制滤波器[13]。然后将过滤后的频谱图用作ASR的功能。在Aurora-4(带有通道伪像的加性噪声)和CHiME-3挑战(带有混响的加性噪声)数据库上执行ASR实验。相对于其他各种抗噪声能力强的前端,所提出的方法在WER方面提供了显着的改进。
2. Filterbank learning using CVAE
2.1. Variational Autoencoder (VAE)
2.2. Acoustic filterbank learning
2.3. Modulation filter learning
2.4. Filter characteristics
2.5. Feature extraction for ASR
3. Experiments and results
The speech recognition Kaldi toolkit [19] is used for building the ASR on two datasets, Aurora-4 and CHiME-3 respectively. A deep belief network- deep neural network (DBN-DNN) with 4 hidden layers having 21 frames of input temporal context and a sigmoid nonlinearity is discriminatively trained using the training data and a tri-gram language model is used in the ASR decoding. For each dataset, we compare the ASR performance of the proposed approach of filtered representation (Prop) with traditional mel filterbank energy (MFB) features, power normalized filterbank energy (PFB) features [20], advanced ETSI front-end (ETS) [21], RASTA features (RAS) [22], LDA based features (LDA) [23], and MHEC features (MHE) [24]. In particular, the RASTA features (RAS) and LDA features are included as they both perform modulation filtering in the temporal domain using a knowledge driven filter and a supervised data driven filter, respectively.
3.1. Aurora-4 ASR
WSJ Aurora-4语料库用于进行ASR实验。 该数据库包含5000个单词的语料库的连续读取语音记录,这些记录是在干净和嘈杂的条件下(街道,火车,汽车,汽车,餐馆,飞机场和机场)以SNR 10-20 dB记录的。 训练数据分别具有两组7138干净和多状态记录(84个扬声器)。 验证数据具有两组用于清洁和多条件设置的1206记录。 对于14种清洁和噪声情况,测试数据均具有330条记录(8个扬声器)。 测试数据分为A组-干净数据,B-噪声数据,C-通道失真的清洁数据和D-通道失真的噪声数据。
作为对Aurora-4数据集的初步实验,我们在表1中比较了使用不同声滤波器组获得的时频表示的ASR性能。将拟议模型的声FB层输出(CVAE-Acoustic)与MFB和从CRBM [10]以无监督的方式学习了FB的声学输出。可以观察到,在所有测试条件下,两种训练条件下CVAE声学功能的表现均与MFB功能相似,并且明显优于以前的滤波学习方法。
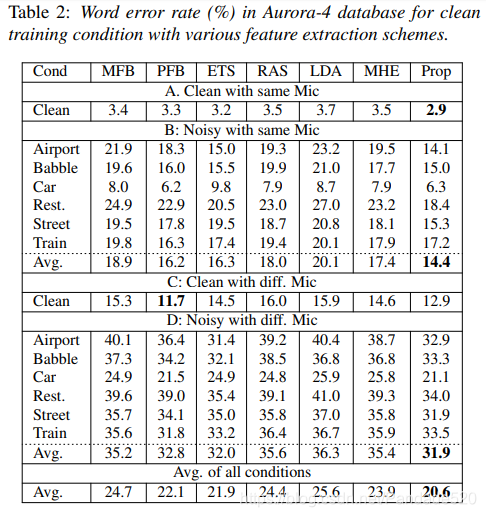
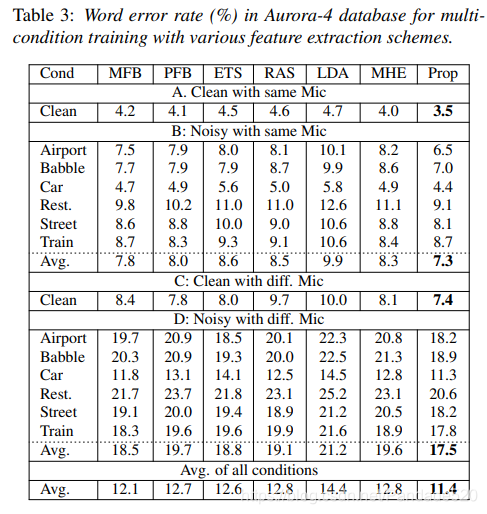
表2和表3分别针对14个测试条件中的每一个,在干净和多条件训练条件下针对提议的(Prop)功能(联合声学和调制滤波)的ASR性能分别示于表2和表3中。还针对不同的噪声条件分别报告了ASR结果。从这些结果中可以看出,在多条件训练中,大多数抗噪能力强的前端并没有超过基线mel滤波器组(MFB)性能。提出的特征提取方案在基线系统上的ASR性能上有了显着的提高(在干净训练中,相对于MFB的平均相对改进为16%,在多条件训练中,平均为6%)。此外,在所有嘈杂的测试条件下,都能始终看到ASR性能的提高。
3.2. CHiME-3 ASR
用于ASR的CHiME-3语料库包含日常环境中的多麦克风平板设备录音,这是第三次CHiME挑战的一部分[25]。 目前存在四种不同的环境,即咖啡馆(CAF),路口(STR),公共交通(BUS)和步行区(PED)。 对于每种环境,存在两种类型的有声语音数据,即真实的和模拟的。 实际数据包括在上述环境中使用的WSJ0语料库的句子的6通道记录。 通过将干净话语与环境噪声人工混合来构建模拟数据。 训练数据具有1600个(实际)噪声记录和7138个模拟噪声说话。 我们将波束成形的音频用于使用CVAE进行滤波器学习,以及用于ASR培训和测试。 开发(开发)和评估(评估)数据分别由410和330语音组成。 对于每个集合,在四个CHiME-3环境中,四个不同的说话者会朗读这些句子。
结果总共有1640个(410×4)和1320个(330×4)真实发声和评价话语。通过将在记录间中捕获的记录与环境噪声记录进行混合,可以创建大小相同的模拟开发和评估集。
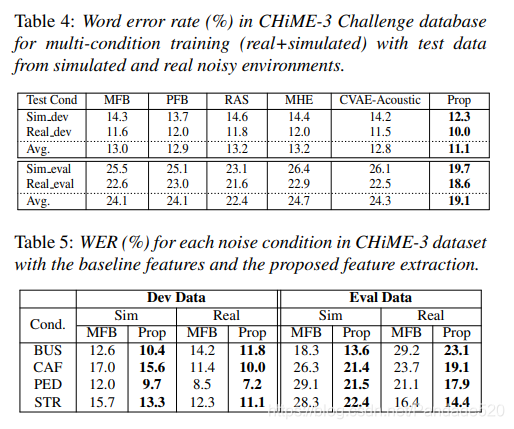
表4中报告了CHiME-3数据集的结果。CVAE-声学功能与ASR中的MFB功能相似。但是,提出的(Prop)特征提取(联合声学和调制滤波)方法相对于基线系统以及此处考虑的其他抗噪能力强的前端提供了显着改进。平均而言,所提出的方法相对于开发集中的MFB功能提供了15%的相对改进,对评估集提供了21%的相对改进。表5中报告了CHiME-3中不同噪声的详细结果。对于在模拟和实际环境中CHiME-3中的所有噪声情况,所提出的方法均显示出比基线MFB功能有显着改善。在评估数据集中,大多数噪声条件在基线特征方面的相对改进都在20%以上。
