文章目录
一、自监督简介
关于自监督部分内容参考Self-supervised Learning 再次入门和知乎微调大佬的回答什么是无监督学习。
1.监督和无监督学习
监督学习利用大量带有标签的数据来训练网络,使得网络能够提取得到丰富的语义特征。
无监督信息不需要标签数据来进行训练,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
2.无监督学习
上面简单描述了监督和无监督学习的定义,但是因为我们常见的主要是监督学习,而无监督学习大部分都是仅仅简单了解到有聚类啥的方法。我认为这是不够的,这里我引用一下知乎大佬的回答:无监督学习就是学习到输入 X X X的更精简的数据表达 Z Z Z,这个新的表示至少符合以下两点要求:
- 足够有效,能够支持下游的其他任务
- 在有效的前提下尽量要小,去除和下游任务无关的冗余信息
换句话说,学习到的表示 Z Z Z要足够小防止冗余,又要足够好能够支持下游的任务。

从这个角度看,有监督学习得到的数据 Z Z Z不如无监督学习到的数据 Z Z Z那么通用,但更适合下游特定的有监督任务。此外,这个大佬还认为广义上的无监督学习只是说你没有一个确定的下游任务,但其实重建误差也算是下游任务,因此或许也能被称为一种“监督学习”。
好了,有了上述的简单介绍,我们便可以了解为啥无监督学习中被广泛使用的方式自动编码器。
编码器将输入的样本映射到隐层向量,解码器将这个隐层向量映射回样本空间。我们期待网络的输入和输出可以保持一致(理想情况,无损重构),同时隐层向量的维度大大小于输入样本的维度,以此达到了降维的目的,利用学习到的隐层向量再进行聚类等任务时将更加的简单高效。对于如何学习隐层向量的研究,可以称之为表征学习(Representation Learning)。但这种简单的编码-解码结构仍然存在很多问题,基于像素的重构损失通常假设每个像素之间都是独立的,从而降低了它们对相关性或复杂结构进行建模的能力。尤其使用 L1 或 L2 损失来衡量输入和输出之间的差距其实是不存在语义信息的,而过分的关注像素级别的细节而忽略了更为重要的语义特征。对于自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。

3.自监督学习
关于自监督学习和无监督学习的关系,这里不做讨论。
简单的定义: 自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
从自监督学习的定义来看,自监督学习难点在于这个辅助任务如何设置,如何评测对于自监督学习到的特征。
- 关于辅助任务的设置,不同的论文提出了不同的方法,比如接下来要介绍的论文就提出了一种简单实用的辅助任务。
- 关于如何测评自监督学习到的特征,具体做法如下:
主要是通过 Pretrain-Fintune 的模式。 我们首先回顾下监督学习中的 Pretrain - Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。而自监督的 Pretrain - Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络,得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。

二、论文内容
0.辅助任务
作者提出了利用训练卷积网络识别对于输入图片的旋转角度来进行提取图像特征,即作为一个辅助任务(pretext)。
简单的说,作者利用卷积网络构建了一个模型,该模型可以用来对输入图像的旋转角度进行分类,旋转角度分为0°、90°、180°、270°。输入进一张经过随机旋转90°整数倍的图片,输出结果为预测出图片旋转角度即对于4个角度的概率值,概率值最高的即为图片的旋转角度。
当得到训练好的辅助任务模型后,作者通过实验比较利用辅助任务的前 K K K层单独拿出来作为上游任务,权重固定保持不变(即进行冻结),下游任务根据具体任务进行搭建网络结构,然后利用监督学习来训练下游任务的模型。
1.出发点
作者为啥设计这样的辅助任务呢?作者在论文中解释道:
- 我们认为,为了让 ConvNet 模型能够识别应用于图像的旋转变换,它需要了解图像中描绘的对象的概念(参见图 1),例如它们在图像中的位置、它们的位置类型和他们的姿势。

作者通过attention map来进行可视化说明。从attention map可以看出作者设计出的辅助任务和监督任务关注的位置是几乎一样的。

此外作者还对比了第一层的滤波器,作者发现自监督任务学习到的滤波器主要是各种频率上的定向边缘滤波器,而且值得注意的是,它们似乎比在监督任务中学习到的滤波器具有更多多样性。

- 与其他几何变换相比,使用图像旋转 90 度的倍数的另一个重要优势是,它们可以通过翻转和转置操作(正如我们将在下面看到的)来实现,不会留下任何容易检测到的低级视觉伪影,这些伪影将引导 ConvNet 学习对视觉感知任务没有实际价值的琐碎特征。相比之下,如果我们决定使用几何变换,例如比例和纵横比图像变换,为了实现它们,我们将需要使用图像大小调整例程,这会留下容易检测到的图像伪影。
- 人类捕获的图像倾向于描绘处于“直立”位置的物体,从而使旋转识别任务得到很好的定义,即给定旋转 0、90、180 或 270 度的图像,通常不会有歧义什么是旋转变换(仅描绘圆形物体的图像除外)。相比之下,对于在人类捕获的图像上变化很大的对象比例,情况并非如此。
2.符号假设
作者要利用卷积网络搭建一个模型,该模型的输入为经过几何变化的图像(几何变化作者选择的是旋转变化),输出是对于这些几何变化的概率值,就像分类一样,最终得到每一个类别的概率值。下面我具体介绍一下用到的符号。
- F ( . ) F(.) F(.)表示模型,其结果为模型输出结果。
- K K K表示几何变化的数量,作者在论文中通过实验选择了4种旋转变化,故 K = 4 K=4 K=4。
- G = { g ( . ∣ y ) } y = 1 K G=\{g(.|y)\}_{y=1}^K G={ g(.∣y)}y=1K, X y = g ( X ∣ y ) X^y=g(X|y) Xy=g(X∣y)这里面的 y y y表示标签,可以理解为对于4种旋转变化的字典映射,比如当 y = 1 y=1 y=1的时候表示旋转 90 ° 90° 90°, G G G表示具体的几何变化集合, g ( . ∣ y ) g(.|y) g(.∣y)表示对于输入进行集合变化,如当 y = 1 y=1 y=1时, X y = 1 = g ( X ∣ y = 1 ) X^{y=1}=g(X|y=1) Xy=1=g(X∣y=1)表示输入的图片 X X X经过旋转 90 ° 90° 90°得到旋转后的图片 X y = 1 X^{y=1} Xy=1。
- F ( X y ∗ ∣ θ ) = { F y ( X y ∗ ∣ θ ) } y = 1 K F(X^{y*}|\theta)=\{F^y(X^{y*}|\theta)\}_{y=1}^K F(Xy∗∣θ)={ Fy(Xy∗∣θ)}y=1K表示输入图片为 X y ∗ X^{y*} Xy∗(其中标签 y ∗ y* y∗对于模型 F ( . ) F(.) F(.)是未知的)产生的结果, F y ( X y ∗ ∣ θ ) F^y(X^{y*}|\theta) Fy(Xy∗∣θ)表示对于类别为 y y y的预测概率, θ \theta θ为模型训练的参数。
- l o s s ( X i , θ ) = − 1 K ∑ y = 1 K l o g ( F y ( g ( X i ∣ y ) ∣ θ ) ) = − 1 K ∑ y = 1 K l o g ( F y ( X y ∣ θ ) ) loss(X_i,\theta)=-\frac{1}{K}\sum_{y=1}^Klog(F^y(g(X_i|y)|\theta))=-\frac{1}{K}\sum_{y=1}^Klog(F^y(X^y|\theta)) loss(Xi,θ)=−K1∑y=1Klog(Fy(g(Xi∣y)∣θ))=−K1∑y=1Klog(Fy(Xy∣θ)),这个为针对输入的图片 X i X_i Xi的损失函数,注意看,这里面用的是 F y F^y Fy,表示对于标签 y y y模型算出来为标签 y y y的概率值。也就是说作者希望正对类别 y y y模型预测的类别概率最大。
- D = { X i } i = 0 N D=\{X_i\}_{i=0}^N D={
Xi}i=0N表示输入图片数量为 N N N的集合,其整体损失函数为 m i n θ 1 N ∑ i = 1 N l o s s ( X i , θ ) min_\theta\frac{1}{N}\sum_{i=1}^Nloss(X_i,\theta) minθN1∑i=1Nloss(Xi,θ)。

3.网络模型
作者设计了两种网络结构,分别是NIN结构和AlexNet网络结构。在接下来的实验中,CIFAR上作者使用了NIN网络,ImageNet上作者使用了AlexNet网络结构。
4.优点
它具有与监督学习相同的计算成本,相似的训练收敛速度(比基于图像重建的方法快得多;我们的 AlexNet 模型使用单个 Titan X GPU 训练大约 2 天),并且可以简单地采用设计的高效并行化方案用于监督学习(Goyal 等人,2017 年),使其成为互联网规模数据(即数十亿张图像)上无监督学习的理想候选者。此外,我们的方法不需要任何特殊的图像预处理程序,以避免像许多其他无监督或自监督方法那样学习琐碎的特征。尽管我们的自监督公式很简单,但正如我们将在本文的实验部分中看到的那样,我们的方法学习的特征在无监督特征学习基准上取得了显着改进。
三、实验结果
1.CIFAR实验
在我们的初步实验中,我们发现在训练期间我们通过同时向网络提供图像的所有四个旋转副本而不是每次随机采样单个旋转变换来训练网络时,我们获得了显着改进。因此,在每个训练批次中,网络看到的图像是批次大小的 4 倍。
a.评估学习到的特征层次结构
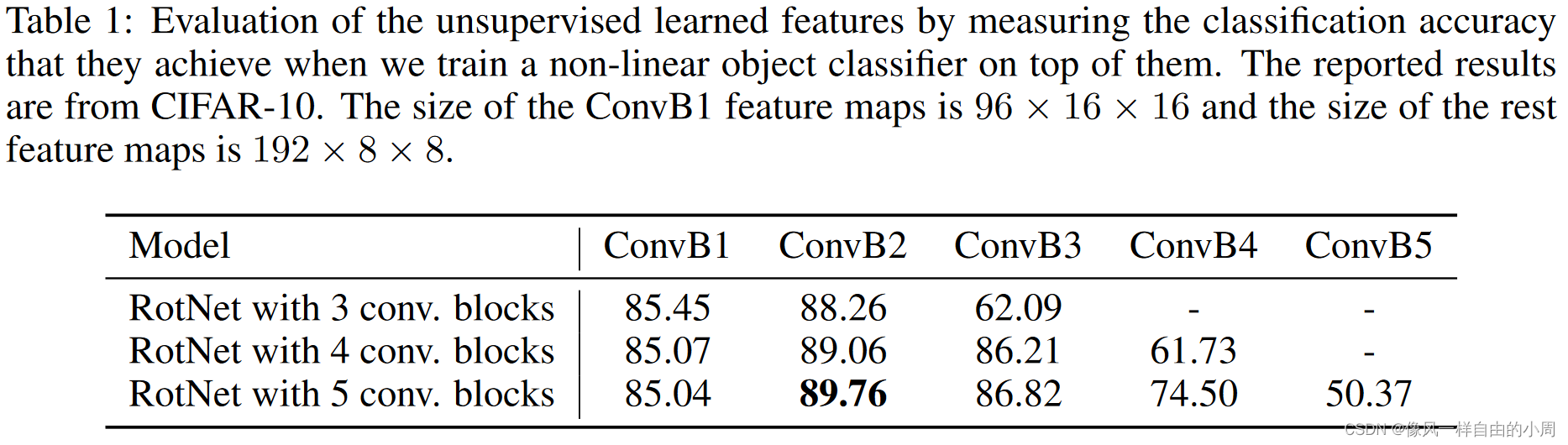
我们假设这是因为它们开始变得越来越具体地用于旋转预测的自我监督任务。此外,我们观察到,增加 RotNet 模型的总深度会导致通过较早层(以及在第一个转换块之后)生成的特征图提高对象识别性能。
b.探讨学习到的特征质量和辅助任务旋转角度之间的关系

c.对比实验

2.在IMageNet上不同任务的实验结果
这里实验结果比较多,就不一一列举了。
a.分类任务

